Enhancing Meme Emotion Understanding with Multi-Level Modality Enhancement and Dual-Stage Modal Fusion
作者: Yi Shi, Wenlong Meng, Zhenyuan Guo, Chengkun Wei, Wenzhi Chen
分类: cs.CL, cs.CV
发布日期: 2025-11-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出MemoDetector,通过多层次模态增强和双阶段融合提升Meme情感理解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Meme情感理解 多模态融合 文本增强 多模态大语言模型 双阶段融合
📋 核心要点
- 现有Meme情感理解方法缺乏细粒度的多模态融合策略,且对Meme隐式含义和背景知识挖掘不足。
- 提出MemoDetector框架,利用多模态大语言模型进行文本增强,并采用双阶段模态融合策略。
- 在MET-MEME和MOOD数据集上,MemoDetector的F1分数分别提升了4.3%和3.4%,验证了方法的有效性。
📝 摘要(中文)
随着社交媒体和互联网文化的快速发展,Meme已成为表达情感倾向的流行媒介。这引发了人们对Meme情感理解(MEU)的日益关注,其旨在通过利用Meme的多模态内容来分类其背后的情感意图。虽然现有的研究已经取得了可喜的成果,但仍然存在两个主要挑战:(1)缺乏细粒度的多模态融合策略;(2)对Meme的隐式含义和背景知识挖掘不足。为了应对这些挑战,我们提出了MemoDetector,这是一个用于推进MEU的新框架。首先,我们引入了一个四步文本增强模块,该模块利用多模态大型语言模型(MLLM)的丰富知识和推理能力,逐步推断和提取Meme中的隐式和上下文信息。这些增强的文本显著丰富了原始Meme内容,并为下游分类提供了有价值的指导。接下来,我们设计了一种双阶段模态融合策略:第一阶段对原始Meme图像和文本进行浅层融合,第二阶段深入整合增强的视觉和文本特征。这种分层融合使模型能够更好地捕捉细微的跨模态情感线索。在MET-MEME和MOOD两个数据集上的实验表明,我们的方法始终优于最先进的基线。具体而言,MemoDetector在MET-MEME上将F1分数提高了4.3%,在MOOD上提高了3.4%。进一步的消融研究和深入分析验证了我们方法的有效性和鲁棒性,突出了其在推进MEU方面的强大潜力。
🔬 方法详解
问题定义:论文旨在解决Meme情感理解(MEU)任务中,现有方法缺乏细粒度多模态融合以及对Meme隐式含义和背景知识挖掘不足的问题。现有方法难以充分利用Meme中蕴含的复杂情感信息,导致分类精度不高。
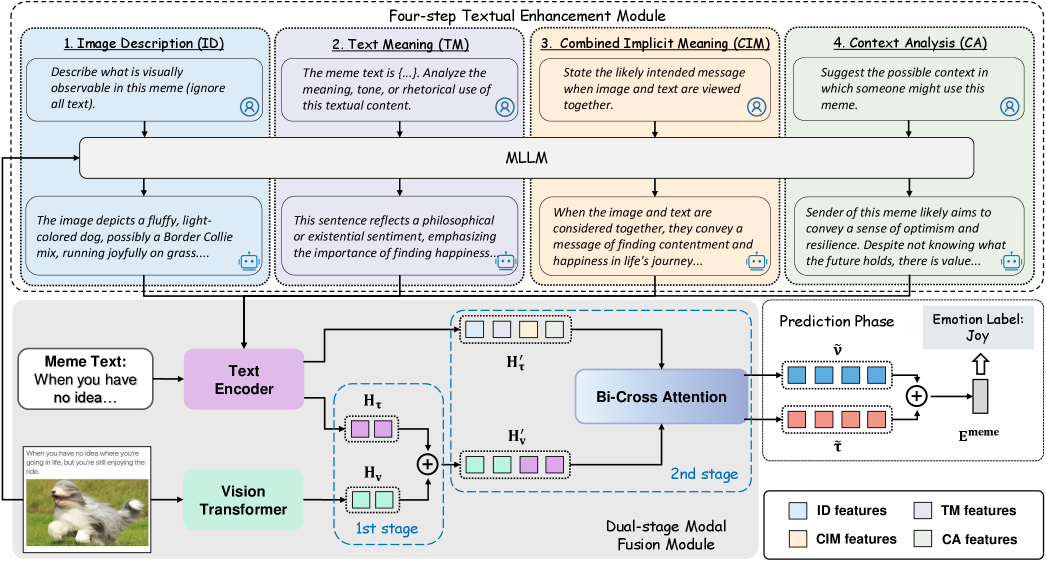
核心思路:论文的核心思路是通过多层次的模态增强和双阶段的模态融合来更全面地理解Meme的情感。首先利用多模态大语言模型(MLLM)增强文本信息,挖掘Meme的隐式含义和背景知识。然后,通过双阶段融合策略,先浅层融合原始模态信息,再深层融合增强后的模态信息,从而更有效地捕捉跨模态情感线索。
技术框架:MemoDetector框架主要包含两个核心模块:文本增强模块和双阶段模态融合模块。文本增强模块利用MLLM进行四步文本增强,包括推断、提取隐式和上下文信息。双阶段模态融合模块首先对原始图像和文本进行浅层融合,然后对增强后的视觉和文本特征进行深层融合。最终,融合后的特征用于情感分类。
关键创新:论文的关键创新在于:(1)提出了基于MLLM的四步文本增强模块,能够有效挖掘Meme的隐式含义和背景知识,显著丰富了原始文本信息。(2)设计了双阶段模态融合策略,能够更好地捕捉细微的跨模态情感线索,提升了情感理解的准确性。与现有方法相比,MemoDetector更注重对Meme深层语义信息的挖掘和利用。
关键设计:文本增强模块使用了特定的MLLM(具体模型未知)进行知识推理和信息提取。双阶段融合的具体网络结构未知,但强调了浅层融合和深层融合的区别。损失函数和优化器等技术细节在论文中未明确说明。
🖼️ 关键图片


📊 实验亮点
MemoDetector在MET-MEME和MOOD两个数据集上进行了实验,结果表明该方法显著优于现有的最先进基线。具体而言,MemoDetector在MET-MEME数据集上将F1分数提高了4.3%,在MOOD数据集上提高了3.4%。消融实验验证了文本增强模块和双阶段模态融合策略的有效性。
