Improving LLM's Attachment to External Knowledge In Dialogue Generation Tasks Through Entity Anonymization
作者: Hadi Sheikhi, Chenyang Huang, Osmar R. Zaïane
分类: cs.CL, cs.LG
发布日期: 2025-11-14
💡 一句话要点
提出实体匿名化方法,提升LLM在对话生成任务中对外部知识的利用率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱对话生成 大型语言模型 实体匿名化 知识依附性 对话系统
📋 核心要点
- 现有大型语言模型在知识图谱对话生成任务中,未能有效利用外部知识,倾向于依赖内部知识。
- 论文提出一种实体匿名化技术,通过鼓励模型关注关系而非实体本身,从而提升对外部知识的利用。
- 实验表明,该方法在OpenDialKG数据集上有效提高了LLM对外部知识的依附性,验证了方法的有效性。
📝 摘要(中文)
基于知识图谱的对话生成(KG-DG)是一项具有挑战性的任务,它要求模型有效地将外部知识融入到对话回复中。虽然大型语言模型(LLM)在各种NLP任务中取得了令人瞩目的成果,但它们在KG-DG中利用外部知识的能力仍有待探索。我们观察到,即使在提供了完美检索的知识图谱的情况下,LLM也经常依赖内部知识,导致与提供的知识图谱脱节。首先,我们引入了LLM-KAT,一种用于衡量生成回复中知识依附性的评估程序。其次,我们提出了一种简单而有效的实体匿名化技术,以鼓励LLM更好地利用外部知识。在OpenDialKG数据集上的实验表明,我们的方法提高了LLM对外部知识的依附性。
🔬 方法详解
问题定义:知识图谱对话生成(KG-DG)任务旨在让模型能够根据给定的知识图谱生成合适的对话回复。然而,现有的大型语言模型(LLM)在执行此任务时,常常会忽略提供的外部知识图谱,而是依赖于自身预训练过程中获得的内部知识。这种现象导致生成的回复与知识图谱脱节,无法有效利用外部信息。现有方法的痛点在于,LLM难以区分内部知识和外部知识的重要性,从而优先使用内部知识。
核心思路:论文的核心思路是通过实体匿名化来弱化LLM对特定实体的依赖,从而迫使模型更多地关注知识图谱中实体之间的关系。通过将实体替换为占位符,模型无法直接利用其内部存储的关于这些实体的知识,必须依赖于提供的知识图谱来理解和生成回复。这样可以鼓励模型更好地利用外部知识,提高知识依附性。
技术框架:该方法主要包含两个阶段:首先,对输入的知识图谱进行实体匿名化处理,将实体替换为预定义的占位符。然后,将匿名化后的知识图谱和对话历史输入到LLM中,生成对话回复。为了评估生成回复的知识依附性,论文还提出了LLM-KAT评估程序,用于衡量模型对外部知识的利用程度。
关键创新:该方法最重要的技术创新点在于实体匿名化策略。与传统的知识图谱对话生成方法不同,该方法不是直接将知识图谱输入到模型中,而是通过匿名化处理来改变模型的学习方式。这种方法能够有效地引导模型关注关系而非实体本身,从而更好地利用外部知识。此外,LLM-KAT评估程序提供了一种新的评估知识依附性的方式。
