Proactive Hearing Assistants that Isolate Egocentric Conversations
作者: Guilin Hu, Malek Itani, Tuochao Chen, Shyamnath Gollakota
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-11-14
备注: Accepted at EMNLP 2025 Main Conference
期刊: In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25377-25394, Suzhou, China. Association for Computational Linguistics
DOI: 10.18653/v1/2025.emnlp-main.1289
💡 一句话要点
提出一种主动式助听设备,无需提示即可隔离佩戴者对话对象
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 主动式助听设备 对话伙伴识别 双耳音频 自言自语锚点 双模型架构
📋 核心要点
- 现有助听设备需要手动设置或依赖外部提示来聚焦特定对话者,无法主动适应复杂对话场景。
- 该论文提出一种基于双耳音频和自言自语锚点的双模型系统,利用对话动态自动识别和隔离对话伙伴。
- 实验结果表明,该系统在真实场景中能够有效识别和隔离对话伙伴,提升了助听设备的实用性。
📝 摘要(中文)
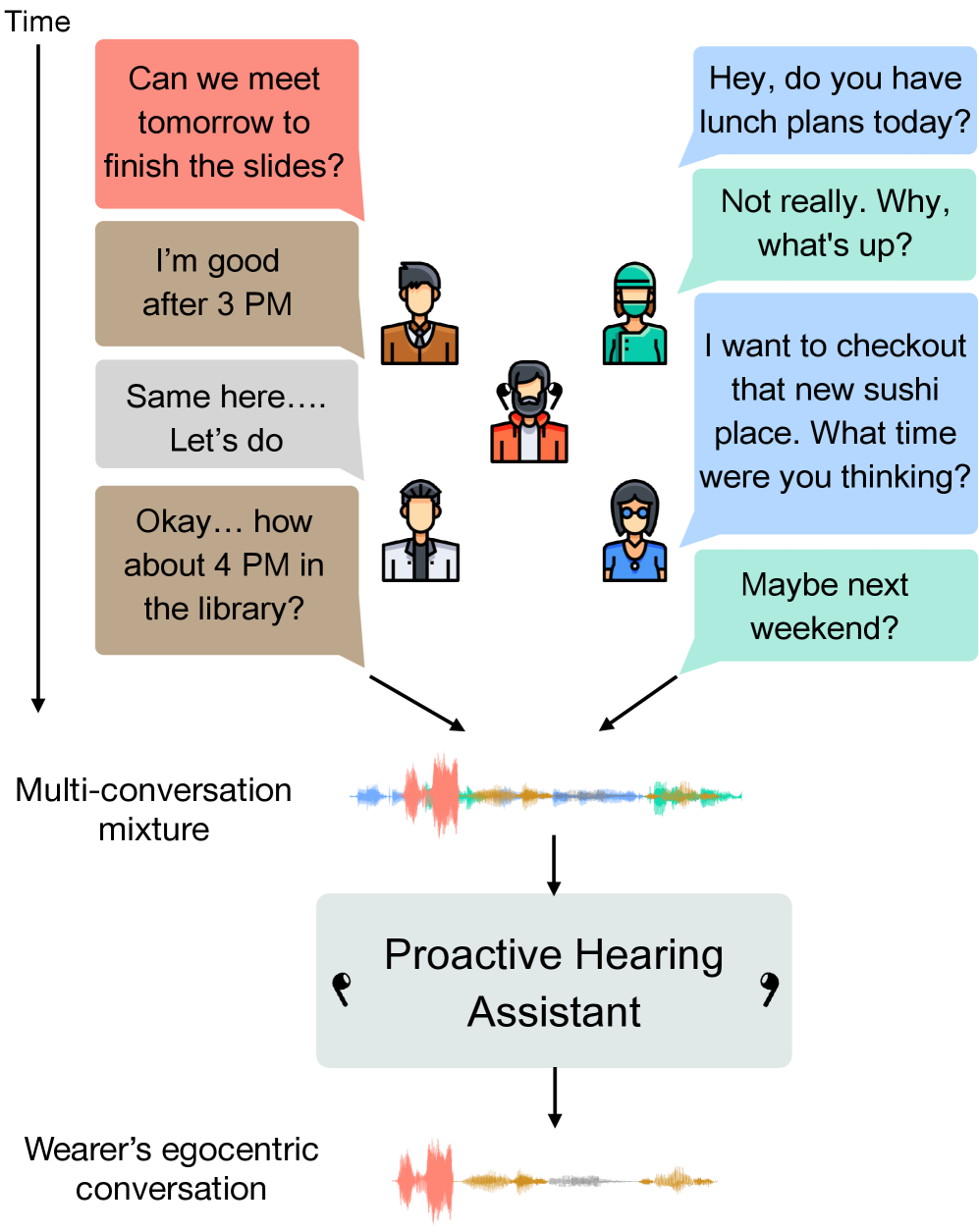
本文提出了一种主动式助听设备,该设备能够自动识别并分离佩戴者的对话伙伴,而无需明确的提示。该系统基于以自我为中心的双耳音频运行,并利用佩戴者的自言自语作为锚点,利用轮流说话行为和对话动态来推断对话伙伴并抑制其他人。为了实现实时、设备端运行,我们提出了一种双模型架构:一个轻量级的流式模型每12.5毫秒运行一次,用于低延迟地提取对话伙伴;而一个较慢的模型运行频率较低,以捕获更长范围的对话动态。在真实世界的2人和3人对话测试集上的结果表明,该系统在多对话环境中识别和隔离对话伙伴方面具有泛化能力。这些数据由11名参与者使用双耳自我中心硬件收集,总时长为6.8小时。我们的工作标志着助听设备朝着主动适应对话动态和参与方向迈出了一步。更多信息请访问我们的网站:https://proactivehearing.cs.washington.edu/
🔬 方法详解
问题定义:现有助听设备在复杂的多人对话场景中,难以自动识别佩戴者想要关注的对话对象。用户需要手动切换或依赖外部提示,操作繁琐且不自然。因此,如何让助听设备主动、智能地识别并隔离目标对话者是亟待解决的问题。
核心思路:该论文的核心思路是利用佩戴者的自言自语作为锚点,结合双耳音频信息和对话动态特征,推断出对话伙伴。自言自语通常与佩戴者关注的对话对象相关联,因此可以作为识别目标对话者的重要线索。同时,对话中的轮流说话行为和长程依赖关系也蕴含着丰富的对话者信息。
技术框架:该系统采用双模型架构,包含一个轻量级的流式模型和一个较慢的长程模型。流式模型每12.5ms运行一次,用于低延迟地提取对话伙伴信息,例如说话人的方位和语音特征。长程模型运行频率较低,用于捕获更长时间范围内的对话动态,例如对话者的角色和话题变化。两个模型协同工作,共同完成对话伙伴的识别和隔离任务。
关键创新:该论文的关键创新在于提出了一种基于自言自语锚点的主动式对话伙伴识别方法。与传统的基于语音活动检测或声源定位的方法不同,该方法充分利用了佩戴者的自言自语信息,提高了对话伙伴识别的准确性和鲁棒性。此外,双模型架构的设计也保证了系统的实时性和性能。
