SpecAttn: Speculating Sparse Attention
作者: Harsh Shah
分类: cs.CL, cs.LG, eess.SY
发布日期: 2025-10-31
备注: Accepted to NeurIPS 2025 Workshop on Structured Probabilistic Inference & Generative Modeling
💡 一句话要点
SpecAttn:利用推测解码实现高效稀疏注意力机制,加速LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 推测解码 大型语言模型 模型加速 免训练 键值缓存 Transformer
📋 核心要点
- 自注意力机制的二次复杂度导致LLM推理效率低,尤其是在长文本场景下,成为模型部署的瓶颈。
- SpecAttn利用推测解码中草稿模型的注意力权重,预测目标模型的重要token,实现稀疏注意力,减少计算冗余。
- 实验表明,SpecAttn在显著降低键值缓存访问的同时,保持了较好的模型性能,优于现有稀疏注意力方法。
📝 摘要(中文)
大型语言模型(LLMs)在推理过程中面临显著的计算瓶颈,这主要是由于自注意力机制的二次复杂度,尤其是在上下文长度增加时。我们提出了SpecAttn,一种新颖的免训练方法,它可以无缝地与现有的推测解码技术集成,从而在预训练的Transformer中实现高效的稀疏注意力。我们的核心思想是利用草稿模型在推测解码期间已经计算出的注意力权重来识别目标模型的重要token,从而消除冗余计算,同时保持输出质量。SpecAttn采用了三个核心技术:基于KL散度的草稿模型和目标模型之间的层对齐,一种GPU优化的无排序算法,用于从草稿注意力模式中选择top-p token,以及由这些预测引导的动态键值缓存修剪。通过利用标准推测解码流程中已经执行的计算工作,SpecAttn实现了超过75%的键值缓存访问减少,同时在PG-19数据集上的困惑度仅增加了15.29%,显著优于现有的稀疏注意力方法。