InData: Towards Secure Multi-Step, Tool-Based Data Analysis
作者: Karthikeyan K, Raghuveer Thirukovalluru, Bhuwan Dhingra, David Edwin Carlson
分类: cs.CL, cs.LG
发布日期: 2025-11-14
💡 一句话要点
InData:面向安全的多步骤、基于工具的数据分析数据集与基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据安全 工具使用 多步骤推理 数据分析 数据集 安全LLM
📋 核心要点
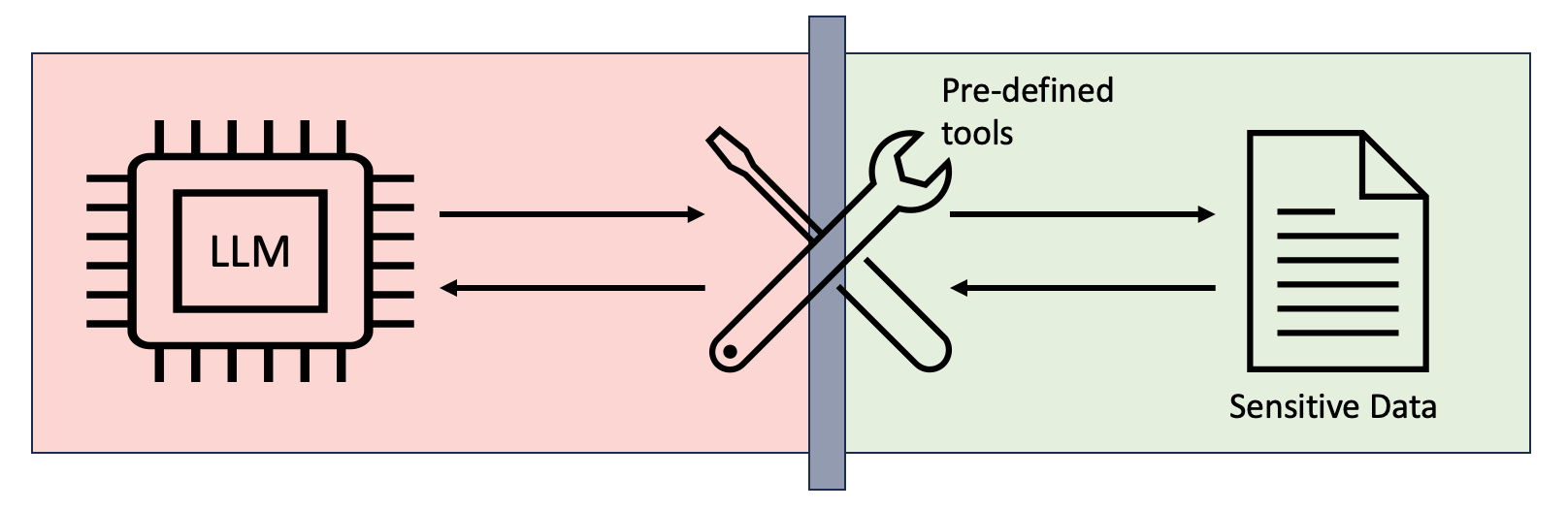
- 现有数据分析大语言模型直接生成代码访问数据库,存在严重的安全隐患,尤其是在处理敏感数据时。
- 论文提出限制LLM直接访问数据,而是通过预定义的安全工具集进行交互,保障数据安全。
- 构建了InData数据集,包含不同难度的数据分析任务,用于评估LLM多步骤、基于工具的推理能力。
📝 摘要(中文)
用于数据分析的大语言模型通常直接在数据库上生成和执行代码,但这种方法在处理敏感数据时存在显著的安全风险。为了解决这个问题,我们提出了一种安全驱动的替代方案:限制LLM直接生成代码和访问数据,要求它们仅通过预定义的安全、经过验证的工具集与数据交互。虽然最近已经存在一些工具使用基准,但它们主要针对工具选择和简单执行,而不是复杂数据分析所需的多步骤组合推理。为了缩小这一差距,我们引入了间接数据交互(InData),这是一个旨在评估LLM多步骤、基于工具的推理能力的数据集。InData包含三个难度级别(简单、中等和困难)的数据分析问题,捕捉了不断增加的推理复杂性。我们在InData上对15个开源LLM进行了基准测试,发现大型模型(例如,gpt-oss-120b)在简单任务上实现了较高的准确率(97.3%),但在困难任务上性能急剧下降(69.6%)。这些结果表明,当前的LLM仍然缺乏强大的多步骤、基于工具的推理能力。通过InData,我们朝着开发和评估具有更强多步骤工具使用能力的LLM迈出了一步。我们将公开发布数据集和代码。
🔬 方法详解
问题定义:现有的大语言模型在进行数据分析时,通常直接生成代码并访问数据库,这在处理敏感数据时会带来严重的安全风险。攻击者可能通过精心设计的提示词,诱导模型泄露或篡改数据。现有的工具使用基准测试主要关注简单的工具选择和执行,缺乏对复杂数据分析所需的多步骤推理能力的评估。
核心思路:论文的核心思路是限制LLM直接访问数据,而是通过预先定义好的、经过安全验证的工具集来间接访问数据。这样可以有效隔离LLM和底层数据,防止恶意代码的执行和敏感数据的泄露。同时,为了评估LLM在这种受限环境下的推理能力,论文构建了一个新的数据集InData。
技术框架:InData数据集包含三个难度级别(简单、中等和困难)的数据分析问题。每个问题都需要LLM通过多个步骤调用不同的工具来完成。LLM接收到问题后,需要首先选择合适的工具,然后根据工具的输入要求构造输入,执行工具,并根据工具的输出结果进行下一步的推理,直到得到最终答案。整个过程模拟了真实世界中数据分析师使用各种工具进行数据分析的流程。
关键创新:论文的关键创新在于提出了一个安全驱动的LLM数据分析框架,该框架通过限制LLM直接访问数据,并引入多步骤、基于工具的推理机制,有效提高了数据安全性,并为LLM在安全环境下的数据分析能力评估提供了一个新的基准。
关键设计:InData数据集的设计考虑了不同难度级别的数据分析任务,包括数据过滤、聚合、排序、统计等常见操作。每个任务都设计成需要多个步骤才能完成,并且每个步骤都需要选择合适的工具和构造正确的输入。数据集还提供了ground truth的工具调用序列和最终答案,方便评估LLM的性能。
