Expert-Guided Prompting and Retrieval-Augmented Generation for Emergency Medical Service Question Answering
作者: Xueren Ge, Sahil Murtaza, Anthony Cortez, Homa Alemzadeh
分类: cs.CL, cs.AI
发布日期: 2025-11-14 (更新: 2025-11-18)
备注: Accepted by AAAI 2026
💡 一句话要点
提出Expert-CoT和ExpertRAG,解决急救医学问答中领域知识不足的问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 急救医学问答 大型语言模型 专家引导 思维链 检索增强生成 领域知识 临床医学
📋 核心要点
- 现有医学问答方法忽略了临床学科领域和认证级别等领域特定知识,导致在高风险场景下表现受限。
- 论文提出Expert-CoT和ExpertRAG,分别通过专家引导的思维链和检索增强生成来融入领域知识。
- 实验表明,Expert-CoT和ExpertRAG能显著提升LLM在急救医学问答任务上的准确率,并通过了EMS认证模拟考试。
📝 摘要(中文)
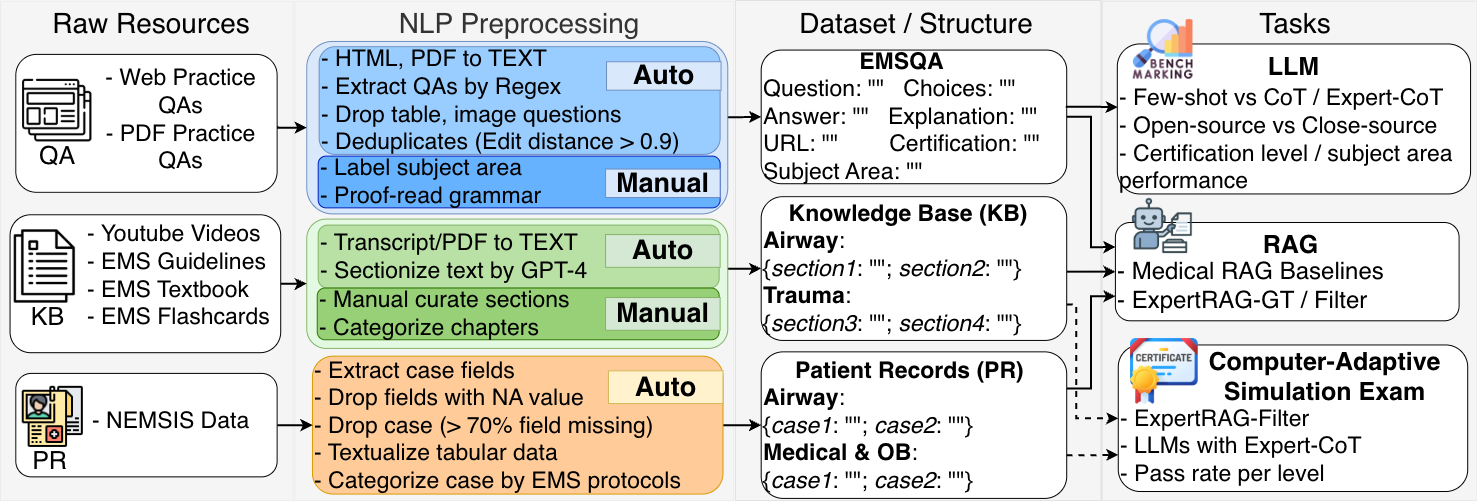
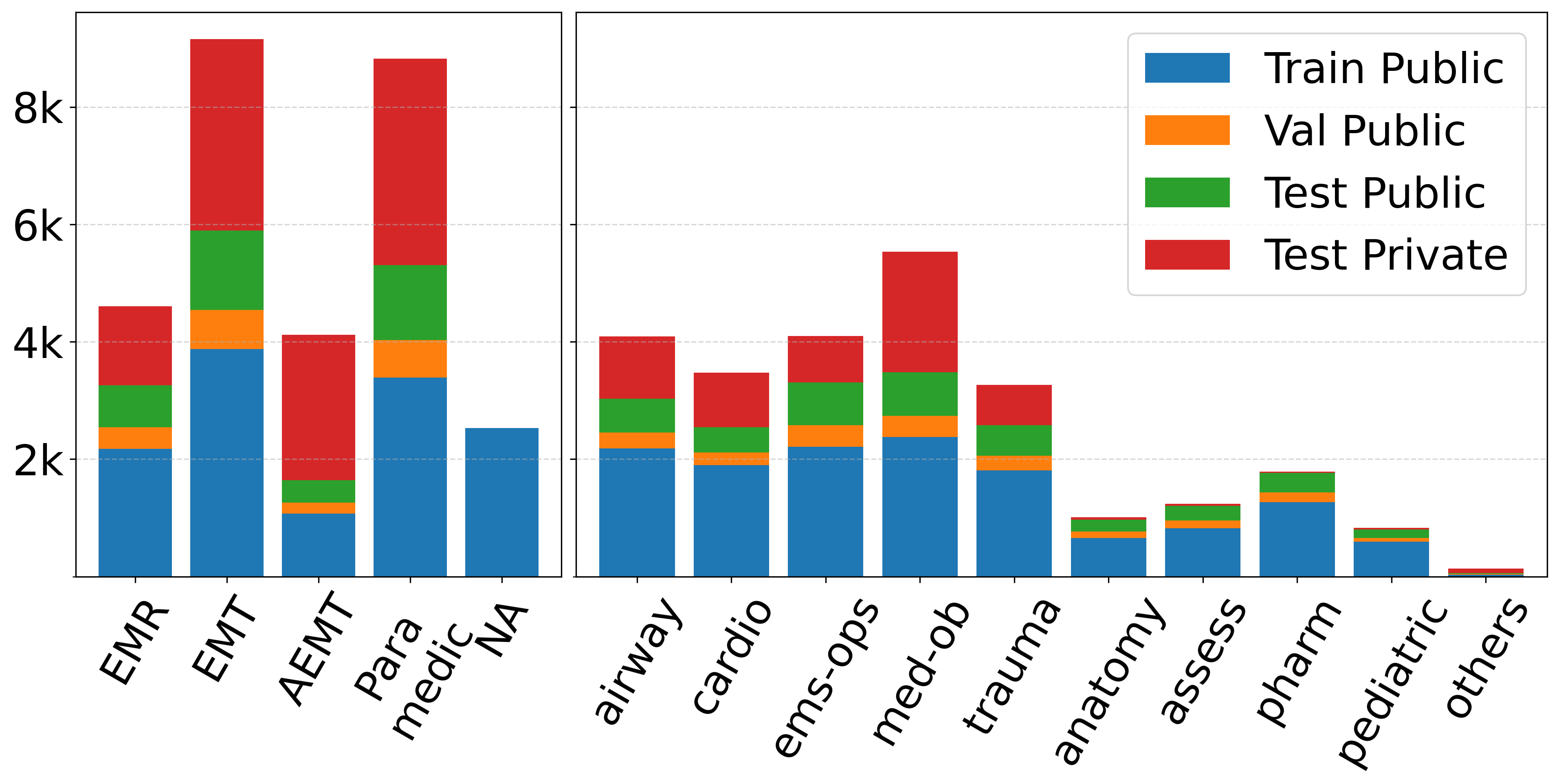
大型语言模型(LLMs)在医学问答方面展现出潜力,但它们常常忽略专业人员依赖的领域特定知识,例如临床学科领域(如创伤、气道)和认证级别(如EMT、护理人员)。现有方法通常应用通用提示或检索策略,而不利用这种结构化上下文,限制了在高风险环境中的性能。我们通过EMSQA来解决这一差距,EMSQA是一个包含2.43万个问题的多项选择题数据集,涵盖10个临床学科领域和4个认证级别,并附带经过整理的、与学科领域对齐的知识库(4万份文档和200万个token)。基于EMSQA,我们引入了(i) Expert-CoT,一种提示策略,它根据特定的临床学科领域和认证级别来调节思维链(CoT)推理,以及(ii) ExpertRAG,一种检索增强生成管道,它将响应建立在与学科领域对齐的文档和真实患者数据的基础上。在4个LLM上的实验表明,Expert-CoT比vanilla CoT提示提高了高达2.05%。此外,将Expert-CoT与ExpertRAG相结合,比标准RAG基线提高了高达4.59%的准确率。值得注意的是,经过专业知识增强的32B LLM通过了所有计算机自适应EMS认证模拟考试。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在急救医学问答任务中,由于缺乏领域特定知识(如临床学科领域和认证级别)而导致的性能瓶颈。现有方法通常采用通用提示或检索策略,无法有效利用这些结构化信息,导致在高风险场景下表现不佳。
