Reflective Personalization Optimization: A Post-hoc Rewriting Framework for Black-Box Large Language Models
作者: Teqi Hao, Xioayu Tan, Shaojie Shi, Yinghui Xu, Xihe Qiu
分类: cs.CL
发布日期: 2025-11-07
💡 一句话要点
提出RPO框架,解耦内容生成与个性化,提升黑盒大语言模型的用户定制能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化生成 大语言模型 黑盒模型 反思优化 强化学习 风格迁移 用户建模
📋 核心要点
- 现有黑盒LLM个性化方法依赖上下文注入,模型需同时兼顾内容质量与风格匹配,导致性能瓶颈。
- RPO框架解耦内容生成与个性化,先生成通用高质量内容,再通过外部模块重写以适应用户偏好。
- 实验表明,RPO在LaMP基准上显著优于现有方法,证明显式响应塑造优于隐式上下文注入。
📝 摘要(中文)
黑盒大语言模型(LLMs)的个性化是一个关键但具有挑战性的任务。现有方法主要依赖于上下文注入,将用户历史嵌入到提示中以直接指导生成过程。然而,这种单步范式给模型带来了双重负担:既要生成准确的内容,又要与用户特定的风格保持一致。这通常会导致一种权衡,从而损害输出质量并限制精确控制。为了解决这一根本矛盾,我们提出了反思个性化优化(RPO),这是一种通过将内容生成与对齐解耦来重新定义个性化范式的新颖框架。RPO分两个不同的阶段运行:首先,基础模型生成高质量的通用响应;然后,外部反思模块显式地重写此输出以与用户的偏好对齐。该反思模块使用两阶段过程进行训练。最初,在结构化的重写轨迹上采用监督式微调,以建立核心的个性化推理策略,该策略对从通用响应到用户对齐响应的转换进行建模。随后,应用强化学习来进一步完善和提高个性化输出的质量。在LaMP基准上的综合实验表明,通过将内容生成与个性化分离,RPO明显优于最先进的基线。这些发现强调了显式响应塑造优于隐式上下文注入。此外,RPO引入了一种高效的、模型无关的个性化层,可以与任何底层基础模型无缝集成,从而为以用户为中心的生成场景开辟了一条新的有效方向。
🔬 方法详解
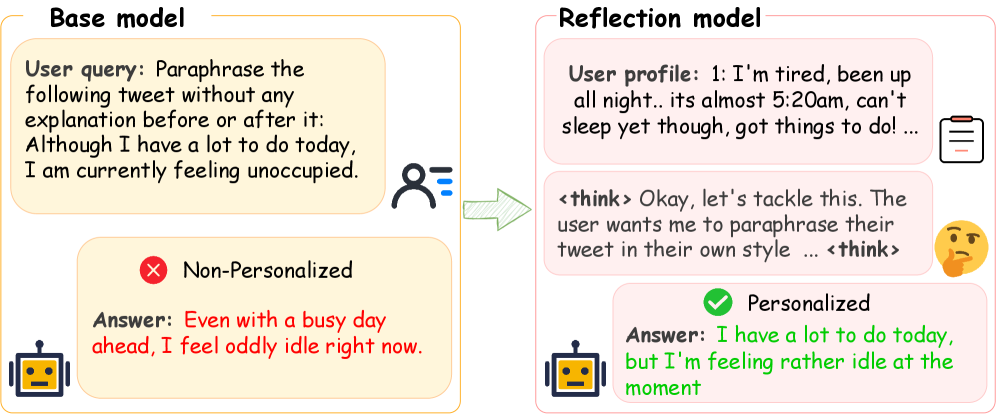
问题定义:现有黑盒大语言模型个性化方法,如上下文注入,要求模型在生成内容的同时兼顾用户风格,这给模型带来了双重负担,导致生成质量和个性化程度之间存在trade-off。模型难以在保证内容准确性的前提下,精准地捕捉并模仿用户的写作风格或偏好。
核心思路:RPO的核心思路是将内容生成和个性化风格调整解耦。首先,利用一个基础模型生成高质量的、通用的回复内容,保证内容本身的质量。然后,使用一个独立的“反思模块”对通用回复进行重写,使其符合用户的特定风格和偏好。这种解耦的设计使得模型可以专注于各自的任务,从而提高整体性能。
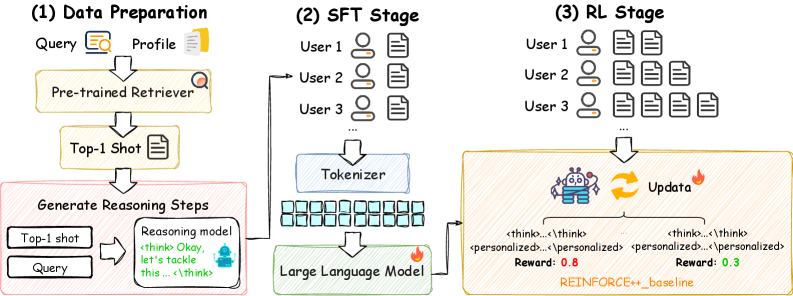
技术框架:RPO框架包含两个主要阶段:内容生成阶段和反思重写阶段。在内容生成阶段,使用一个预训练的黑盒大语言模型(Base Model)根据输入生成一个通用的回复。在反思重写阶段,使用一个专门训练的“反思模块”(Reflection Module)对通用回复进行修改,使其更符合用户的个性化风格。反思模块的训练分为两个步骤:首先,使用监督学习,在结构化的重写轨迹上进行微调,学习从通用回复到个性化回复的转换策略;然后,使用强化学习进一步优化重写后的回复质量。
关键创新:RPO的关键创新在于将个性化过程显式地建模为一个独立的重写步骤,而不是像传统方法那样隐式地通过上下文注入来影响生成过程。这种显式的解耦使得模型可以更好地控制个性化的程度和质量。此外,RPO框架具有模型无关性,可以与任何黑盒大语言模型集成,具有很强的通用性。
关键设计:反思模块的训练是RPO的关键。监督学习阶段使用结构化的重写轨迹,这些轨迹包含了通用回复和对应的个性化回复。通过最小化预测回复与目标个性化回复之间的差异来训练反思模块。强化学习阶段使用奖励函数来评估重写后的回复质量,奖励函数可以考虑多个因素,如与用户风格的相似度、内容流畅度等。具体的网络结构和参数设置在论文中可能没有详细说明,属于实现细节,需要参考具体代码或后续研究。
🖼️ 关键图片

📊 实验亮点
在LaMP基准测试中,RPO框架显著优于现有最先进的基线方法。实验结果表明,通过解耦内容生成和个性化,RPO能够生成更高质量、更符合用户风格的回复。具体的性能提升数据需要在论文中查找,但总体趋势表明RPO在个性化生成任务中具有显著优势。
