Listening Between the Lines: Decoding Podcast Narratives with Language Modeling
作者: Shreya Gupta, Ojasva Saxena, Arghodeep Nandi, Sarah Masud, Kiran Garimella, Tanmoy Chakraborty
分类: cs.CL, cs.SI
发布日期: 2025-11-07 (更新: 2025-12-16)
备注: 10 pages, 6 Figures, 5 Tables. Under review
💡 一句话要点
提出基于BERT微调的框架标注方法,用于解码播客叙事中的潜在框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 播客分析 叙事框架 自然语言处理 BERT微调 实体链接
📋 核心要点
- 现有大型语言模型难以捕捉播客中细微的叙事框架,导致无法准确分析播客叙事。
- 通过微调BERT模型,将叙事框架与对话中的实体联系起来,从而将抽象框架置于具体细节中。
- 该方法将细粒度的框架标签与高层次的主题相关联,揭示了主题与框架之间的系统关系。
📝 摘要(中文)
播客已成为塑造公众舆论的重要场所,是理解当代话语的重要来源。其通常无脚本、多主题和对话式的风格提供了一种丰富但复杂的数据形式。为了分析播客如何说服和告知,我们必须检查它们的叙事结构,特别是它们使用的叙事框架。播客的流动性和对话性给自动化分析带来了重大挑战。我们表明,通常在新闻文章等更结构化的文本上训练的现有大型语言模型,难以捕捉人类听众用来识别叙事框架的细微线索。因此,目前的方法无法大规模地准确分析播客叙事。为了解决这个问题,我们开发并评估了一个微调的BERT模型,该模型将叙事框架与对话中提到的特定实体显式地联系起来,有效地将抽象框架置于具体的细节中。然后,我们的方法使用这些细粒度的框架标签,并将它们与高层次的主题相关联,以揭示更广泛的话语趋势。本文的主要贡献是:(i)一种新的框架标注方法,更紧密地符合人类对混乱的对话数据的判断,以及(ii)一种新的分析方法,揭示了正在讨论的内容(主题)和呈现方式(框架)之间的系统关系,为研究数字媒体中的影响提供了一个更强大的框架。
🔬 方法详解
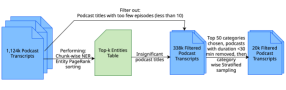
问题定义:现有方法难以准确分析播客叙事,因为播客的对话风格和非结构化文本使得大型语言模型难以捕捉细微的叙事框架。这些模型通常在结构化文本(如新闻文章)上训练,无法很好地适应播客的复杂性。因此,自动化分析播客叙事并理解其潜在影响变得困难。
核心思路:论文的核心思路是将叙事框架与播客对话中提到的具体实体联系起来,从而将抽象的框架“锚定”在具体的细节上。通过这种方式,模型可以更好地理解叙事框架的上下文,并更准确地识别它们。这种方法模仿了人类听众理解叙事的方式,即通过关注具体的细节来推断更广泛的叙事框架。
技术框架:该方法主要包含以下几个阶段:1) 数据收集与标注:收集播客数据,并使用人工标注的方式为每个话语片段标注叙事框架和相关实体。2) 模型微调:使用标注好的数据对BERT模型进行微调,使其能够预测给定话语片段的叙事框架和相关实体。3) 框架-主题关联分析:将预测的框架标签与高层次的主题进行关联分析,以揭示主题与框架之间的系统关系。
关键创新:该方法最重要的创新点在于将叙事框架与具体实体联系起来。传统的框架分析方法通常只关注文本的表面特征,而忽略了文本背后的实体信息。通过将框架与实体联系起来,该方法可以更好地理解框架的语义,并更准确地识别它们。
关键设计:该方法使用微调的BERT模型作为核心组件。BERT模型是一种预训练的Transformer模型,具有强大的文本表示能力。通过在标注好的播客数据上进行微调,BERT模型可以学习到播客叙事的特定特征,并更准确地预测叙事框架和相关实体。具体的微调策略和超参数设置(如学习率、batch size等)未知。
🖼️ 关键图片


📊 实验亮点
论文提出了一种新的框架标注方法,更紧密地符合人类对混乱的对话数据的判断。通过将叙事框架与对话中提到的特定实体显式地联系起来,有效地将抽象框架置于具体的细节中。该方法能够揭示正在讨论的内容(主题)和呈现方式(框架)之间的系统关系,为研究数字媒体中的影响提供了一个更强大的框架。具体的性能数据未知。
🎯 应用场景
该研究成果可应用于舆情分析、政治传播研究、市场营销等领域。通过分析播客的叙事框架,可以了解公众对特定议题的看法,评估政治宣传的效果,以及优化市场营销策略。此外,该方法还可以用于检测虚假信息和操纵性内容,提高数字媒体的透明度和可信度。
📄 摘要(原文)
Podcasts have become a central arena for shaping public opinion, making them a vital source for understanding contemporary discourse. Their typically unscripted, multi-themed, and conversational style offers a rich but complex form of data. To analyze how podcasts persuade and inform, we must examine their narrative structures -- specifically, the narrative frames they employ. The fluid and conversational nature of podcasts presents a significant challenge for automated analysis. We show that existing large language models, typically trained on more structured text such as news articles, struggle to capture the subtle cues that human listeners rely on to identify narrative frames. As a result, current approaches fall short of accurately analyzing podcast narratives at scale. To solve this, we develop and evaluate a fine-tuned BERT model that explicitly links narrative frames to specific entities mentioned in the conversation, effectively grounding the abstract frame in concrete details. Our approach then uses these granular frame labels and correlates them with high-level topics to reveal broader discourse trends. The primary contributions of this paper are: (i) a novel frame-labeling methodology that more closely aligns with human judgment for messy, conversational data, and (ii) a new analysis that uncovers the systematic relationship between what is being discussed (the topic) and how it is being presented (the frame), offering a more robust framework for studying influence in digital media.