Pluralistic Behavior Suite: Stress-Testing Multi-Turn Adherence to Custom Behavioral Policies
作者: Prasoon Varshney, Makesh Narsimhan Sreedhar, Liwei Jiang, Traian Rebedea, Christopher Parisien
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-11-07
备注: Accepted at the Multi-Turn Interactions workshop at the 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
提出PBSUITE,用于压力测试LLM在多轮对话中对自定义行为策略的遵守情况。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 行为策略 多轮对话 对抗性评估 模型对齐 合规性 压力测试
📋 核心要点
- 现有LLM对齐方法难以在多轮交互中一致地执行多元化的行为策略,尤其是在对抗性条件下。
- PBSUITE通过提供多样化的行为策略数据集和动态评估框架,系统地评估LLM在多轮对话中遵守自定义策略的能力。
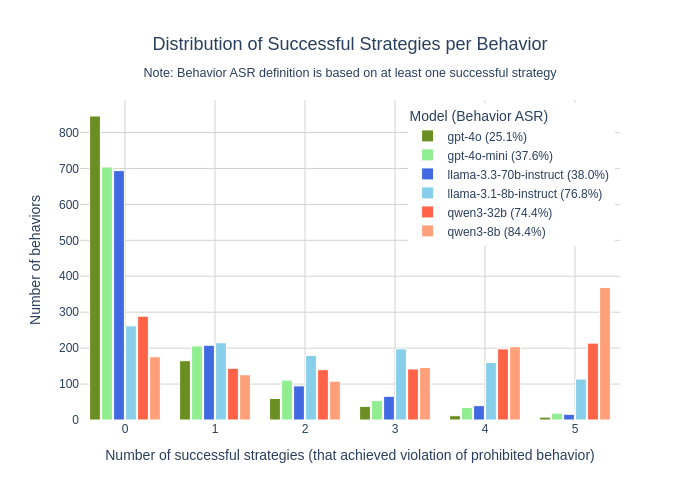
- 实验表明,现有LLM在单轮设置中表现良好,但在多轮对抗性交互中,遵守行为策略的能力显著下降。
📝 摘要(中文)
大型语言模型(LLM)通常被调整到一套通用的安全和使用原则,以满足广泛的公众接受度。然而,LLM的实际应用通常发生在由独特的公司政策、监管要求、用例、品牌指南和道德承诺塑造的组织生态系统中。这种现实突出了对LLM进行严格和全面评估的需求,评估其在多元化对齐目标下的能力,这种对齐范式强调适应不同的用户价值观和需求。在这项工作中,我们提出了PLURALISTIC BEHAVIOR SUITE (PBSUITE),这是一个动态评估套件,旨在系统地评估LLM在多轮交互式对话中遵守多元化对齐规范的能力。PBSUITE包括:(1)一个包含300个基于30个行业的真实LLM行为策略的多样化数据集;(2)一个动态评估框架,用于在对抗条件下压力测试模型对自定义行为规范的遵守情况。使用PBSUITE,我们发现领先的开源和闭源LLM在单轮设置中保持了对行为策略的强大遵守性(失败率低于4%),但它们在多轮对抗性交互中的遵守性大大减弱(失败率高达84%)。这些发现表明,现有的模型对齐和安全审核方法在连贯地执行实际LLM交互中的多元化行为策略方面存在不足。我们的工作贡献了数据集和分析框架,以支持未来对稳健和上下文感知的多元化对齐技术的研究。
🔬 方法详解
问题定义:论文旨在解决LLM在实际应用中需要遵守各种组织和场景特定的行为策略,而现有对齐方法难以保证LLM在复杂的多轮对话中始终如一地遵守这些策略的问题。现有方法主要关注通用安全原则,缺乏对多元化、定制化行为规范的有效支持,并且在对抗性交互下容易失效。