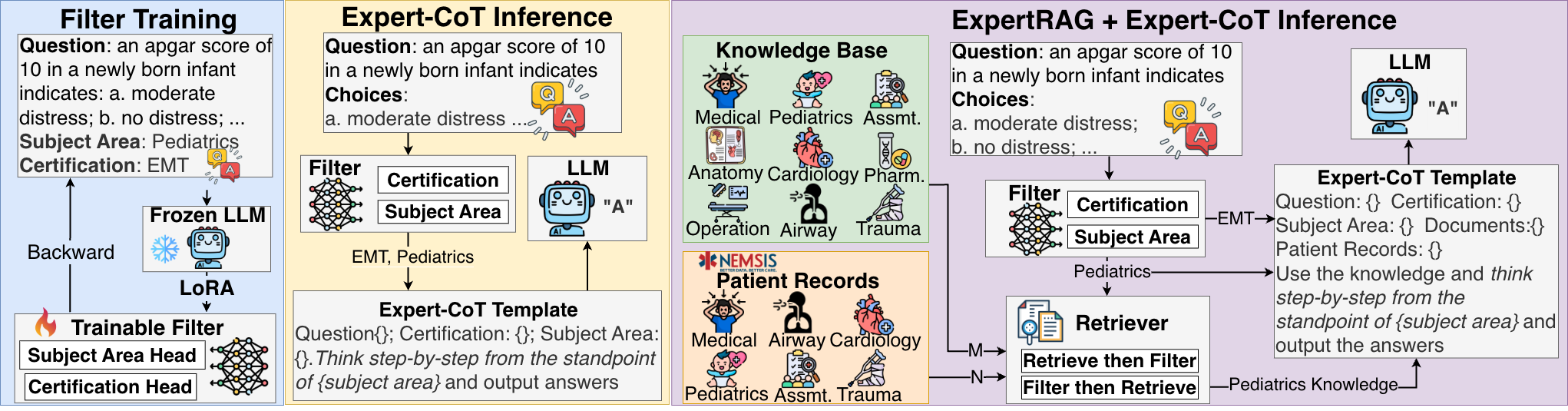
核心思路:论文的核心思路是利用急救医学领域的专家知识,通过两种方式增强LLM的问答能力:一是Expert-CoT,通过在思维链推理过程中引入临床学科领域和认证级别等专家知识进行引导;二是ExpertRAG,通过检索与特定学科领域对齐的文档和真实患者数据,为LLM提供更精准的上下文信息。
技术框架:整体框架包含两个主要模块:Expert-CoT和ExpertRAG。Expert-CoT是一个提示策略,它在标准的Chain-of-Thought (CoT) 提示基础上,增加了对临床学科领域和认证级别的条件约束,引导LLM进行更专业的推理。ExpertRAG是一个检索增强生成管道,它首先根据问题检索相关的学科领域文档和患者数据,然后将检索到的信息作为上下文输入LLM,生成最终答案。
关键创新:论文的关键创新在于将专家知识显式地融入到LLM的提示和检索过程中。Expert-CoT通过专家引导的思维链,使LLM能够模拟专业人员的思考方式。ExpertRAG通过领域对齐的知识库,为LLM提供更精准的上下文信息,避免了通用RAG方法可能引入的噪声。
关键设计:Expert-CoT的关键设计在于如何有效地将临床学科领域和认证级别信息融入到CoT提示中。具体实现方式未知,但推测可能是在提示语中加入相关的描述或指令。ExpertRAG的关键设计在于如何构建和维护领域对齐的知识库,以及如何根据问题进行高效的检索。知识库包含4万份文档和200万个token,检索算法未知,但需要保证检索结果与问题的学科领域高度相关。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Expert-CoT比vanilla CoT提示提高了高达2.05%的准确率。将Expert-CoT与ExpertRAG相结合,比标准RAG基线提高了高达4.59%的准确率。更重要的是,经过专业知识增强的32B LLM通过了所有计算机自适应EMS认证模拟考试,证明了该方法在实际应用中的有效性。
🎯 应用场景
该研究成果可应用于开发智能急救医学问答系统,辅助医护人员进行决策,提高急救效率和准确性。此外,该方法也可推广到其他专业领域,例如法律、金融等,通过引入领域专家知识来提升LLM的专业能力。未来,该研究有望推动LLM在医疗健康领域的更广泛应用,例如辅助诊断、个性化治疗等。
📄 摘要(原文)
Large language models (LLMs) have shown promise in medical question answering, yet they often overlook the domain-specific expertise that professionals depend on, such as the clinical subject areas (e.g., trauma, airway) and the certification level (e.g., EMT, Paramedic). Existing approaches typically apply general-purpose prompting or retrieval strategies without leveraging this structured context, limiting performance in high-stakes settings. We address this gap with EMSQA, an 24.3K-question multiple-choice dataset spanning 10 clinical subject areas and 4 certification levels, accompanied by curated, subject area-aligned knowledge bases (40K documents and 2M tokens). Building on EMSQA, we introduce (i) Expert-CoT, a prompting strategy that conditions chain-of-thought (CoT) reasoning on specific clinical subject area and certification level, and (ii) ExpertRAG, a retrieval-augmented generation pipeline that grounds responses in subject area-aligned documents and real-world patient data. Experiments on 4 LLMs show that Expert-CoT improves up to 2.05% over vanilla CoT prompting. Additionally, combining Expert-CoT with ExpertRAG yields up to a 4.59% accuracy gain over standard RAG baselines. Notably, the 32B expertise-augmented LLMs pass all the computer-adaptive EMS certification simulation exams.