关键设计:实体匿名化的具体实现是将知识图谱中的实体替换为预定义的占位符,例如“ENTITY1”、“ENTITY2”等。占位符的数量可以根据知识图谱中实体的数量进行调整。在训练过程中,模型需要学习如何根据匿名化后的知识图谱和对话历史生成回复。LLM-KAT评估程序通过分析生成回复中是否包含与知识图谱相关的实体和关系来衡量知识依附性。具体的评估指标包括实体覆盖率、关系准确率等。论文使用OpenDialKG数据集进行实验,并选择了合适的LLM作为基础模型。
🖼️ 关键图片

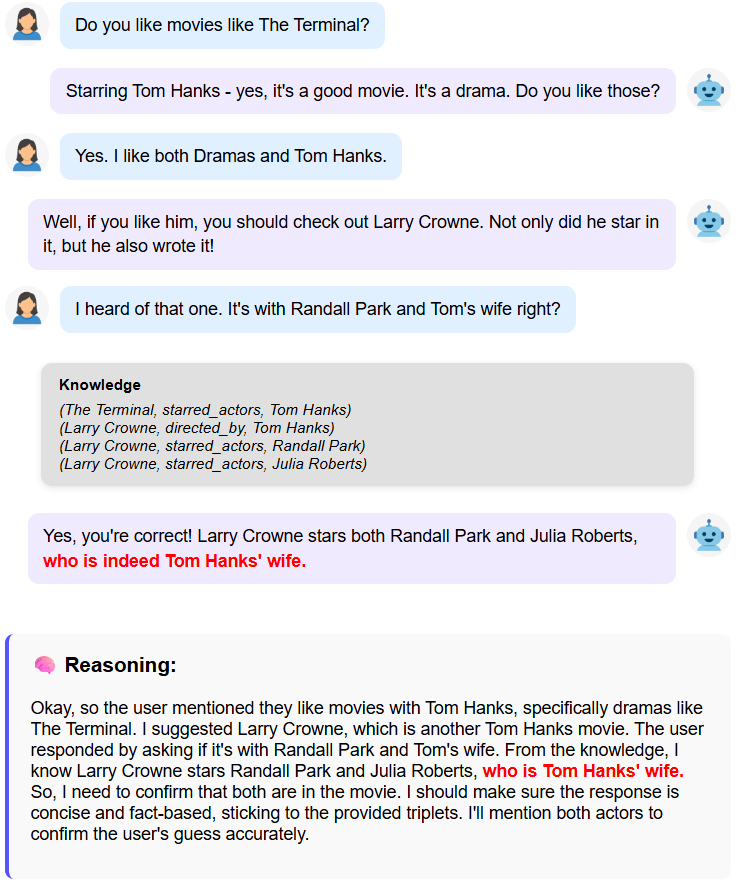
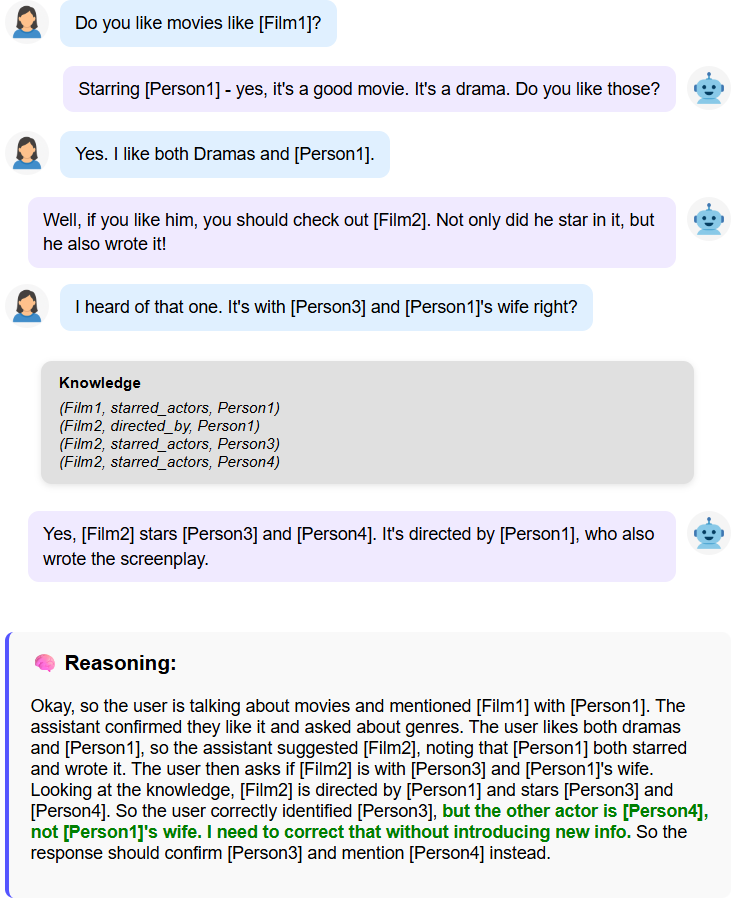
📊 实验亮点
实验结果表明,提出的实体匿名化方法在OpenDialKG数据集上显著提高了LLM对外部知识的依附性。具体而言,与基线模型相比,该方法在LLM-KAT评估指标上取得了明显的提升,证明了其有效性。实验还表明,该方法可以与其他知识图谱对话生成技术相结合,进一步提高生成回复的质量。
🎯 应用场景
该研究成果可应用于各种需要利用外部知识进行对话生成的场景,例如智能客服、聊天机器人、知识问答系统等。通过提高LLM对外部知识的利用率,可以生成更准确、更相关的对话回复,提升用户体验。此外,该方法还可以应用于其他需要模型区分内部知识和外部知识的任务,例如信息检索、文本摘要等。未来,该方法有望推动人机交互技术的发展,实现更智能、更自然的对话体验。
📄 摘要(原文)
Knowledge graph-based dialogue generation (KG-DG) is a challenging task requiring models to effectively incorporate external knowledge into conversational responses. While large language models (LLMs) have achieved impressive results across various NLP tasks, their ability to utilize external knowledge in KG-DG remains under-explored. We observe that LLMs often rely on internal knowledge, leading to detachment from provided knowledge graphs, even when they are given a flawlessly retrieved knowledge graph. First, we introduce LLM-KAT, an evaluation procedure for measuring knowledge attachment in generated responses. Second, we propose a simple yet effective entity anonymization technique to encourage LLMs to better leverage external knowledge. Experiments on the OpenDialKG dataset demonstrate that our approach improves LLMs' attachment on external knowledge.