Analysing Personal Attacks in U.S. Presidential Debates
作者: Ruban Goyal, Rohitash Chandra, Sonit Singh
分类: cs.CL, cs.CY
发布日期: 2025-11-14
备注: 13 pages
💡 一句话要点
提出基于Transformer的框架,用于分析美国总统辩论中的人身攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人身攻击检测 政治辩论分析 Transformer模型 自然语言处理 深度学习
📋 核心要点
- 现有方法难以有效检测政治辩论中微妙的人身攻击,缺乏对语境的深入理解。
- 通过手动标注辩论文本,并微调Transformer模型和通用LLM,实现人身攻击的自动检测。
- 实验结果表明,微调后的Transformer模型能够有效识别政治辩论中的人身攻击,提升了检测精度。
📝 摘要(中文)
人身攻击已成为美国总统辩论的一个显著特征,并在选举期间对公众认知产生重要影响。检测此类攻击可以提高政治讨论的透明度,并为记者、分析师和公众提供见解。深度学习和基于Transformer的模型,特别是BERT和大型语言模型(LLM)的进步,为自动检测有害语言创造了新的机会。受这些发展的推动,我们提出了一个用于分析美国总统辩论中人身攻击的框架。我们的工作包括对2016年、2020年和2024年选举周期的辩论记录进行手动标注,然后进行统计和基于语言模型的分析。我们研究了微调的Transformer模型和通用LLM在检测正式政治演讲中的人身攻击的潜力。这项研究展示了现代语言模型的任务特定适应如何有助于更深入地理解政治沟通。
🔬 方法详解
问题定义:论文旨在解决美国总统辩论中人身攻击的自动检测问题。现有方法在处理政治辩论这种正式且复杂的语境时,往往难以准确识别微妙的人身攻击。此外,缺乏高质量的标注数据也限制了模型的性能。
核心思路:论文的核心思路是利用Transformer模型强大的语义理解能力,通过在手动标注的辩论数据集上进行微调,使模型能够更好地捕捉政治辩论中人身攻击的特征。同时,探索通用LLM在零样本或少样本情况下的表现,评估其在政治语境下的适应性。
