EncouRAGe: Evaluating RAG Local, Fast, and Reliable
作者: Jan Strich, Adeline Scharfenberg, Chris Biemann, Martin Semmann
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-10-31
备注: Currently under review
💡 一句话要点
EncouRAGe:一个用于评估RAG系统本地化、快速性和可靠性的Python框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG系统 大型语言模型 评估框架 本地部署
📋 核心要点
- 现有RAG系统评估缺乏统一框架,难以实现科学可重复性和本地化部署。
- EncouRAGe框架通过模块化设计,提供类型清单、RAG工厂等组件,简化RAG系统开发与评估。
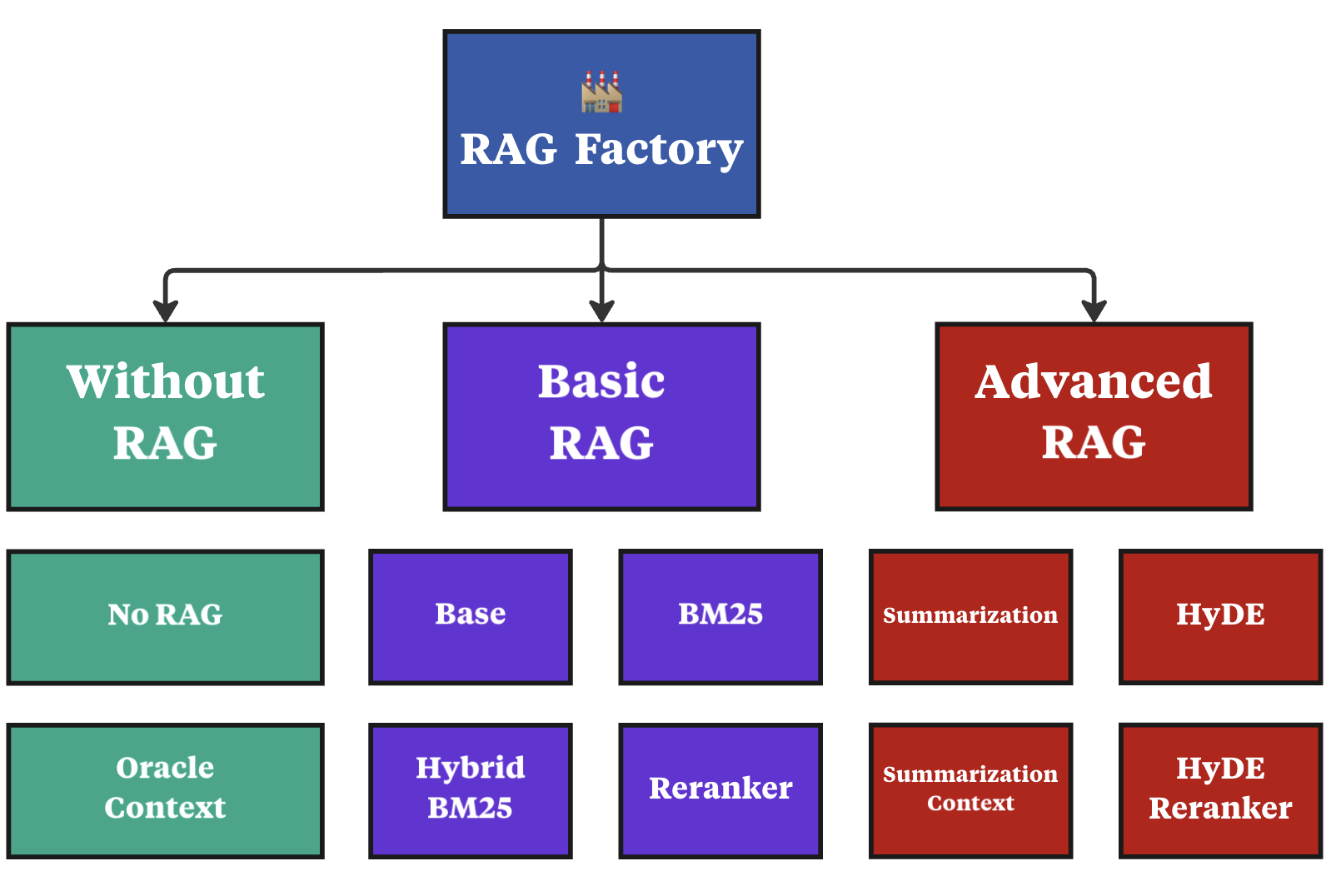
- 实验结果表明,RAG性能与Oracle Context存在差距,混合BM25方法表现最佳,重排序收益有限。
📝 摘要(中文)
本文介绍EncouRAGe,一个全面的Python框架,旨在简化使用大型语言模型(LLMs)和嵌入模型进行检索增强生成(RAG)系统的开发和评估。EncouRAGe包含五个模块化和可扩展的组件:类型清单、RAG工厂、推理、向量存储和指标,从而促进灵活的实验和可扩展的开发。该框架强调科学可重复性、多样化的评估指标和本地部署,使研究人员能够有效地评估RAG工作流程中的数据集。本文介绍了实现细节,并对包括2.5万个QA对和超过5.1万个文档的多个基准数据集进行了广泛的评估。结果表明,与Oracle Context相比,RAG仍然表现不佳,而混合BM25在所有四个数据集中始终取得最佳结果。我们进一步研究了重排序的效果,发现性能提升微乎其微,但响应延迟更高。
