Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning
作者: Marwa Abdulhai, Ryan Cheng, Donovan Clay, Tim Althoff, Sergey Levine, Natasha Jaques
分类: cs.CL, cs.AI
发布日期: 2025-10-31
💡 一句话要点
提出多轮强化学习框架,提升LLM在模拟人设对话中的一致性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人设一致性 多轮强化学习 对话生成 自动评估指标
📋 核心要点
- 现有LLM在模拟人设对话时,容易出现人设漂移、前后矛盾等问题,影响模拟的真实性和有效性。
- 提出基于多轮强化学习的框架,利用自动评估指标作为奖励信号,微调LLM以提升人设一致性。
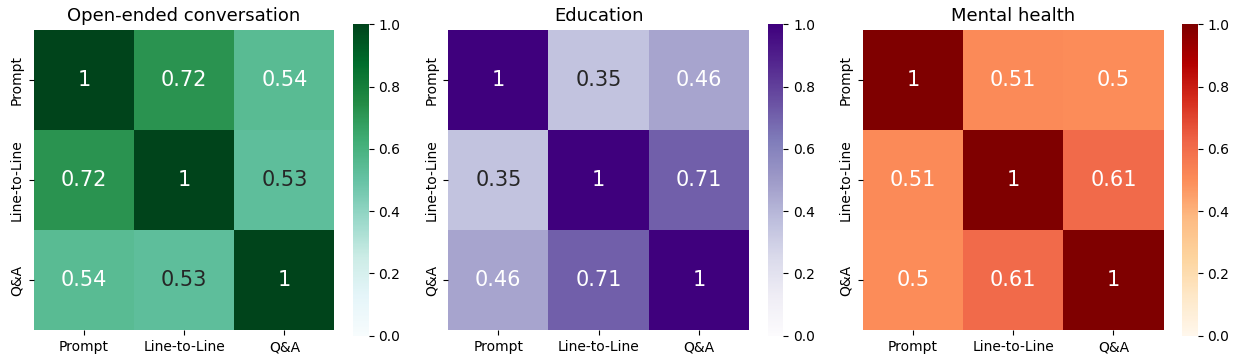
- 实验表明,该方法能显著降低LLM生成对话中的人设不一致性,提升超过55%,效果显著。
📝 摘要(中文)
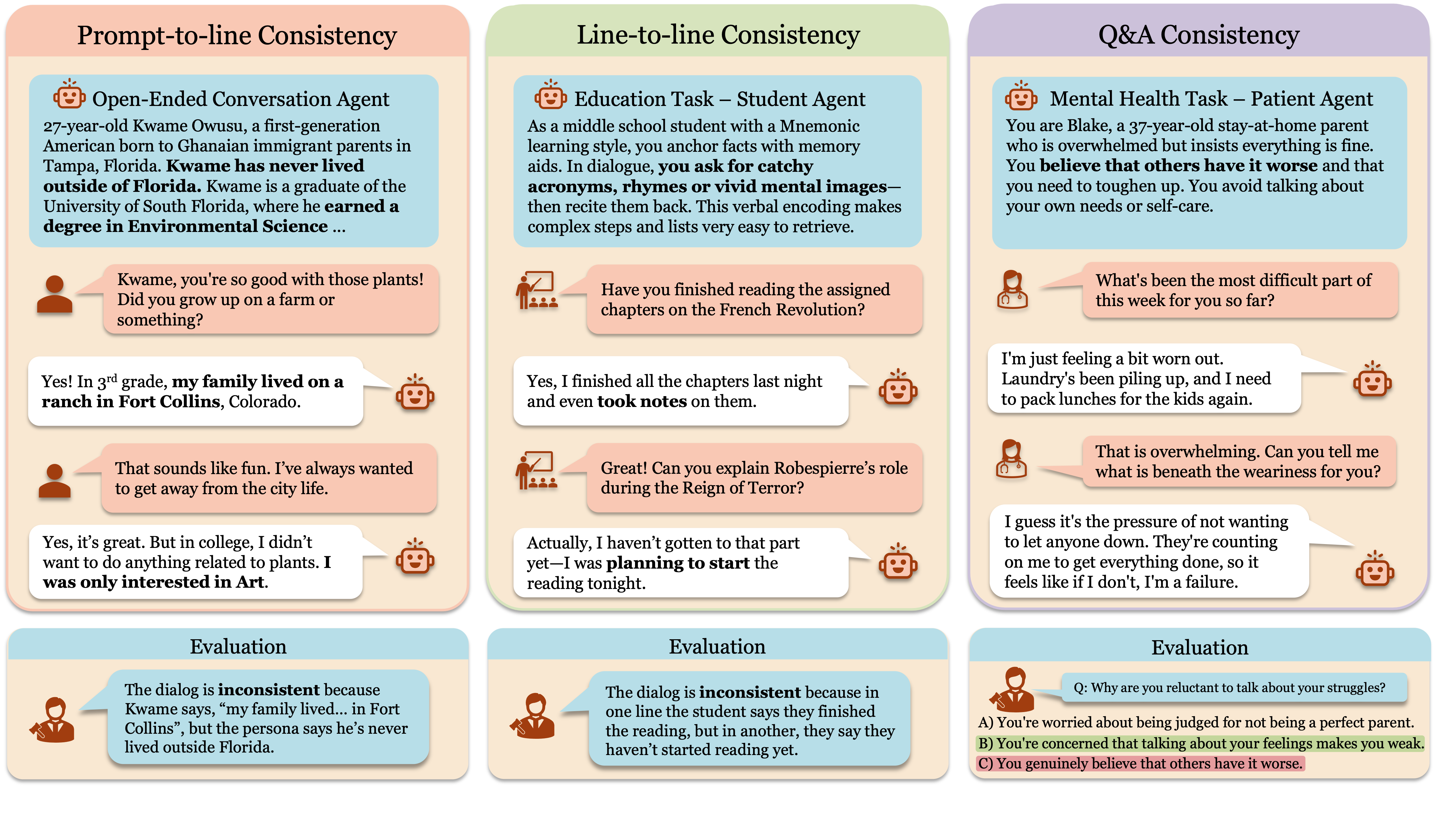
大型语言模型(LLMs)越来越多地被用于模拟交互环境中的人类用户,例如治疗、教育和社会角色扮演。虽然这些模拟能够实现AI代理的可扩展训练和评估,但现成的LLM通常会偏离其指定的人设,与之前的陈述相矛盾,或放弃符合角色的行为。本文提出了一个统一的框架,用于评估和改进LLM生成对话中的人设一致性。我们定义了三个自动指标:prompt-to-line一致性、line-to-line一致性和Q&A一致性,这些指标捕捉不同类型的人设漂移,并针对人工标注进行了验证。使用这些指标作为奖励信号,我们应用多轮强化学习来微调LLM,使其适应三种用户角色:患者、学生和社交聊天伙伴。我们的方法将不一致性降低了55%以上,从而产生了更连贯和忠实的模拟用户。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在模拟人类角色进行多轮对话时,出现的人设不一致问题。现有的LLM在长时间对话中,容易偏离预设的角色设定,产生与角色背景或历史对话不符的言论,导致模拟的真实性和可靠性下降。这种人设漂移会严重影响基于LLM的模拟在治疗、教育等领域的应用效果。