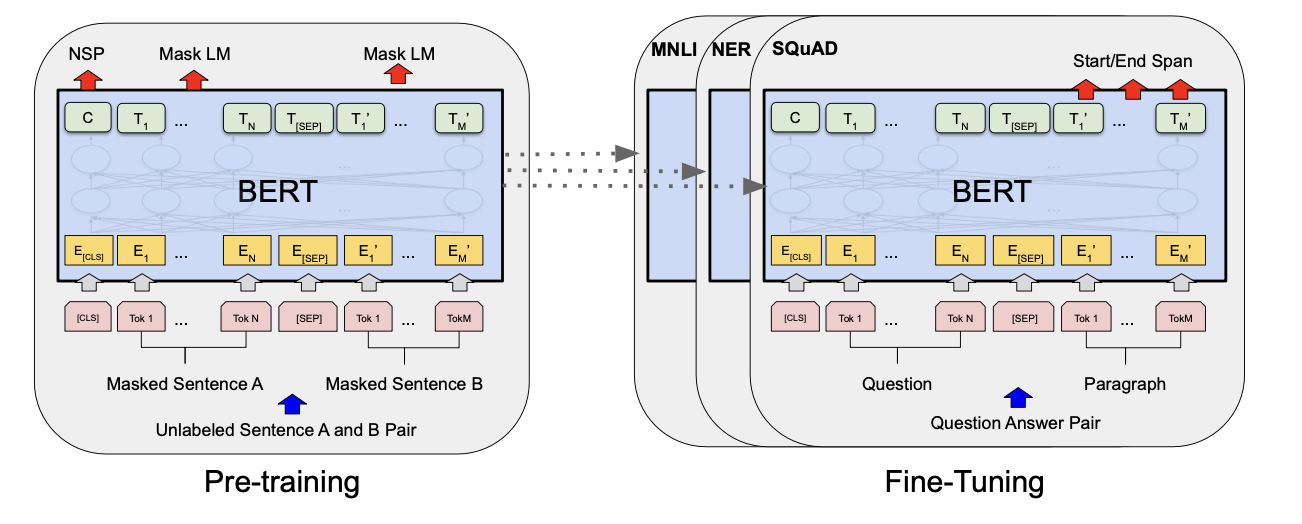
技术框架:该框架主要包含以下几个阶段:1) 数据收集:收集2016年、2020年和2024年美国总统辩论的文字记录。2) 数据标注:人工标注辩论文本,区分人身攻击和非人身攻击言论。3) 模型训练:使用标注数据微调预训练的Transformer模型(如BERT),并评估通用LLM的性能。4) 模型评估:在测试集上评估模型的性能,并进行统计分析。
关键创新:该研究的关键创新在于将Transformer模型应用于政治辩论中人身攻击的检测,并探索了微调策略和通用LLM的潜力。与传统方法相比,Transformer模型能够更好地理解语境和语义,从而提高检测精度。此外,手动标注的数据集为该领域的研究提供了宝贵的资源。
关键设计:论文的关键设计包括:1) 选择合适的预训练Transformer模型作为基础模型。2) 设计有效的微调策略,例如调整学习率、批量大小等超参数。3) 评估不同的通用LLM,并比较其在零样本和少样本情况下的表现。4) 使用标准的评价指标(如精确率、召回率、F1值)评估模型的性能。
🖼️ 关键图片
📊 实验亮点
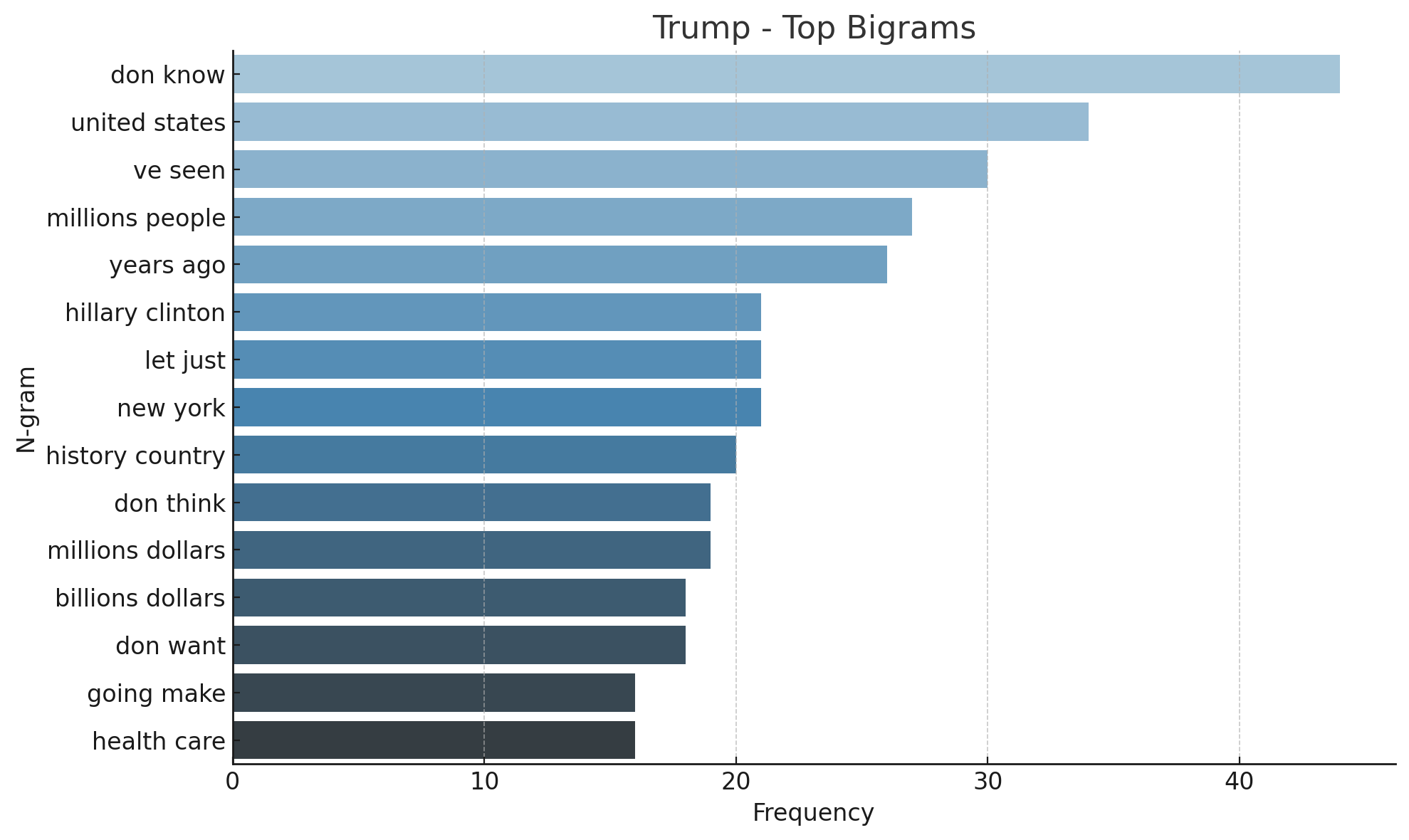
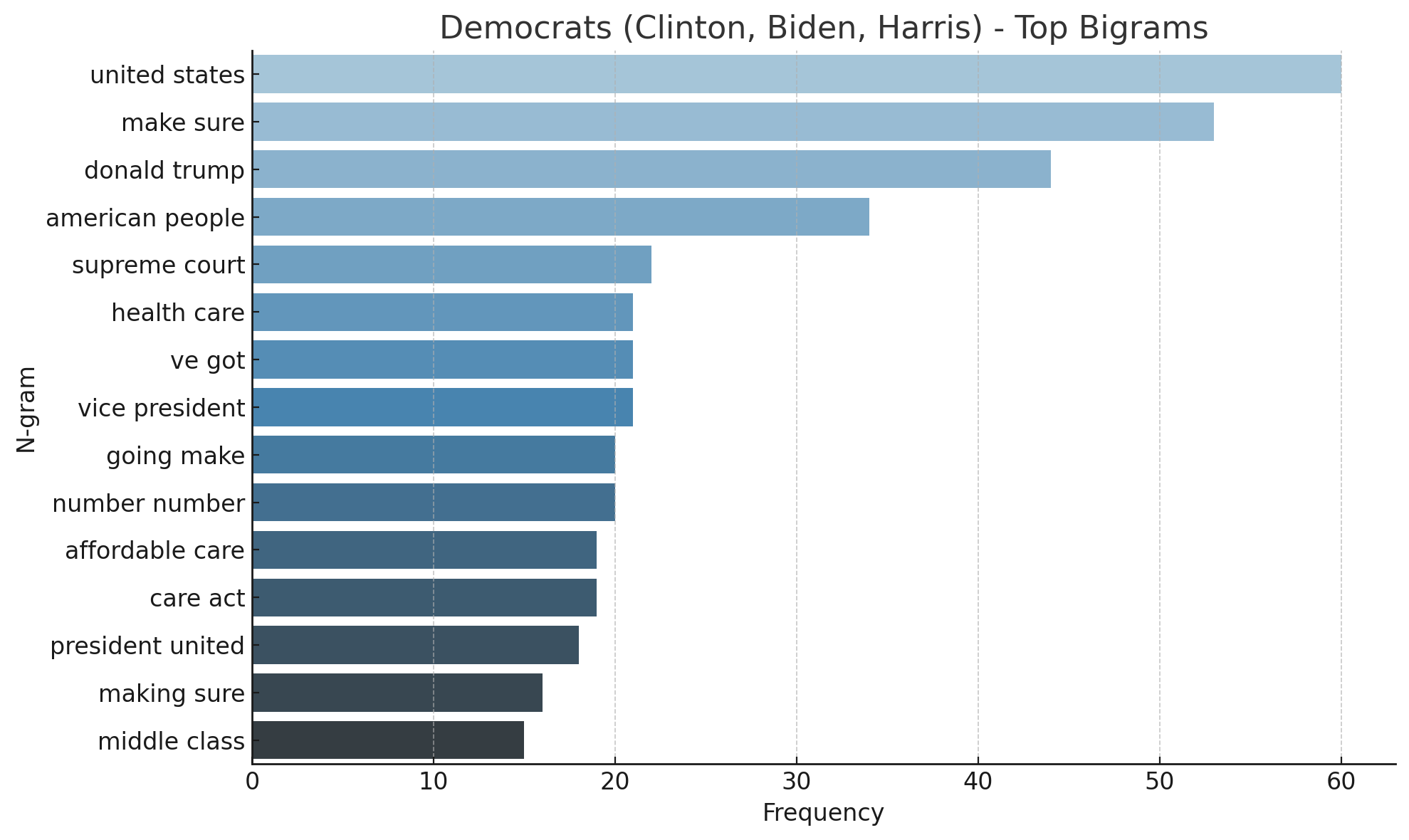
该研究通过在手动标注的美国总统辩论数据集上微调Transformer模型,实现了对人身攻击的有效检测。实验结果表明,微调后的模型在精确率、召回率和F1值等指标上均取得了显著提升,超过了传统的文本分类方法。此外,研究还评估了通用LLM在零样本和少样本情况下的表现,为未来的研究提供了参考。
🎯 应用场景
该研究成果可应用于政治传播分析、舆情监控、新闻报道等领域。通过自动检测政治辩论中的人身攻击,可以提高政治讨论的透明度,帮助公众更好地理解政治家的言论,并为记者和分析师提供有价值的见解。此外,该技术还可以用于检测社交媒体上的网络暴力和恶意攻击。
📄 摘要(原文)
Personal attacks have become a notable feature of U.S. presidential debates and play an important role in shaping public perception during elections. Detecting such attacks can improve transparency in political discourse and provide insights for journalists, analysts and the public. Advances in deep learning and transformer-based models, particularly BERT and large language models (LLMs) have created new opportunities for automated detection of harmful language. Motivated by these developments, we present a framework for analysing personal attacks in U.S. presidential debates. Our work involves manual annotation of debate transcripts across the 2016, 2020 and 2024 election cycles, followed by statistical and language-model based analysis. We investigate the potential of fine-tuned transformer models alongside general-purpose LLMs to detect personal attacks in formal political speech. This study demonstrates how task-specific adaptation of modern language models can contribute to a deeper understanding of political communication.