AgentExpt: Automating AI Experiment Design with LLM-based Resource Retrieval Agent
作者: Yu Li, Lehui Li, Qingmin Liao, Fengli Xu, Yong Li
分类: cs.CL
发布日期: 2025-11-07
备注: 10 pages
💡 一句话要点
AgentExpt:利用LLM驱动的资源检索Agent自动化AI实验设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI实验设计 自动化 大型语言模型 资源检索 数据集推荐 基线推荐 引用网络
📋 核心要点
- 现有AI实验设计自动化方法依赖公共数据集,忽略了论文中实际使用的数据,且过度依赖内容相似性,导致推荐结果不佳。
- AgentExpt利用论文引用网络中的集体感知,构建数据集和基线的全面推荐框架,提升实验设计的自动化水平。
- 实验结果表明,AgentExpt在数据集覆盖率和推荐性能上均优于现有方法,Recall@20提升5.85%,HitRate@5提升8.30%。
📝 摘要(中文)
大型语言模型Agent在以Web为中心的任务(如信息检索、复杂推理)中能力日益增强。这些新兴能力引发了人们对开发LLM Agent以促进科学探索的浓厚兴趣。AI研究中的一个关键应用是通过Agent自动进行数据集和基线检索来自动化实验设计。然而,先前的研究工作受到数据覆盖范围有限的限制,因为推荐数据集主要从公共门户网站收集候选对象,而忽略了许多实际发表论文中使用的数据集;并且过度依赖内容相似性,这使得模型偏向于表面相似性而忽略了实验适用性。本文利用嵌入在基线和数据集引用网络中的集体感知,提出了一个全面的基线和数据集推荐框架。首先,我们设计了一个自动数据收集管道,将大约十万篇已接受的论文链接到它们实际使用的基线和数据集。其次,我们提出了一种集体感知增强的检索器,为了表示每个数据集或基线在学术网络中的位置,它将自我描述与聚合的引用上下文连接起来。为了实现高效的候选召回,我们对这些表示进行微调嵌入模型。最后,我们开发了一个推理增强的重排序器,它提取交互链以构建显式推理链,并微调大型语言模型以产生可解释的理由和改进的排名。我们整理的数据集涵盖了过去五年顶级AI会议上使用的85%的数据集和基线。在我们的数据集上,所提出的方法优于最强的先前基线,在Recall@20中平均提高了+5.85%,在HitRate@5中平均提高了+8.30%。总而言之,我们的结果推进了实验设计的可靠、可解释的自动化。
🔬 方法详解
问题定义:现有AI实验设计自动化方法主要依赖公共数据集,这些数据集往往无法覆盖所有已发表论文中实际使用的数据集和基线。此外,现有方法过度依赖内容相似性进行推荐,容易被表面相似性误导,忽略了数据集和基线与特定实验的实际适用性。这导致推荐结果的准确性和相关性较低,阻碍了AI实验设计的自动化进程。
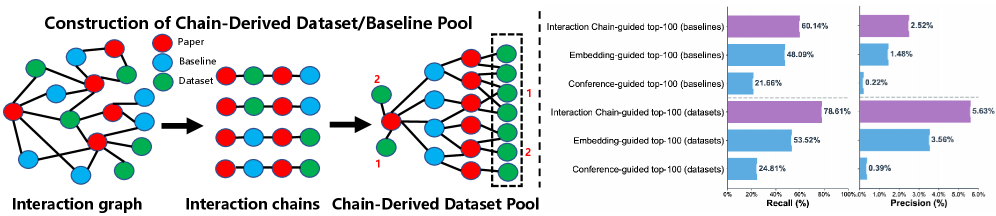
核心思路:AgentExpt的核心思路是利用学术论文的引用网络中蕴含的“集体感知”来提升数据集和基线的推荐效果。通过分析论文之间的引用关系,可以更准确地了解数据集和基线在不同实验中的实际应用情况和效果,从而克服现有方法对内容相似性的过度依赖。这种方法能够更好地捕捉数据集和基线的实验适用性,提高推荐结果的质量。
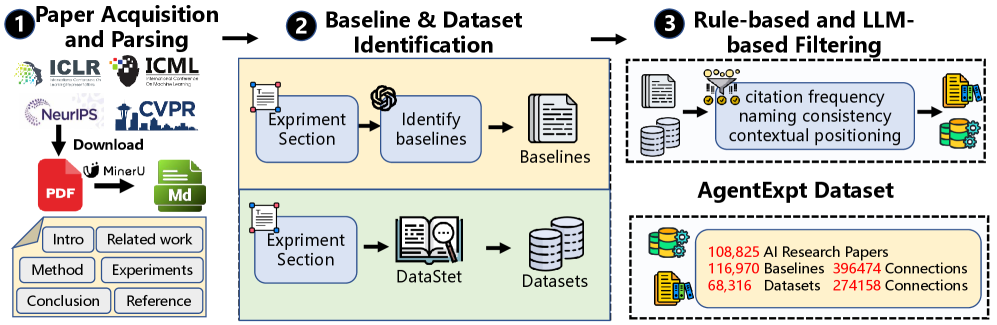
技术框架:AgentExpt包含三个主要模块:自动数据收集管道、集体感知增强的检索器和推理增强的重排序器。首先,自动数据收集管道负责从学术论文中提取数据集和基线的使用信息,构建大规模的数据集和基线知识库。其次,集体感知增强的检索器利用数据集和基线的自我描述以及引用上下文信息,学习数据集和基线的嵌入表示,用于高效的候选召回。最后,推理增强的重排序器通过构建显式推理链,利用大型语言模型对候选数据集和基线进行重排序,生成可解释的理由和更精确的排名。
关键创新:AgentExpt的关键创新在于利用学术论文的引用网络来增强数据集和基线的推荐效果。通过将数据集和基线的自我描述与引用上下文信息相结合,可以更全面地了解它们在不同实验中的应用情况和效果。此外,AgentExpt还引入了推理增强的重排序器,利用大型语言模型生成可解释的推荐理由,提高了推荐结果的可信度和透明度。
关键设计:在集体感知增强的检索器中,论文使用了一种特殊的嵌入模型微调方法,将数据集/基线的描述信息和其被引用的上下文信息拼接起来,作为模型的输入,从而学习到更具有实验语义的嵌入表示。在推理增强的重排序器中,论文设计了一种交互链提取方法,用于构建显式推理链,并微调大型语言模型以生成可解释的理由和改进的排名。具体的参数设置和网络结构等细节在论文中进行了详细描述,此处未知。
🖼️ 关键图片

📊 实验亮点
