Steering Language Models with Weight Arithmetic
作者: Constanza Fierro, Fabien Roger
分类: cs.CL, cs.LG
发布日期: 2025-11-07
💡 一句话要点
提出基于权重运算的语言模型引导方法,提升模型行为控制能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 权重引导 行为控制 模型安全 分布外泛化
📋 核心要点
- 现有LLM难以获得高质量反馈,且易在特定分布上产生意外泛化,限制了模型行为控制。
- 提出对比权重引导方法,通过权重运算在权重空间中隔离并操控行为方向。
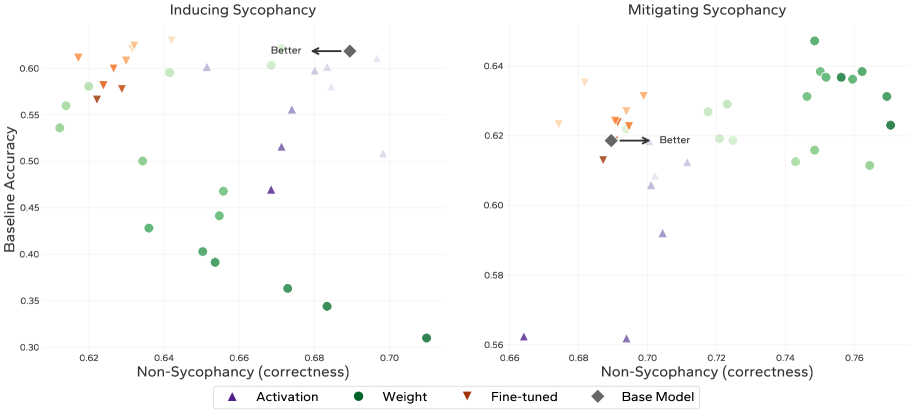
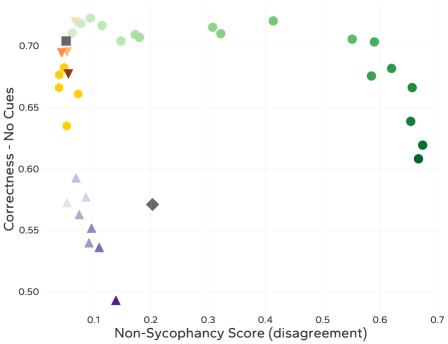
- 实验表明,该方法能有效缓解谄媚行为、诱导不一致,并减轻微调带来的不良行为漂移。
📝 摘要(中文)
为解决大型语言模型(LLM)在多样化训练分布上获取高质量反馈困难且昂贵的问题,以及在狭窄分布上训练导致意外泛化的问题,本文提出了一种对比权重引导方法,这是一种简单的后训练方法,通过权重运算编辑模型参数。该方法通过从两个小规模微调中减去权重变化来隔离权重空间中的行为方向——一个诱导期望行为,另一个诱导相反行为——然后添加或删除此方向以修改模型的权重。我们将此技术应用于缓解谄媚行为和诱导不一致行为,发现权重引导通常比激活引导具有更强的泛化能力,在降低一般能力之前实现更强的分布外行为控制。我们还表明,在特定任务微调的背景下,权重引导可以部分缓解不需要的行为漂移:它可以减少微调过程中引入的谄媚和拒绝不足,同时保持任务性能的提升。最后,我们提供了初步证据,表明可以通过测量微调更新与“邪恶”权重方向之间的相似性来检测突发的不一致行为,这表明可以监控训练期间权重的演变,并检测在训练或评估期间从未表现出来的罕见不一致行为。
🔬 方法详解
问题定义:大型语言模型在训练过程中,难以获得覆盖广泛分布的高质量反馈,导致模型行为难以控制。此外,针对特定任务的微调可能引入不期望的行为漂移,例如谄媚或拒绝回答等。现有方法,如激活引导,在分布外泛化能力上存在局限性。
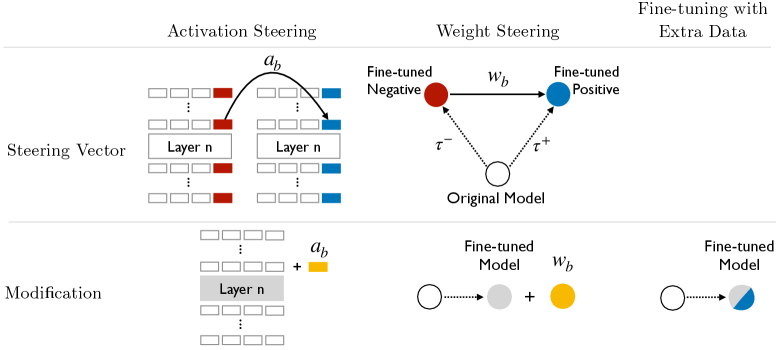
核心思路:本文的核心思路是通过权重空间中的算术运算来引导模型的行为。具体来说,通过对比两个微调后的模型权重差异,提取出代表特定行为(例如,期望行为和相反行为)的权重方向,然后通过添加或移除该方向来调整原始模型的权重,从而实现对模型行为的精确控制。
技术框架:该方法主要包含以下几个步骤:1) 使用少量数据对模型进行两次微调,一次诱导期望行为,另一次诱导相反行为;2) 计算两次微调后的权重差异,得到代表特定行为的权重方向;3) 将该权重方向添加到原始模型权重中,或从原始模型权重中移除,以增强或抑制该行为。
关键创新:该方法的核心创新在于利用权重空间的几何特性,通过简单的算术运算实现对模型行为的精确控制。与传统的激活引导方法相比,权重引导具有更强的泛化能力,能够在分布外数据上实现更有效的行为控制。此外,该方法还可以用于检测和缓解微调过程中引入的不良行为漂移。
关键设计:关键设计包括:1) 如何选择合适的微调数据,以确保能够有效地诱导期望行为和相反行为;2) 如何确定权重方向的缩放因子,以避免过度调整模型权重,导致性能下降;3) 如何定义和量化模型的不一致行为,以便评估权重引导的效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,权重引导方法在缓解谄媚行为和诱导不一致行为方面优于激活引导方法,尤其是在分布外数据上。此外,该方法还能有效减轻微调带来的不良行为漂移,在保持任务性能的同时,降低模型产生不期望行为的风险。初步实验还表明,可以通过监测权重变化来检测潜在的不一致行为。
