multiMentalRoBERTa: A Fine-tuned Multiclass Classifier for Mental Health Disorder
作者: K M Sajjadul Islam, John Fields, Praveen Madiraju
分类: cs.CL, cs.AI
发布日期: 2025-11-01 (更新: 2025-11-10)
备注: Accepted in IEEE Big Data, 8-11 December, 2025 @ Macau SAR, China
💡 一句话要点
multiMentalRoBERTa:用于心理健康障碍多分类的微调RoBERTa模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理健康 文本分类 RoBERTa 微调 多分类 可解释性 社交媒体 自然语言处理
📋 核心要点
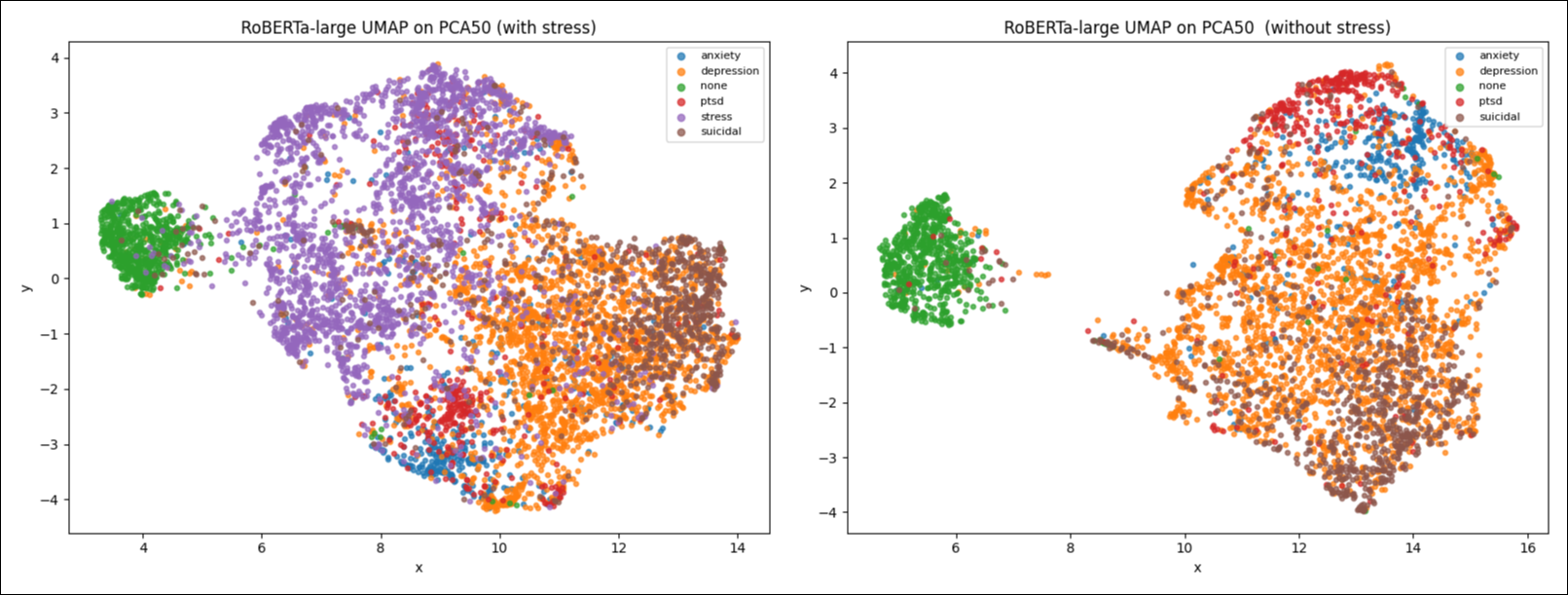
- 现有方法难以准确区分社交媒体文本中细粒度的心理健康类别,尤其是在类别存在重叠的情况下。
- 通过微调RoBERTa模型,并结合多个数据集进行训练,提升模型对不同心理健康状态的识别能力。
- 实验表明,multiMentalRoBERTa在多分类任务中优于其他模型,并在可解释性方面进行了深入分析。
📝 摘要(中文)
本研究提出了multiMentalRoBERTa,一个为常见心理健康状况(包括压力、焦虑、抑郁、创伤后应激障碍(PTSD)、自杀意念和中性言论)进行多分类而设计的微调RoBERTa模型。通过对多个精选数据集进行数据探索,分析了类别之间的重叠,揭示了抑郁和自杀意念之间以及焦虑和PTSD之间的强相关性,而压力则表现为一个广泛的、重叠的类别。与传统机器学习方法、领域特定Transformer和基于提示的大型语言模型的比较实验表明,multiMentalRoBERTa取得了优异的性能,在六类设置(包含压力)下的宏平均F1分数为0.839,在五类设置(不包含压力)下的宏平均F1分数为0.870,优于微调的MentalBERT和基线分类器。除了预测准确性之外,还应用了解释性方法,包括Layer Integrated Gradients和KeyBERT,以识别驱动分类的词汇线索,特别关注区分抑郁和自杀意念。研究结果强调了微调Transformer在敏感环境中进行可靠且可解释检测的有效性,同时也强调了公平性、偏差缓解和人机协作安全协议的重要性。总而言之,multiMentalRoBERTa被认为是一种轻量级、稳健且可部署的解决方案,可增强心理健康平台的支持能力。
🔬 方法详解
问题定义:论文旨在解决从社交媒体文本中准确识别多种心理健康障碍的问题。现有方法,包括传统的机器学习方法和领域特定的Transformer模型,在处理类别重叠(如抑郁和自杀意念)以及泛化能力方面存在不足。这些方法难以在实际应用中提供可靠的早期预警和支持。
核心思路:论文的核心思路是利用预训练语言模型RoBERTa的强大表征能力,通过微调使其适应心理健康文本分类任务。通过在多个相关数据集上进行训练,模型能够学习到更丰富的语义信息,从而提高分类的准确性和鲁棒性。此外,论文还关注模型的可解释性,以便更好地理解模型的决策过程。
技术框架:multiMentalRoBERTa的技术框架主要包括以下几个阶段:1) 数据收集和预处理:收集多个心理健康相关的社交媒体数据集,并进行清洗和标注。2) 模型微调:使用RoBERTa模型作为基础,在标注好的数据集上进行微调,使其适应心理健康文本分类任务。3) 模型评估:使用多种指标(如宏平均F1分数)评估模型的性能,并与其他基线模型进行比较。4) 可解释性分析:使用Layer Integrated Gradients和KeyBERT等方法分析模型决策的关键因素。
关键创新:论文的关键创新在于:1) 提出了multiMentalRoBERTa模型,该模型在多分类心理健康文本任务中表现出色。2) 深入分析了不同心理健康类别之间的重叠关系,并针对性地设计了训练策略。3) 强调了模型的可解释性,并使用多种方法分析了模型决策的关键因素。
关键设计:论文的关键设计包括:1) 使用RoBERTa作为基础模型,利用其强大的预训练知识。2) 采用多数据集联合训练的方式,提高模型的泛化能力。3) 使用宏平均F1分数作为主要评估指标,以平衡不同类别之间的性能。4) 使用Layer Integrated Gradients和KeyBERT等方法进行可解释性分析,以理解模型决策的关键因素。
🖼️ 关键图片

📊 实验亮点
