Deep Improvement Supervision
作者: Arip Asadulaev, Rayan Banerjee, Fakhri Karray, Martin Takac
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-11-21 (更新: 2025-11-28)
💡 一句话要点
提出深度改进监督方法,提升小型循环模型在复杂推理任务中的效率。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 循环神经网络 推理任务 深度监督 训练效率 策略改进
📋 核心要点
- 现有小型循环模型推理效率仍有提升空间,尤其是在复杂推理任务中,需要更高效的训练方法。
- 将TRMs的推理过程视为无分类器引导和隐式策略改进,为每个循环步骤提供明确的训练目标。
- 实验表明,该方法显著提升训练效率,减少前向传播次数,并在ARC-1数据集上取得优异结果。
📝 摘要(中文)
最近的研究表明,诸如Tiny Recursive Models (TRMs)这样的小型循环架构在包括抽象和推理语料库(ARC)在内的复杂推理任务上,可以胜过大型语言模型(LLMs)。本文探讨了一个核心问题:如何在最小的改动下进一步提高这些方法的效率?为了解决这个问题,我们将TRMs的潜在推理过程构建为一种无分类器引导和隐式策略改进算法。基于这些见解,我们提出了一种新颖的训练方案,为训练期间的每个循环提供目标。实验证明,我们的方法显著提高了训练效率,在保持与标准TRMs相当的质量的同时,减少了18倍的总前向传播次数,并消除了停止机制。值得注意的是,我们仅用0.8M参数就在ARC-1上实现了24%的准确率,优于大多数LLMs。
🔬 方法详解
问题定义:论文旨在解决小型循环模型(如TRMs)在复杂推理任务中训练效率低下的问题。现有TRMs虽然在某些任务上表现出色,但训练过程需要大量的计算资源和复杂的停止机制,限制了其应用范围。
核心思路:论文的核心思路是将TRMs的推理过程视为一种隐式的策略改进过程,并借鉴无分类器引导的思想。通过为每个循环步骤提供明确的训练目标,引导模型更快地收敛到最优策略,从而提高训练效率。
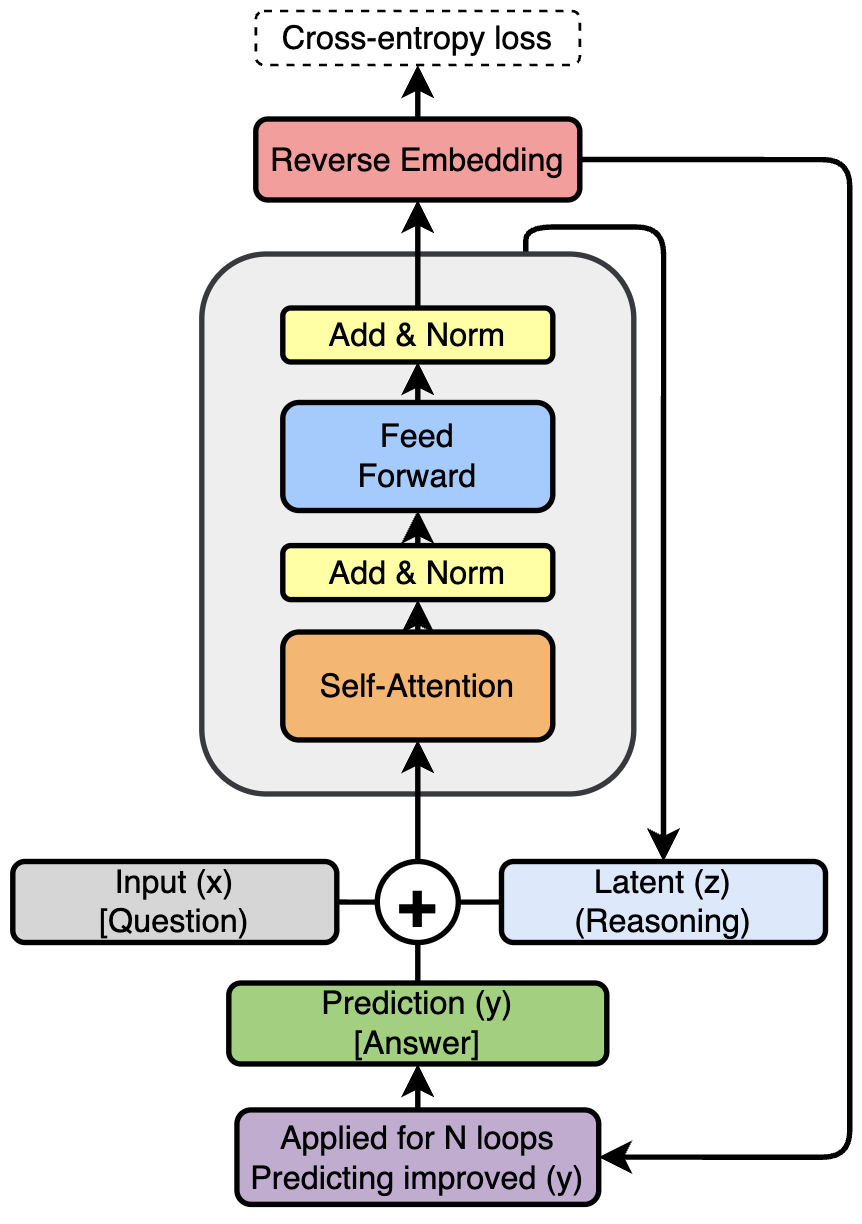
技术框架:该方法的核心是引入“深度改进监督”训练方案。在训练过程中,不仅监督最终的输出结果,还监督每个循环步骤的中间状态。具体来说,对于每个循环,模型都会预测一个目标状态,并计算预测状态与真实状态之间的损失。这种监督信号可以帮助模型更快地学习到正确的推理路径。整体流程包括:输入数据 -> TRM循环推理 -> 每个循环步骤的监督 -> 计算总损失 -> 反向传播更新模型参数。
关键创新:最重要的技术创新点在于对TRMs训练方式的改进,从只监督最终结果转变为监督每个循环步骤的中间状态。这种“深度”监督方式能够提供更丰富的训练信号,引导模型更快地学习到正确的推理策略。与现有方法相比,该方法不需要复杂的停止机制,并且能够显著减少前向传播次数。
