From Proof to Program: Characterizing Tool-Induced Reasoning Hallucinations in Large Language Models
作者: Farima Fatahi Bayat, Pouya Pezeshkpour, Estevam Hruschka
分类: cs.CL, cs.LO, cs.SE
发布日期: 2025-11-14
备注: 19 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
揭示工具增强语言模型中的工具诱导推理短视问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具增强语言模型 推理短视 代码解释器 偏好优化 推理评估 数学问题 可信AI
📋 核心要点
- 现有工具增强语言模型(TaLMs)过度依赖工具输出,缺乏连贯的推理过程,导致“工具诱导短视(TIM)”问题。
- 提出多维度评估套件,量化TaLMs相对于非工具模型的推理能力下降,揭示工具使用频率与推理质量之间的负相关性。
- 提出基于偏好优化的框架,引导TaLMs将工具作为辅助证据,从而提升最终答案准确性和推理深度。
📝 摘要(中文)
工具增强语言模型(TaLMs)可以调用外部工具来解决超出其参数能力的问题。然而,这些工具带来的收益是否反映了可信的推理仍然不清楚。本文以代码解释器工具为例,表明即使工具被正确选择和执行,TaLMs也会将工具输出视为推理的替代品,产生看似正确但缺乏连贯论证的解决方案。我们将这种失效模式称为工具诱导短视(TIM),并使用PYMATH对其进行研究,PYMATH是一个包含1679个竞赛级数学问题的基准,Python代码对此有所帮助但并非充分条件。我们进一步开发了一个多维度评估套件,以量化TaLMs相对于非工具模型的推理能力下降。研究结果表明,虽然TaLMs在最终答案准确率上提高了高达19.3个百分点,但它们的推理行为持续恶化(例如,在推理过程的成对比较中,非工具LLMs的胜率高出41.5%)。这种退化随着工具的使用而加剧;模型调用工具的频率越高,其推理就越不连贯。此外,工具的使用将错误从算术错误转移到全局推理失败(逻辑、假设、创造力);TIM存在于约55%的高风险案例中。最后,我们提出了一个基于偏好优化的框架,该框架重新调整TaLMs,使其将工具用作辅助证据,从而提高工具使用下的最终答案准确性和推理深度。代码和数据可在https://github.com/megagonlabs/TIM获取。
🔬 方法详解
问题定义:论文旨在解决工具增强语言模型(TaLMs)中存在的“工具诱导短视(TIM)”问题。现有TaLMs过度依赖外部工具的输出,将其作为推理的替代品,导致推理过程不连贯,即使最终答案正确,也缺乏合理的解释。这种现象在高风险场景下尤为突出,严重影响了TaLMs的可信度。
核心思路:论文的核心思路是重新调整TaLMs对工具的使用方式,使其将工具视为辅助证据,而非推理的替代品。通过鼓励模型在利用工具的同时,保持清晰、连贯的推理过程,从而缓解TIM问题,提升模型的整体性能和可信度。
技术框架:论文的技术框架主要包含三个部分:1) 定义并量化TIM问题;2) 开发多维度评估套件,用于评估TaLMs的推理能力;3) 提出基于偏好优化的框架,用于重新调整TaLMs对工具的使用方式。评估套件包含多个指标,用于衡量模型的推理深度、连贯性和准确性。偏好优化框架则通过奖励模型在工具使用过程中展现出的良好推理行为,从而引导模型学习更合理的工具使用策略。
关键创新:论文的关键创新在于:1) 首次明确提出了“工具诱导短视(TIM)”这一概念,并对其进行了深入分析;2) 开发了多维度评估套件,能够全面评估TaLMs的推理能力,为后续研究提供了有效的评估工具;3) 提出了基于偏好优化的框架,能够有效缓解TIM问题,提升模型的整体性能。
关键设计:论文中,偏好优化框架的关键设计在于奖励函数的设计。奖励函数旨在鼓励模型在工具使用过程中展现出良好的推理行为,例如,提供清晰的推理步骤、避免过度依赖工具输出等。具体的奖励函数形式未知,但其核心思想是引导模型学习更合理的工具使用策略,从而缓解TIM问题。
🖼️ 关键图片


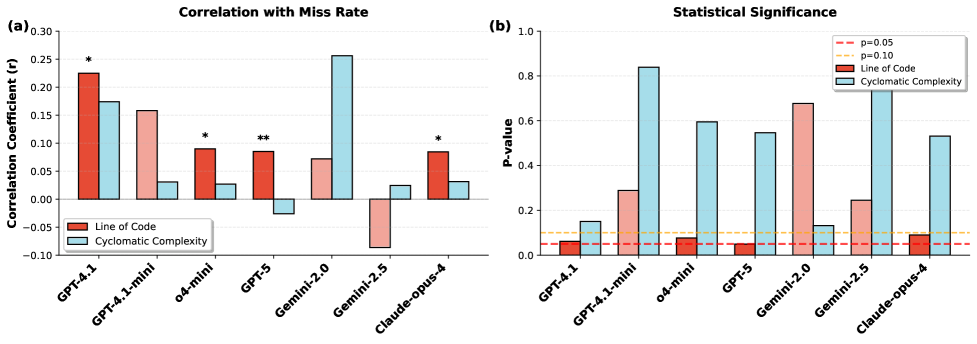
📊 实验亮点
实验结果表明,虽然TaLMs在最终答案准确率上提高了高达19.3个百分点,但其推理行为却持续恶化,非工具LLMs在推理过程的成对比较中胜率高出41.5%。此外,TIM存在于约55%的高风险案例中。通过提出的偏好优化框架,可以有效缓解TIM问题,提升模型的整体性能。
🎯 应用场景
该研究成果可应用于需要高度可信推理的领域,例如医疗诊断、金融分析、法律咨询等。通过缓解工具诱导的推理短视问题,可以提升AI系统在这些领域的可靠性和安全性,使其能够更好地辅助人类进行决策。
📄 摘要(原文)
Tool-augmented Language Models (TaLMs) can invoke external tools to solve problems beyond their parametric capacity. However, it remains unclear whether these tool-enabled gains reflect trustworthy reasoning. Focusing on the Code Interpreter tool, we show that even when tools are selected and executed correctly, TaLMs treat tool outputs as substitutes for reasoning, producing solutions that appear correct but lack coherent justification. We term this failure mode Tool-Induced Myopia (TIM), and study it using PYMATH, a benchmark of 1,679 competition-level mathematical problems for which Python code is helpful but not sufficient. We further develop a multi-dimensional evaluation suite to quantify reasoning degradation in TaLMs relative to their non-tool counterparts. Our findings reveal that while TaLMs achieve up to a 19.3 percentage point gain in final-answer accuracy, their reasoning behavior consistently deteriorates (e.g., non-tool LLMs win up to 41.5% more often in pairwise comparisons of the reasoning process). This degradation intensifies with tool use; the more frequently a model invokes tools, the less coherent its reasoning becomes. Moreover, tool use shifts errors from arithmetic mistakes toward global reasoning failures (logic, assumption, creativity); with TIM present in ~55% of high-risk cases. Finally, we propose a preference-optimization-based framework that realigns TaLMs to use tools as assistive evidence, improving both final-answer accuracy and reasoning depth under tool use. Codes and data are available at: https://github.com/megagonlabs/TIM.