核心思路:论文的核心思路是利用多轮强化学习(RL)来微调LLM,使其在对话过程中保持人设一致性。通过定义自动评估指标来衡量人设一致性,并将这些指标作为强化学习的奖励信号,引导LLM生成更符合角色设定的对话内容。这种方法能够有效地纠正LLM在对话中出现的人设漂移现象。
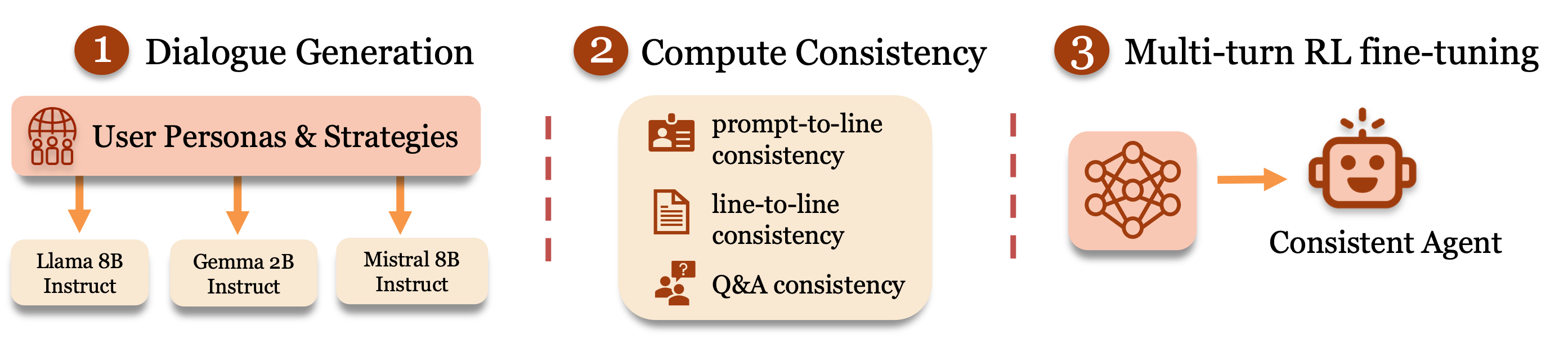
技术框架:整体框架包含以下几个主要模块:1)LLM对话生成模块:负责根据当前对话状态和角色设定生成下一句回复。2)自动评估指标模块:计算prompt-to-line一致性、line-to-line一致性和Q&A一致性三个指标,评估LLM生成回复的人设一致性。3)强化学习模块:使用评估指标作为奖励信号,通过策略梯度算法更新LLM的参数,使其生成更符合角色设定的回复。4)人工评估模块:对自动评估指标进行验证,确保其与人类判断一致。
关键创新:论文的关键创新在于提出了一个统一的框架,将自动评估指标和多轮强化学习相结合,用于提升LLM在模拟人设对话中的一致性。与传统的微调方法相比,该方法能够更有效地利用奖励信号,引导LLM学习到更稳定和一致的人设表达。此外,论文还提出了三种自动评估指标,能够全面地衡量LLM生成对话的人设一致性。
关键设计:在强化学习过程中,论文采用了策略梯度算法,目标是最大化累积奖励。奖励函数由三个自动评估指标加权求和构成,权重根据实验结果进行调整。具体而言,prompt-to-line一致性衡量当前回复与角色设定的匹配程度,line-to-line一致性衡量当前回复与历史对话的连贯性,Q&A一致性衡量LLM对角色相关问题的回答是否一致。这些指标的计算依赖于LLM自身的语言理解能力,无需额外的人工标注数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用多轮强化学习微调后的LLM,在人设一致性方面取得了显著提升,不一致性降低了超过55%。与未经过微调的LLM相比,微调后的LLM能够更好地保持角色设定,避免出现前后矛盾的言论。人工评估结果也验证了自动评估指标的有效性,表明该方法能够有效地提升LLM生成对话的质量。
🎯 应用场景
该研究成果可广泛应用于各种需要模拟人类用户的交互场景,例如:心理治疗模拟,帮助治疗师训练沟通技巧;教育领域,模拟不同类型的学生进行个性化教学;社交角色扮演,提供更真实和沉浸式的互动体验。通过提升LLM的人设一致性,可以提高模拟的有效性和可靠性,从而更好地服务于实际应用。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used to simulate human users in interactive settings such as therapy, education, and social role-play. While these simulations enable scalable training and evaluation of AI agents, off-the-shelf LLMs often drift from their assigned personas, contradict earlier statements, or abandon role-appropriate behavior. We introduce a unified framework for evaluating and improving persona consistency in LLM-generated dialogue. We define three automatic metrics: prompt-to-line consistency, line-to-line consistency, and Q&A consistency, that capture different types of persona drift and validate each against human annotations. Using these metrics as reward signals, we apply multi-turn reinforcement learning to fine-tune LLMs for three user roles: a patient, a student, and a social chat partner. Our method reduces inconsistency by over 55%, resulting in more coherent and faithful simulated users.