🖼️ 关键图片

📊 实验亮点
在InData数据集上的实验结果表明,大型开源LLM(如gpt-oss-120b)在简单任务上表现良好(准确率97.3%),但在困难任务上性能显著下降(准确率69.6%)。这表明当前LLM在多步骤、基于工具的推理能力方面仍有很大的提升空间。InData数据集的发布将有助于推动LLM在安全数据分析领域的研究和应用。
🎯 应用场景
该研究成果可应用于金融、医疗、政务等对数据安全有较高要求的领域。通过限制LLM直接访问敏感数据,并使用安全可信的工具进行数据分析,可以有效降低数据泄露和篡改的风险。未来,该方法有望成为构建安全可信的数据分析系统的关键技术。
📄 摘要(原文)
Large language model agents for data analysis typically generate and execute code directly on databases. However, when applied to sensitive data, this approach poses significant security risks. To address this issue, we propose a security-motivated alternative: restrict LLMs from direct code generation and data access, and require them to interact with data exclusively through a predefined set of secure, verified tools. Although recent tool-use benchmarks exist, they primarily target tool selection and simple execution rather than the compositional, multi-step reasoning needed for complex data analysis. To reduce this gap, we introduce Indirect Data Engagement (InData), a dataset designed to assess LLMs' multi-step tool-based reasoning ability. InData includes data analysis questions at three difficulty levels--Easy, Medium, and Hard--capturing increasing reasoning complexity. We benchmark 15 open-source LLMs on InData and find that while large models (e.g., gpt-oss-120b) achieve high accuracy on Easy tasks (97.3%), performance drops sharply on Hard tasks (69.6%). These results show that current LLMs still lack robust multi-step tool-based reasoning ability. With InData, we take a step toward enabling the development and evaluation of LLMs with stronger multi-step tool-use capabilities. We will publicly release the dataset and code.