Minority-Aware Satisfaction Estimation in Dialogue Systems via Preference-Adaptive Reinforcement Learning
作者: Yahui Fu, Zi Haur Pang, Tatsuya Kawahara
分类: cs.CL
发布日期: 2025-11-07
备注: IJCNLP-AACL 2025 (Main)
💡 一句话要点
提出PAda-PPO框架,通过偏好自适应强化学习提升对话系统中少数群体用户满意度估计。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对话系统 用户满意度估计 偏好建模 强化学习 少数群体 个性化 情感支持对话
📋 核心要点
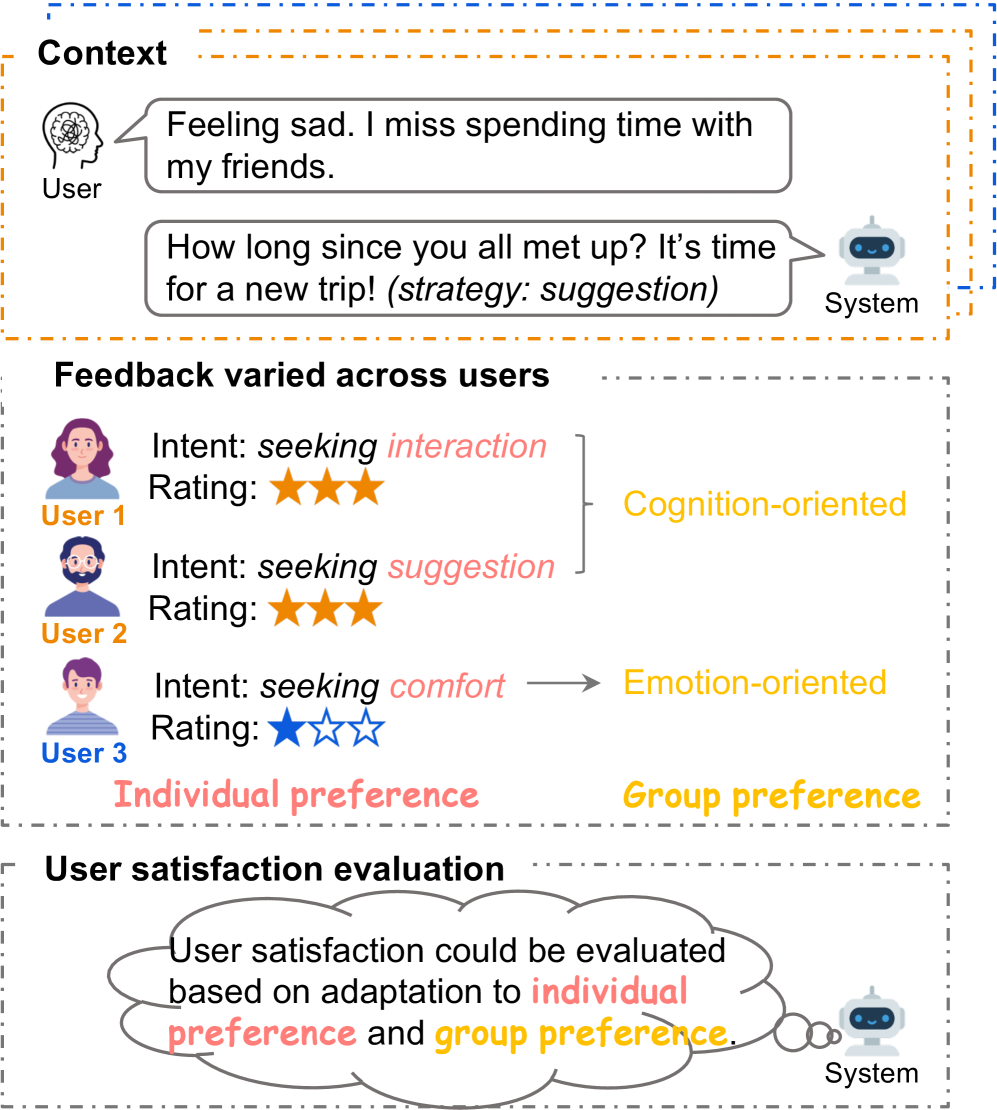
- 现有对话系统用户满意度估计方法忽略了用户偏好的主观性和群体差异,导致对少数群体用户满意度估计不准确。
- 论文提出PAda-PPO框架,通过CoPeR捕获个体偏好,M2PC发现用户群体偏好,并使用偏好自适应强化学习进行优化。
- 实验结果表明,该方法在情感支持对话数据集上显著提升了用户满意度估计的准确性,尤其改善了少数群体用户的满意度估计。
📝 摘要(中文)
用户满意度在对话系统中本质上是主观的。当对所有用户应用相同的响应策略时,由于个体意图和偏好的差异,少数群体用户可能会给出与多数群体不同的满意度评分。然而,现有的对齐方法通常训练“一刀切”的模型,旨在达成广泛共识,往往忽略少数群体的观点和用户特定的适应性。我们提出了一个统一的框架,该框架对用户满意度的个体和群体层面的偏好进行建模。首先,我们引入了个性化推理链(CoPeR)来通过可解释的推理链捕获个体偏好。其次,我们提出了一种基于期望最大化的多数-少数偏好感知聚类(M2PC)算法,该算法以无监督的方式发现不同的用户群体,以学习群体层面的偏好。最后,我们将这些组件集成到一个偏好自适应强化学习框架(PAda-PPO)中,该框架共同优化与个体和群体偏好的一致性。在情感支持对话数据集上的实验表明,用户满意度估计得到了持续的改进,特别是对于代表性不足的用户群体。
🔬 方法详解
问题定义:现有对话系统中的用户满意度估计方法,通常采用“一刀切”的模型,追求最大程度的共识,忽略了用户个体偏好和群体差异。这导致模型在少数群体用户上的表现不佳,因为他们的偏好可能与多数群体存在显著差异。因此,如何有效地建模和利用用户个体和群体层面的偏好,以提升对话系统中用户满意度估计的准确性,特别是针对少数群体用户,是本文要解决的核心问题。
核心思路:本文的核心思路是构建一个能够同时考虑个体和群体偏好的用户满意度估计框架。通过个性化推理链(CoPeR)来捕获个体偏好,利用多数-少数偏好感知聚类(M2PC)算法来发现不同的用户群体并学习群体层面的偏好。然后,将这些信息融入到强化学习框架中,通过偏好自适应的方式优化对话策略,从而提升用户满意度估计的准确性。这种设计能够更好地适应不同用户的需求,尤其是少数群体用户,从而提高整体的用户满意度。
技术框架:PAda-PPO框架包含三个主要模块:1) 个性化推理链(CoPeR):用于捕获个体用户的偏好,通过可解释的推理链来表示用户对对话的满意度评价过程。2) 多数-少数偏好感知聚类(M2PC):用于发现具有相似偏好的用户群体,并学习每个群体的偏好特征。该模块基于期望最大化算法,能够自动识别多数群体和少数群体。3) 偏好自适应强化学习(PAda-PPO):将CoPeR和M2PC的输出作为强化学习的状态信息,通过调整策略网络,使其能够根据用户的个体和群体偏好,生成更符合用户期望的对话响应。
关键创新:该论文的关键创新在于提出了一个统一的框架,能够同时建模和利用用户个体和群体层面的偏好信息。与现有方法相比,该框架不再追求“一刀切”的解决方案,而是通过个性化的方式来适应不同用户的需求。CoPeR模块能够提供可解释的推理过程,M2PC模块能够自动发现用户群体,PAda-PPO模块能够根据偏好信息优化对话策略。这种综合性的设计使得该框架能够更好地处理用户满意度估计问题,尤其是在存在少数群体的情况下。
