PIRA: Preference-Oriented Instruction-Tuned Reward Models with Dual Aggregation
作者: Yongfu Xue
分类: cs.CL
发布日期: 2025-11-14
💡 一句话要点
PIRA:提出双重聚合的偏好导向指令微调奖励模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 指令微调 人类偏好对齐 大型语言模型 奖励过度优化
📋 核心要点
- 传统奖励模型直接拼接问题和答案,数据效率低,且易受奖励过度优化影响。
- PIRA将问题-答案对转化为偏好指令,聚合多任务奖励,并平均dropout输出以稳定奖励。
- 实验结果表明,PIRA能够有效提升奖励模型的性能,并缓解过度优化问题。
📝 摘要(中文)
奖励模型对于将大型语言模型(LLMs)与人类偏好对齐至关重要,但面临两个典型挑战。首先,传统的判别式奖励模型通常直接连接问题和答案作为输入,导致数据效率低下。其次,奖励模型容易受到奖励过度优化(reward overoptimization)的影响。我们提出了PIRA,一种通过三种策略解决这些问题的训练范式:(1)将问题-答案对重新表述为基于偏好的指令,以实现更清晰和明确的任务规范;(2)聚合来自不同偏好任务的奖励,以减少偏差并提高鲁棒性;(3)在不同的dropout率下平均value-head的输出,以稳定奖励。广泛的实验证明了PIRA的有效性。
🔬 方法详解
问题定义:现有奖励模型在对齐大型语言模型与人类偏好时,存在数据效率低和易受奖励过度优化影响的问题。传统的判别式奖励模型通常将问题和答案直接拼接作为输入,忽略了问题和答案之间的内在联系,导致数据利用率不高。此外,奖励模型容易过度拟合训练数据中的奖励信号,导致在未见数据上的泛化能力下降。
核心思路:PIRA的核心思路是通过将问题-答案对转化为基于偏好的指令,更清晰地表达任务目标,从而提高数据效率。同时,通过聚合来自不同偏好任务的奖励,减少模型对特定任务的偏见,提高模型的鲁棒性。此外,通过在不同dropout率下平均value-head的输出,可以平滑奖励信号,从而稳定奖励并减少过度优化。
技术框架:PIRA的训练框架主要包括三个阶段:指令重构、奖励聚合和dropout平均。首先,将问题-答案对转化为基于偏好的指令,例如“哪个回答更好?”,并构建相应的训练数据集。然后,使用这些指令微调奖励模型,并聚合来自不同偏好任务的奖励信号。最后,在推理阶段,通过在不同的dropout率下多次运行value-head,并平均其输出,得到最终的奖励值。
关键创新:PIRA的关键创新在于其双重聚合策略:一是聚合来自不同偏好任务的奖励,二是平均不同dropout率下的value-head输出。前者可以减少模型对特定任务的偏见,提高鲁棒性;后者可以平滑奖励信号,稳定训练过程,并减少过度优化。此外,将问题-答案对转化为偏好指令,也提高了数据效率。
关键设计:在指令重构阶段,需要设计合适的指令模板,以清晰地表达偏好关系。在奖励聚合阶段,可以采用加权平均或其他聚合方法,根据不同任务的重要性分配权重。在dropout平均阶段,需要选择合适的dropout率范围和平均次数,以平衡奖励的稳定性和准确性。损失函数通常采用pairwise ranking loss,鼓励模型对更符合人类偏好的回答给出更高的奖励。
🖼️ 关键图片

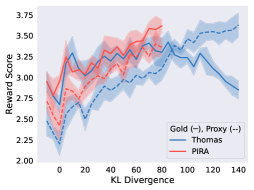
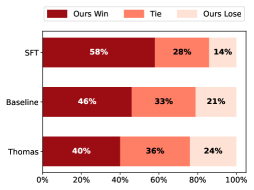
📊 实验亮点
论文通过大量实验验证了PIRA的有效性。实验结果表明,PIRA在多个基准测试中均取得了显著的性能提升,尤其是在缓解奖励过度优化方面表现出色。与传统的奖励模型相比,PIRA能够更好地泛化到未见数据,并生成更符合人类偏好的内容。具体的性能提升数据未知,需要在论文中查找。
🎯 应用场景
PIRA可应用于各种需要对齐人类偏好的大型语言模型应用场景,例如对话系统、文本生成、代码生成等。通过使用PIRA训练的奖励模型,可以更好地引导LLM生成符合人类价值观和偏好的内容,提高用户满意度和信任度。此外,PIRA还可以用于评估不同LLM的性能,并指导模型的改进。
📄 摘要(原文)
Reward models are crucial for aligning Large Language Models (LLMs) with human preferences but face two representative challenges. First, traditional discriminative reward models usually concatenate questions and responses directly as input, resulting in low data efficiency. Second, reward models are vulnerable to reward overoptimization. We propose PIRA, a training paradigm addressing these issues through three strategies: (1) Reformulating question-answer pairs into preference-based instructions for clearer and more explicit task specification, (2) aggregating rewards from diverse preference tasks to reduce bias and improve robustness, and (3) averaging value-head outputs under varying dropout rates to stabilize rewards. Extensive experiments have demonstrated the effectiveness of PIRA.