multiMentalRoBERTa在六类心理健康分类任务中取得了0.839的宏平均F1分数,在五类(不包含压力)分类任务中取得了0.870的宏平均F1分数,显著优于MentalBERT和其他基线模型。此外,通过可解释性分析,研究揭示了模型决策的关键词汇线索,为理解模型行为提供了重要依据。
🎯 应用场景
该研究成果可应用于在线心理健康支持平台,用于自动识别用户的心理健康状态,提供个性化的支持和干预建议。此外,该模型还可以用于风险评估,帮助识别有自杀倾向或其他心理健康问题的用户,并及时提供帮助。该研究对于改善心理健康服务,提高早期干预的效率具有重要意义。
📄 摘要(原文)
The early detection of mental health disorders from social media text is critical for enabling timely support, risk assessment, and referral to appropriate resources. This work introduces multiMentalRoBERTa, a fine-tuned RoBERTa model designed for multiclass classification of common mental health conditions, including stress, anxiety, depression, post-traumatic stress disorder (PTSD), suicidal ideation, and neutral discourse. Drawing on multiple curated datasets, data exploration is conducted to analyze class overlaps, revealing strong correlations between depression and suicidal ideation as well as anxiety and PTSD, while stress emerges as a broad, overlapping category. Comparative experiments with traditional machine learning methods, domain-specific transformers, and prompting-based large language models demonstrate that multiMentalRoBERTa achieves superior performance, with macro F1-scores of 0.839 in the six-class setup and 0.870 in the five-class setup (excluding stress), outperforming both fine-tuned MentalBERT and baseline classifiers. Beyond predictive accuracy, explainability methods, including Layer Integrated Gradients and KeyBERT, are applied to identify lexical cues that drive classification, with a particular focus on distinguishing depression from suicidal ideation. The findings emphasize the effectiveness of fine-tuned transformers for reliable and interpretable detection in sensitive contexts, while also underscoring the importance of fairness, bias mitigation, and human-in-the-loop safety protocols. Overall, multiMentalRoBERTa is presented as a lightweight, robust, and deployable solution for enhancing support in mental health platforms.