🔬 方法详解
问题定义:现有RAG系统的评估缺乏一个统一、可扩展且易于本地部署的框架。研究人员在评估RAG系统时,往往需要自行搭建评估环境,难以保证实验的可重复性和公平性。此外,缺乏多样化的评估指标,难以全面衡量RAG系统的性能。现有方法在评估RAG系统的检索和生成质量时存在局限性。
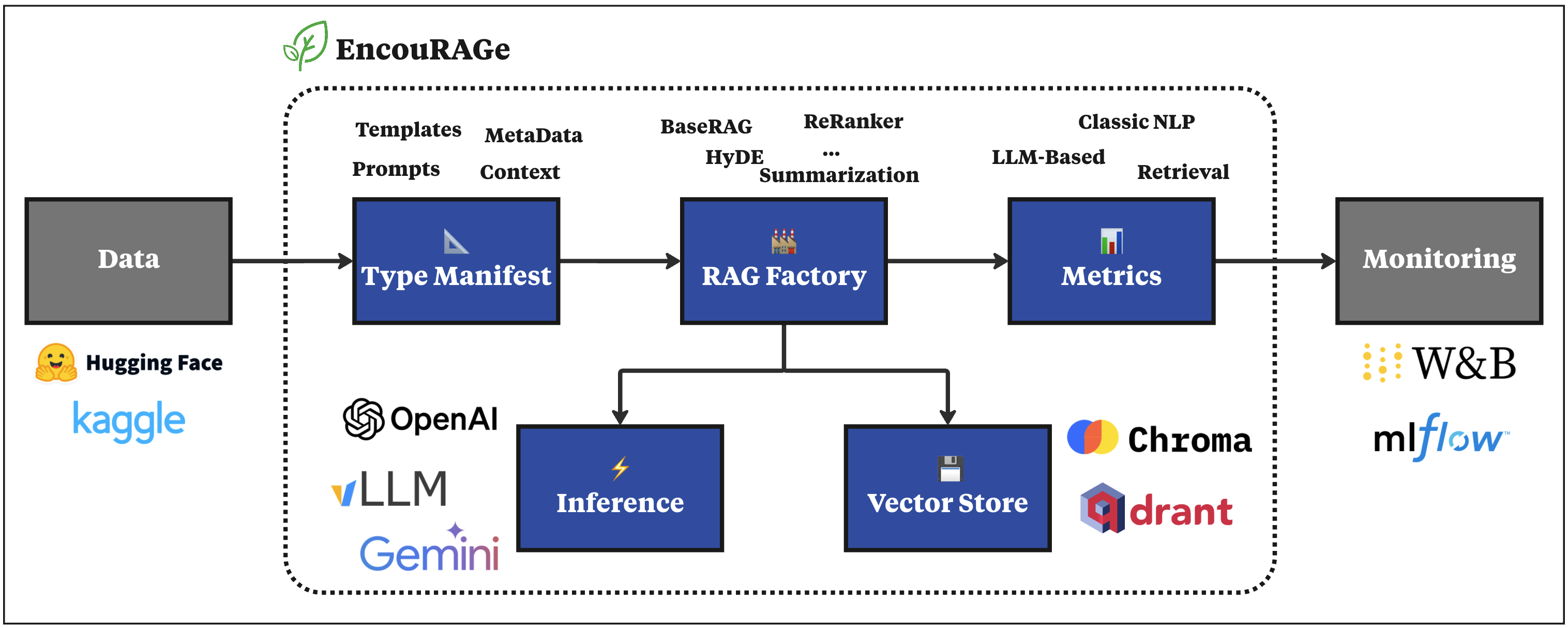
核心思路:EncouRAGe框架的核心思路是提供一个模块化、可扩展的Python框架,用于简化RAG系统的开发和评估流程。通过将RAG系统分解为类型清单、RAG工厂、推理、向量存储和指标等五个核心组件,EncouRAGe框架允许研究人员灵活地组合和定制RAG系统,并使用多样化的评估指标进行全面评估。
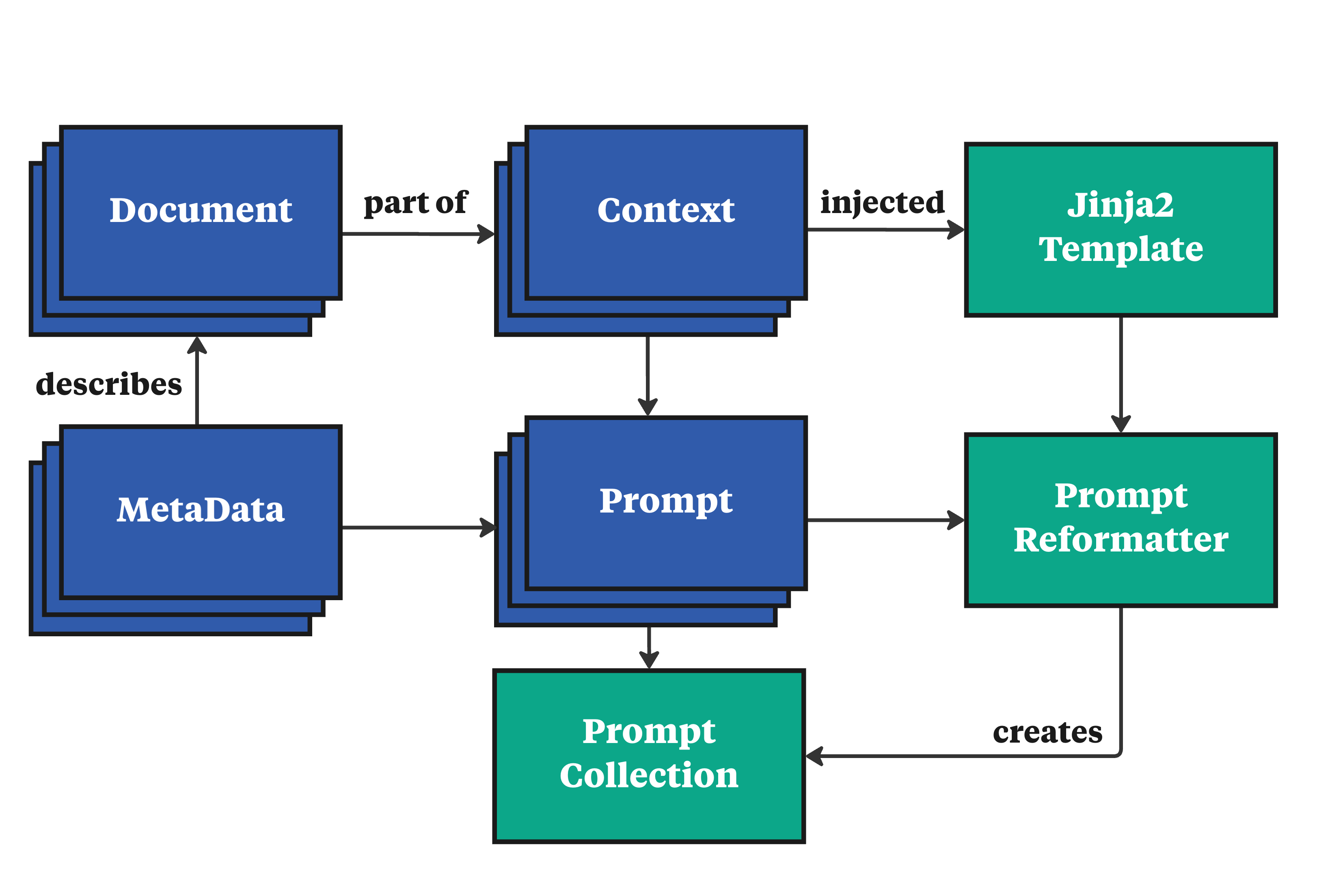
技术框架:EncouRAGe框架包含以下五个主要模块: 1. 类型清单 (Type Manifest):定义了RAG系统中使用的数据类型和接口。 2. RAG工厂 (RAG Factory):负责创建和配置RAG系统的各个组件。 3. 推理 (Inference):执行RAG系统的推理过程,包括检索和生成。 4. 向量存储 (Vector Store):存储文档的向量表示,用于快速检索相关文档。 5. 指标 (Metrics):提供多样化的评估指标,用于衡量RAG系统的性能。
关键创新:EncouRAGe框架的关键创新在于其模块化和可扩展的设计,以及对科学可重复性和本地部署的强调。通过模块化设计,研究人员可以轻松地组合和定制RAG系统,并使用不同的组件进行实验。对科学可重复性的强调,确保了实验结果的可靠性和可比性。本地部署的特性,使得研究人员可以在本地环境中评估RAG系统,无需依赖外部服务。