🎯 应用场景
RPO框架可广泛应用于各种需要个性化内容生成的场景,例如:智能客服、个性化推荐、社交媒体内容生成等。通过RPO,可以为每个用户定制专属的回复或内容,提升用户体验和满意度。该研究为用户定制化生成任务提供了一种新的有效方法,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
The personalization of black-box large language models (LLMs) is a critical yet challenging task. Existing approaches predominantly rely on context injection, where user history is embedded into the prompt to directly guide the generation process. However, this single-step paradigm imposes a dual burden on the model: generating accurate content while simultaneously aligning with user-specific styles. This often results in a trade-off that compromises output quality and limits precise control. To address this fundamental tension, we propose Reflective Personalization Optimization (RPO), a novel framework that redefines the personalization paradigm by decoupling content generation from alignment. RPO operates in two distinct stages: first, a base model generates a high-quality, generic response; then, an external reflection module explicitly rewrites this output to align with the user's preferences. This reflection module is trained using a two-stage process. Initially, supervised fine-tuning is employed on structured rewriting trajectories to establish a core personalized reasoning policy that models the transformation from generic to user-aligned responses. Subsequently, reinforcement learning is applied to further refine and enhance the quality of the personalized outputs. Comprehensive experiments on the LaMP benchmark demonstrate that RPO, by decoupling content generation from personalization, significantly outperforms state-of-the-art baselines. These findings underscore the superiority of explicit response shaping over implicit context injection. Moreover, RPO introduces an efficient, model-agnostic personalization layer that can be seamlessly integrated with any underlying base model, paving the way for a new and effective direction in user-centric generation scenarios.