AgentExpt在自建数据集上进行了评估,该数据集涵盖了过去五年顶级AI会议上使用的85%的数据集和基线。实验结果表明,AgentExpt优于现有的最佳基线方法,在Recall@20指标上平均提升了5.85%,在HitRate@5指标上平均提升了8.30%。这些结果表明,AgentExpt能够更准确地推荐合适的基线和数据集,有效提升了AI实验设计的自动化水平。
🎯 应用场景
AgentExpt可应用于自动化AI实验设计,帮助研究人员快速找到合适的基线和数据集,加速实验迭代过程。该研究还可用于构建智能科研助手,为研究人员提供个性化的实验建议和资源推荐。此外,该方法在教育领域也有潜在应用,可以帮助学生更好地理解和选择合适的实验材料。
📄 摘要(原文)
Large language model agents are becoming increasingly capable at web-centric tasks such as information retrieval, complex reasoning. These emerging capabilities have given rise to surge research interests in developing LLM agent for facilitating scientific quest. One key application in AI research is to automate experiment design through agentic dataset and baseline retrieval. However, prior efforts suffer from limited data coverage, as recommendation datasets primarily harvest candidates from public portals and omit many datasets actually used in published papers, and from an overreliance on content similarity that biases model toward superficial similarity and overlooks experimental suitability. Harnessing collective perception embedded in the baseline and dataset citation network, we present a comprehensive framework for baseline and dataset recommendation. First, we design an automated data-collection pipeline that links roughly one hundred thousand accepted papers to the baselines and datasets they actually used. Second, we propose a collective perception enhanced retriever. To represent the position of each dataset or baseline within the scholarly network, it concatenates self-descriptions with aggregated citation contexts. To achieve efficient candidate recall, we finetune an embedding model on these representations. Finally, we develop a reasoning-augmented reranker that exact interaction chains to construct explicit reasoning chains and finetunes a large language model to produce interpretable justifications and refined rankings. The dataset we curated covers 85\% of the datasets and baselines used at top AI conferences over the past five years. On our dataset, the proposed method outperforms the strongest prior baseline with average gains of +5.85\% in Recall@20, +8.30\% in HitRate@5. Taken together, our results advance reliable, interpretable automation of experimental design.