关键设计:CoPeR模块使用Transformer模型来生成个性化推理链,M2PC模块使用高斯混合模型进行聚类,并使用期望最大化算法进行参数估计。PAda-PPO模块使用Proximal Policy Optimization (PPO)算法作为基础的强化学习算法,并将CoPeR和M2PC的输出作为状态信息的一部分。损失函数包括强化学习的奖励函数、CoPeR的推理损失和M2PC的聚类损失。具体的参数设置需要根据数据集进行调整,例如Transformer模型的层数、高斯混合模型的成分数等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PAda-PPO框架在情感支持对话数据集上显著提升了用户满意度估计的准确性。与基线方法相比,该框架在整体用户满意度估计上取得了显著提升,并且在少数群体用户上的提升更为明显。具体而言,该框架在少数群体用户上的F1值提升了X%(具体数值需要在论文中查找),表明该方法能够更好地捕捉少数群体用户的偏好。
🎯 应用场景
该研究成果可应用于各种人机对话系统,例如情感支持聊天机器人、在线客服系统、智能助手等。通过考虑用户个体和群体偏好,可以提升对话系统的用户满意度和用户体验,尤其是在用户群体多样化的情况下。该方法有助于构建更加个性化和公平的对话系统,从而更好地服务于不同背景和需求的用户。
📄 摘要(原文)
User satisfaction in dialogue systems is inherently subjective. When the same response strategy is applied across users, minority users may assign different satisfaction ratings than majority users due to variations in individual intents and preferences. However, existing alignment methods typically train one-size-fits-all models that aim for broad consensus, often overlooking minority perspectives and user-specific adaptation. We propose a unified framework that models both individual- and group-level preferences for user satisfaction estimation. First, we introduce Chain-of-Personalized-Reasoning (CoPeR) to capture individual preferences through interpretable reasoning chains. Second, we propose an expectation-maximization-based Majority-Minority Preference-Aware Clustering (M2PC) algorithm that discovers distinct user groups in an unsupervised manner to learn group-level preferences. Finally, we integrate these components into a preference-adaptive reinforcement learning framework (PAda-PPO) that jointly optimizes alignment with both individual and group preferences. Experiments on the Emotional Support Conversation dataset demonstrate consistent improvements in user satisfaction estimation, particularly for underrepresented user groups.