关键设计:关键设计包括:1) 为每个循环步骤定义明确的监督目标,通常是中间状态的真实值;2) 使用合适的损失函数来衡量预测状态与真实状态之间的差异,例如均方误差或交叉熵损失;3) 调整每个循环步骤的损失权重,以平衡不同步骤的监督强度;4) 探索不同的TRM架构和循环次数,以找到最佳的性能和效率平衡点。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在ARC-1数据集上取得了显著的性能提升。仅使用0.8M参数的模型,就达到了24%的准确率,优于大多数大型语言模型。同时,该方法还减少了18倍的总前向传播次数,并消除了停止机制,显著提高了训练效率。这些结果表明,深度改进监督是一种有效的TRMs训练方法。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如机器人导航、游戏AI、程序合成等。通过提高小型循环模型的训练效率,可以降低计算成本,使其更容易部署在资源受限的设备上。此外,该方法还可以推广到其他类型的循环神经网络,从而提升其在各种序列建模任务中的性能。
📄 摘要(原文)
Recently, it was shown that small, looped architectures, such as Tiny Recursive Models (TRMs), can outperform Large Language Models (LLMs) on complex reasoning tasks, including the Abstraction and Reasoning Corpus (ARC). In this work, we investigate a core question: how can we further improve the efficiency of these methods with minimal changes? To address this, we frame the latent reasoning of TRMs as a form of classifier-free guidance and implicit policy improvement algorithm. Building on these insights, we propose a novel training scheme that provides a target for each loop during training. We demonstrate that our approach significantly enhances training efficiency. Our method reduces the total number of forward passes by 18x and eliminates halting mechanisms, while maintaining quality comparable to standard TRMs. Notably, we achieve 24% accuracy on ARC-1 with only 0.8M parameters, outperforming most LLMs.