关键设计:EncouRAGe框架的关键设计包括: 1. 使用Python作为开发语言,方便研究人员使用和扩展。 2. 提供清晰的API接口,方便研究人员集成自定义的组件。 3. 支持多种向量存储,包括FAISS、Annoy等。 4. 提供多样化的评估指标,包括准确率、召回率、F1值等。 5. 强调本地部署,无需依赖外部服务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在多个基准数据集上,RAG系统的性能与Oracle Context相比仍有差距。混合BM25方法在所有四个数据集中始终取得最佳结果,表明其在检索相关文档方面的有效性。重排序虽然可以提高性能,但提升幅度有限,且会增加响应延迟。这些结果为RAG系统的优化提供了重要的参考。
🎯 应用场景
EncouRAGe框架可广泛应用于各种需要检索增强生成技术的场景,例如问答系统、文档摘要、知识图谱构建等。该框架可以帮助研究人员和开发人员快速构建和评估RAG系统,从而提高RAG系统的性能和效率。未来,EncouRAGe框架可以进一步扩展,支持更多的LLM和嵌入模型,并提供更多的评估指标。
📄 摘要(原文)
We introduce EncouRAGe, a comprehensive Python framework designed to streamline the development and evaluation of Retrieval-Augmented Generation (RAG) systems using Large Language Models (LLMs) and Embedding Models. EncouRAGe comprises five modular and extensible components: Type Manifest, RAG Factory, Inference, Vector Store, and Metrics, facilitating flexible experimentation and extensible development. The framework emphasizes scientific reproducibility, diverse evaluation metrics, and local deployment, enabling researchers to efficiently assess datasets within RAG workflows. This paper presents implementation details and an extensive evaluation across multiple benchmark datasets, including 25k QA pairs and over 51k documents. Our results show that RAG still underperforms compared to the Oracle Context, while Hybrid BM25 consistently achieves the best results across all four datasets. We further examine the effects of reranking, observing only marginal performance improvements accompanied by higher response latency.