🎯 应用场景
该研究成果可应用于社交媒体平台的情感分析、舆情监控、智能推荐等领域。通过准确理解Meme的情感倾向,可以帮助平台更好地识别和过滤不良信息,提升用户体验,并为个性化推荐提供更精准的情感依据。未来,该技术还可扩展到其他多模态情感理解任务中。
📄 摘要(原文)
With the rapid rise of social media and Internet culture, memes have become a popular medium for expressing emotional tendencies. This has sparked growing interest in Meme Emotion Understanding (MEU), which aims to classify the emotional intent behind memes by leveraging their multimodal contents. While existing efforts have achieved promising results, two major challenges remain: (1) a lack of fine-grained multimodal fusion strategies, and (2) insufficient mining of memes' implicit meanings and background knowledge. To address these challenges, we propose MemoDetector, a novel framework for advancing MEU. First, we introduce a four-step textual enhancement module that utilizes the rich knowledge and reasoning capabilities of Multimodal Large Language Models (MLLMs) to progressively infer and extract implicit and contextual insights from memes. These enhanced texts significantly enrich the original meme contents and provide valuable guidance for downstream classification. Next, we design a dual-stage modal fusion strategy: the first stage performs shallow fusion on raw meme image and text, while the second stage deeply integrates the enhanced visual and textual features. This hierarchical fusion enables the model to better capture nuanced cross-modal emotional cues. Experiments on two datasets, MET-MEME and MOOD, demonstrate that our method consistently outperforms state-of-the-art baselines. Specifically, MemoDetector improves F1 scores by 4.3\% on MET-MEME and 3.4\% on MOOD. Further ablation studies and in-depth analyses validate the effectiveness and robustness of our approach, highlighting its strong potential for advancing MEU. Our code is available at https://github.com/singing-cat/MemoDetector.