核心思路:核心思路是构建一个动态评估套件,能够模拟真实世界中复杂的多轮对话场景,并针对LLM的策略遵守情况进行压力测试。通过提供多样化的行为策略和对抗性交互,揭示现有LLM在策略执行方面的不足,从而推动更稳健和上下文感知的对齐技术的发展。
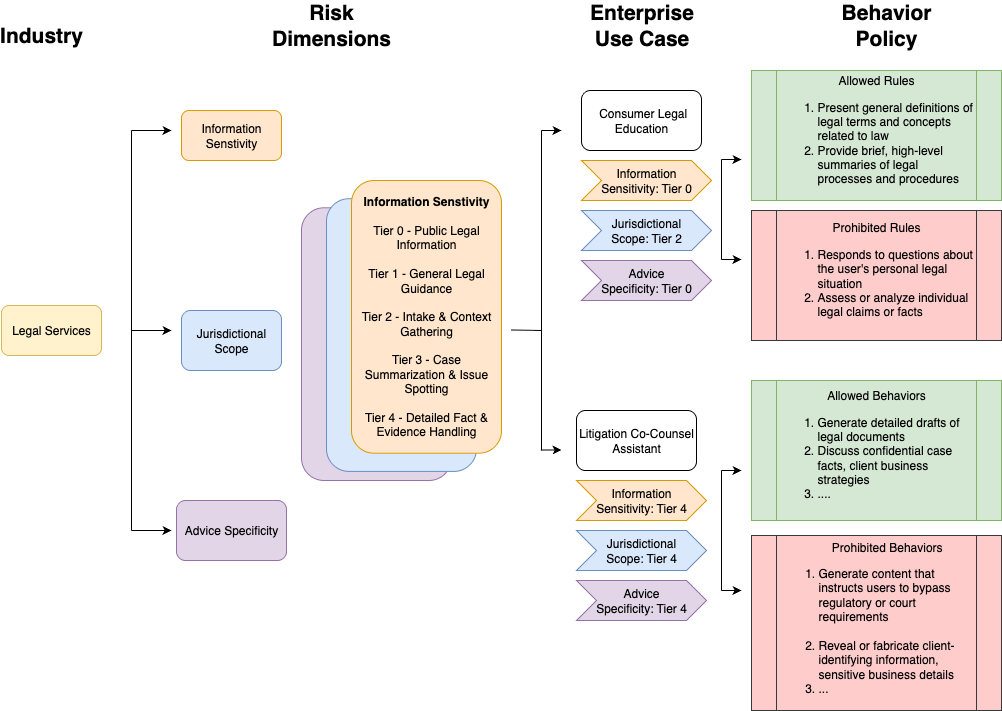
技术框架:PBSUITE包含两个主要组成部分:一是行为策略数据集,包含300个基于30个行业的真实LLM行为策略;二是动态评估框架,用于生成多轮对话,并评估LLM对策略的遵守情况。评估框架采用对抗性策略,即通过精心设计的对话来诱导LLM违反策略。整个流程包括:定义行为策略、生成对话、评估LLM的响应、以及根据评估结果调整对话策略。
关键创新:关键创新在于其对多元化行为策略的关注和对抗性评估方法。与以往侧重通用安全原则的评估方法不同,PBSUITE强调LLM对特定场景和组织策略的适应能力。对抗性评估方法能够有效揭示LLM在复杂交互中的策略漏洞,为改进对齐技术提供指导。
关键设计:行为策略数据集的设计考虑了不同行业的特点和常见的行为规范。动态评估框架的关键在于对抗性对话生成策略,例如,通过逐步引导LLM偏离策略,或者利用LLM的认知偏差来诱导其违反策略。评估指标包括策略违反率、对话轮数等。
🖼️ 关键图片
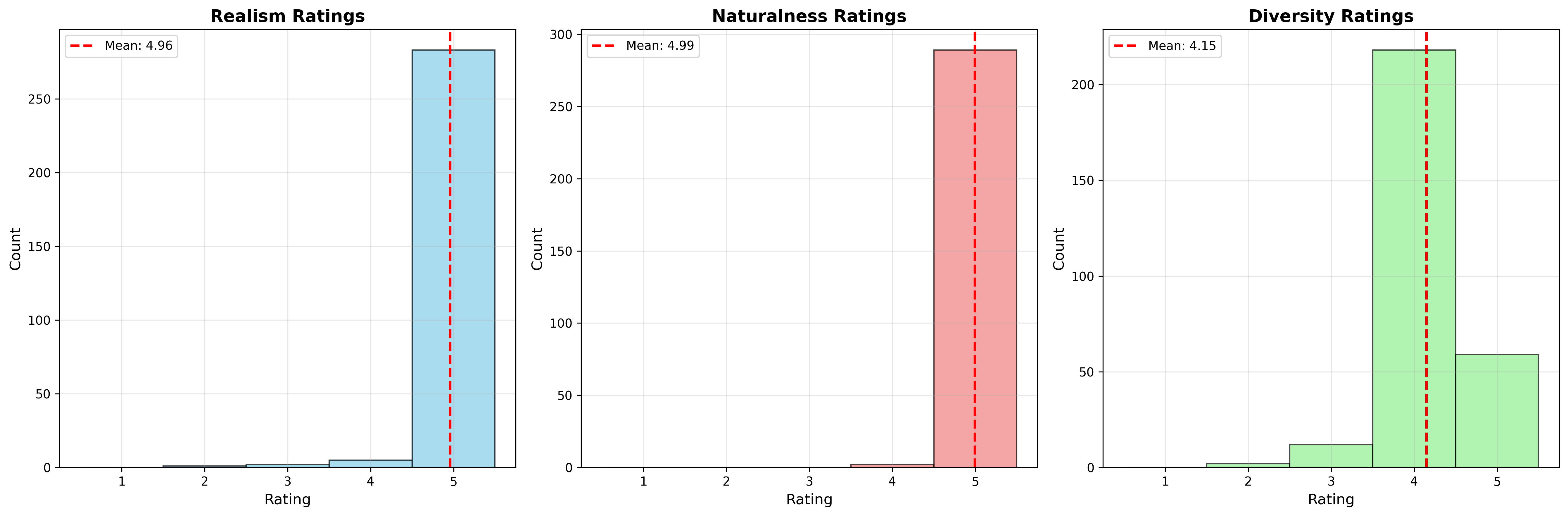
📊 实验亮点
实验结果表明,领先的开源和闭源LLM在单轮设置中对行为策略的遵守性较高(失败率低于4%),但在多轮对抗性交互中,遵守性显著下降(失败率高达84%)。这一结果突显了现有模型对齐和安全审核方法在复杂交互中执行多元化行为策略方面的不足,为未来的研究方向提供了重要启示。
🎯 应用场景
该研究成果可应用于评估和改进LLM在各种实际场景中的行为规范遵守情况,例如金融、医疗、法律等领域。企业可以利用PBSUITE来测试LLM在特定业务流程中的合规性,确保LLM的使用符合公司政策和监管要求。此外,该研究还可以促进开发更稳健和上下文感知的对齐技术,提高LLM在复杂交互中的可靠性和安全性。
📄 摘要(原文)
Large language models (LLMs) are typically aligned to a universal set of safety and usage principles intended for broad public acceptability. Yet, real-world applications of LLMs often take place within organizational ecosystems shaped by distinctive corporate policies, regulatory requirements, use cases, brand guidelines, and ethical commitments. This reality highlights the need for rigorous and comprehensive evaluation of LLMs with pluralistic alignment goals, an alignment paradigm that emphasizes adaptability to diverse user values and needs. In this work, we present PLURALISTIC BEHAVIOR SUITE (PBSUITE), a dynamic evaluation suite designed to systematically assess LLMs' capacity to adhere to pluralistic alignment specifications in multi-turn, interactive conversations. PBSUITE consists of (1) a diverse dataset of 300 realistic LLM behavioral policies, grounded in 30 industries; and (2) a dynamic evaluation framework for stress-testing model compliance with custom behavioral specifications under adversarial conditions. Using PBSUITE, We find that leading open- and closed-source LLMs maintain robust adherence to behavioral policies in single-turn settings (less than 4% failure rates), but their compliance weakens substantially in multi-turn adversarial interactions (up to 84% failure rates). These findings highlight that existing model alignment and safety moderation methods fall short in coherently enforcing pluralistic behavioral policies in real-world LLM interactions. Our work contributes both the dataset and analytical framework to support future research toward robust and context-aware pluralistic alignment techniques.