Evaluating LLM Understanding via Structured Tabular Decision Simulations
作者: Sichao Li, Xinyue Xu, Xiaomeng Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-11-07
💡 一句话要点
提出结构化表格决策模拟以评估LLM理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 理解能力 决策模拟 评估方法 多领域应用
📋 核心要点
- 现有的LLM评估方法主要关注准确性,缺乏对模型理解能力的全面评估。
- 本文提出STaDS,通过模拟专家决策场景,评估LLMs在多领域中的理解和决策能力。
- 实验结果显示,大多数模型在多样化决策场景中表现不佳,且存在准确性与理解能力之间的矛盾。
📝 摘要(中文)
大型语言模型(LLMs)虽然在预测准确性上表现出色,但仅有准确性并不意味着真正的理解。真正的LLM理解类似于人类专家,需要在多个实例和不同领域中做出一致且有根据的决策,依赖于相关的领域决策因素。本文提出了结构化表格决策模拟(STaDS),这是一个专家级决策评估工具,旨在评估LLMs在结构化决策“考试”中的表现。理解在此被定义为识别和依赖正确决策因素的能力。通过分析9个前沿LLM在15个不同决策设置下的表现,发现大多数模型在多样化领域中难以保持一致的高准确性,且模型可能准确但整体不忠实,常常存在陈述的理由与驱动预测的因素之间的错位。研究强调了全球理解评估协议的必要性,并倡导超越准确性的创新框架,以增强LLMs的理解能力。
🔬 方法详解
问题定义:本文旨在解决现有LLM评估方法无法全面反映模型理解能力的问题。现有方法主要关注预测准确性,忽视了模型在不同领域中的一致性和决策依据的合理性。
核心思路:论文提出的STaDS通过模拟专家决策场景,评估LLMs在理解问题、知识预测和决策因素依赖等方面的能力。这种设计旨在更真实地反映模型的理解水平。
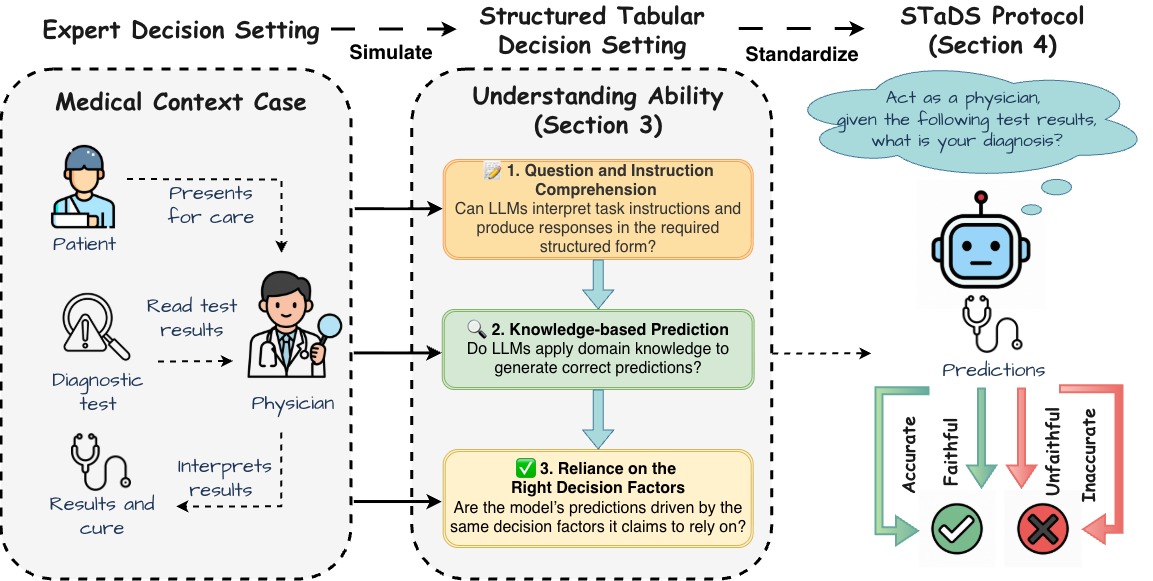
技术框架:STaDS框架包括三个主要模块:问题和指令理解、基于知识的预测,以及对相关决策因素的依赖。通过这三个模块的综合评估,能够全面考察LLMs的理解能力。
关键创新:最重要的创新在于将理解定义为识别和依赖正确决策因素的能力,超越了传统的准确性评估,提供了一种新的评估视角。
关键设计:在实验中,设计了15个不同的决策设置,涵盖多样化领域,并对9个前沿LLM进行了评估。关键参数设置包括决策因素的选择和模型的输出解释,确保了评估的有效性和可靠性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,大多数LLM在15个决策设置中的表现不尽如人意,准确性与理解能力之间存在显著差距。具体而言,模型在某些领域的准确率高达80%,但在其他领域却低至50%,显示出模型在多样化决策场景中的不一致性。
🎯 应用场景
该研究的潜在应用领域包括教育、医疗、金融等需要复杂决策支持的行业。通过提升LLMs的理解能力,可以在这些领域中实现更高效的决策支持和智能化服务,未来可能推动相关技术的广泛应用。
📄 摘要(原文)
Large language models (LLMs) often achieve impressive predictive accuracy, yet correctness alone does not imply genuine understanding. True LLM understanding, analogous to human expertise, requires making consistent, well-founded decisions across multiple instances and diverse domains, relying on relevant and domain-grounded decision factors. We introduce Structured Tabular Decision Simulations (STaDS), a suite of expert-like decision settings that evaluate LLMs as if they were professionals undertaking structured decision ``exams''. In this context, understanding is defined as the ability to identify and rely on the correct decision factors, features that determine outcomes within a domain. STaDS jointly assesses understanding through: (i) question and instruction comprehension, (ii) knowledge-based prediction, and (iii) reliance on relevant decision factors. By analyzing 9 frontier LLMs across 15 diverse decision settings, we find that (a) most models struggle to achieve consistently strong accuracy across diverse domains; (b) models can be accurate yet globally unfaithful, and there are frequent mismatches between stated rationales and factors driving predictions. Our findings highlight the need for global-level understanding evaluation protocols and advocate for novel frameworks that go beyond accuracy to enhance LLMs' understanding ability.