关键设计:流式模型采用轻量级的神经网络结构,例如卷积神经网络或循环神经网络,以保证低延迟。长程模型可以采用Transformer等模型,以捕获长程依赖关系。损失函数的设计需要考虑对话伙伴识别的准确性和鲁棒性,例如可以使用交叉熵损失或对比损失。具体的参数设置需要根据实验结果进行调整。
🖼️ 关键图片


📊 实验亮点
该论文在真实世界的2人和3人对话测试集上进行了评估,数据由11名参与者使用双耳自我中心硬件收集,总时长为6.8小时。实验结果表明,该系统能够有效地识别和隔离对话伙伴,在多对话环境中具有良好的泛化能力。具体的性能指标(例如识别准确率、语音质量提升等)需要在论文中查找。
🎯 应用场景
该研究成果可应用于新一代智能助听设备,帮助听力受损人士在复杂环境中更清晰地听到目标对话者的声音,提升沟通效率和生活质量。此外,该技术还可应用于会议录音、语音助手等领域,实现自动化的发言人识别和语音增强。
📄 摘要(原文)
We introduce proactive hearing assistants that automatically identify and separate the wearer's conversation partners, without requiring explicit prompts. Our system operates on egocentric binaural audio and uses the wearer's self-speech as an anchor, leveraging turn-taking behavior and dialogue dynamics to infer conversational partners and suppress others. To enable real-time, on-device operation, we propose a dual-model architecture: a lightweight streaming model runs every 12.5 ms for low-latency extraction of the conversation partners, while a slower model runs less frequently to capture longer-range conversational dynamics. Results on real-world 2- and 3-speaker conversation test sets, collected with binaural egocentric hardware from 11 participants totaling 6.8 hours, show generalization in identifying and isolating conversational partners in multi-conversation settings. Our work marks a step toward hearing assistants that adapt proactively to conversational dynamics and engagement. More information can be found on our website: https://proactivehearing.cs.washington.edu/