🎯 应用场景
该研究成果可应用于提升LLM的安全性与可靠性,例如,减少模型产生有害或误导性信息的可能性。此外,该方法还可用于个性化模型行为,使其更符合特定用户的需求和偏好。该技术在对话系统、智能助手等领域具有广泛的应用前景。
📄 摘要(原文)
Providing high-quality feedback to Large Language Models (LLMs) on a diverse training distribution can be difficult and expensive, and providing feedback only on a narrow distribution can result in unintended generalizations. To better leverage narrow training data, we propose contrastive weight steering, a simple post-training method that edits the model parameters using weight arithmetic. We isolate a behavior direction in weight-space by subtracting the weight deltas from two small fine-tunes -- one that induces the desired behavior and another that induces its opposite -- and then add or remove this direction to modify the model's weights. We apply this technique to mitigate sycophancy and induce misalignment, and find that weight steering often generalizes further than activation steering, achieving stronger out-of-distribution behavioral control before degrading general capabilities. We also show that, in the context of task-specific fine-tuning, weight steering can partially mitigate undesired behavioral drift: it can reduce sycophancy and under-refusals introduced during fine-tuning while preserving task performance gains. Finally, we provide preliminary evidence that emergent misalignment can be detected by measuring the similarity between fine-tuning updates and an "evil" weight direction, suggesting that it may be possible to monitor the evolution of weights during training and detect rare misaligned behaviors that never manifest during training or evaluations.