我们的方法表明,可以增强推测执行以提供近似验证,而不会显著降低性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)推理过程中自注意力机制带来的计算瓶颈问题。现有方法,特别是标准自注意力机制,其计算复杂度随上下文长度呈二次方增长,导致推理速度慢,资源消耗大。现有的稀疏注意力方法虽然能降低计算复杂度,但往往需要额外的训练或微调,且性能提升有限。
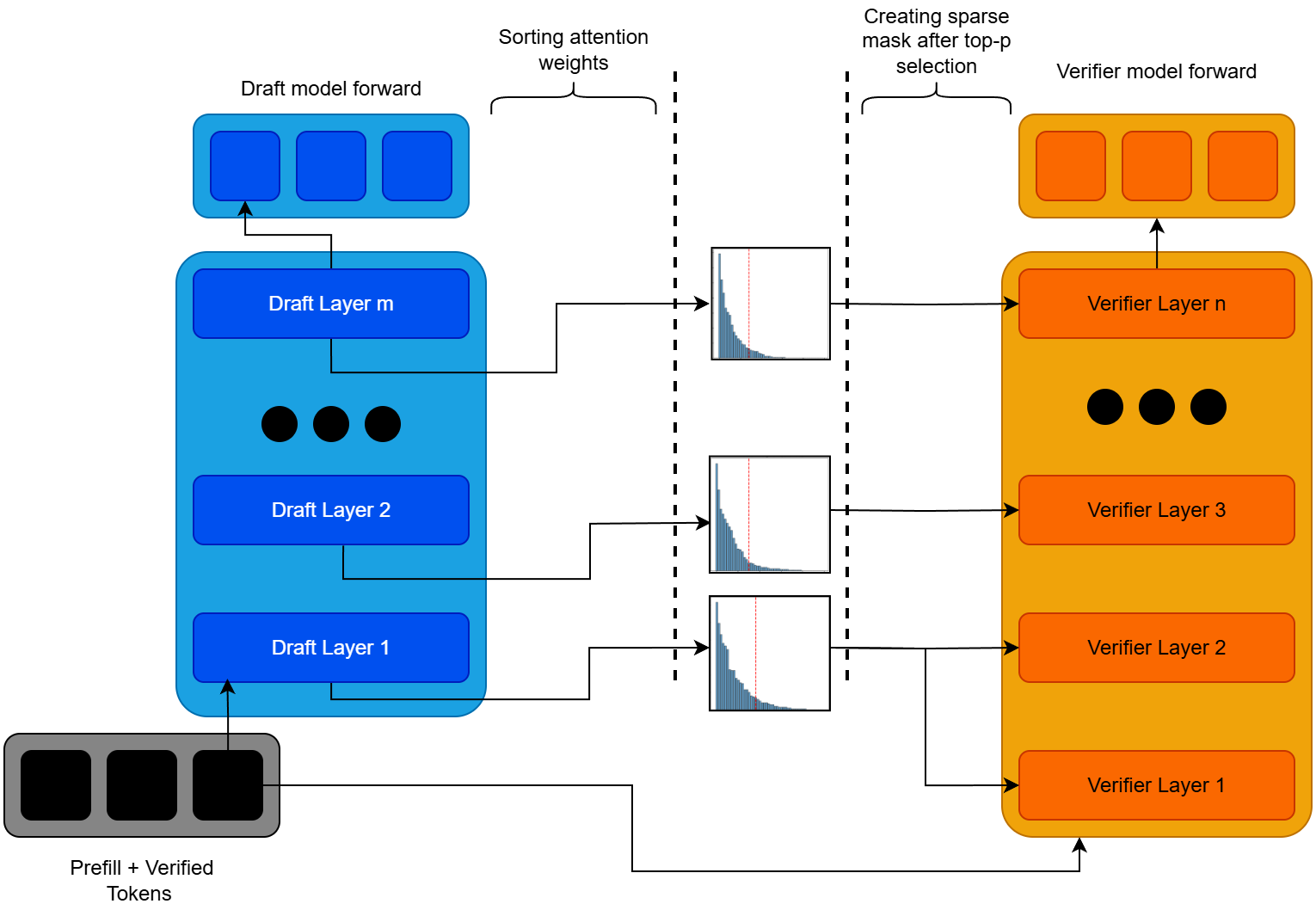
核心思路:SpecAttn的核心思路是利用推测解码(Speculative Decoding)过程中草稿模型(draft model)已经计算出的注意力权重,来指导目标模型(target model)进行稀疏注意力计算。通过预测哪些token对于目标模型来说是重要的,从而只对这些token进行精确的注意力计算,减少冗余计算。
技术框架:SpecAttn的整体框架基于推测解码流程。首先,使用草稿模型生成候选token序列。然后,SpecAttn利用草稿模型的注意力权重预测目标模型需要关注的token。具体来说,包括三个主要模块:1) 基于KL散度的层对齐,用于对齐草稿模型和目标模型的注意力分布;2) 一种GPU优化的无排序算法,用于从草稿注意力模式中选择top-p token;3) 动态键值缓存修剪,根据预测的重要token,只保留相关的键值对,减少内存访问。
关键创新:SpecAttn的关键创新在于它是一种免训练的稀疏注意力方法,可以直接应用于预训练的Transformer模型,无需额外的训练或微调。它充分利用了推测解码过程中已经存在的计算资源(草稿模型的注意力权重),避免了重复计算,提高了效率。此外,SpecAttn通过动态键值缓存修剪,进一步减少了内存访问,提升了推理速度。
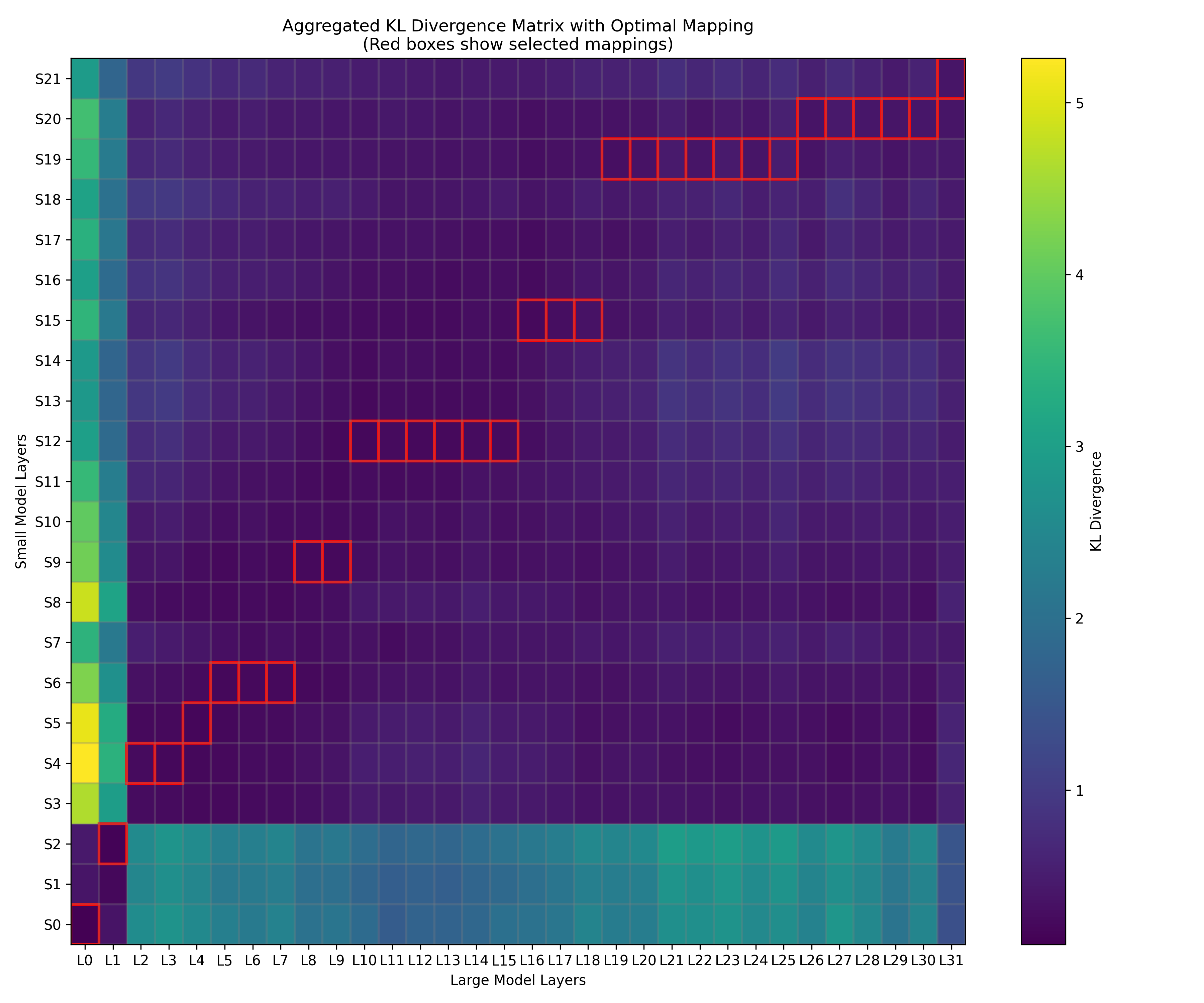
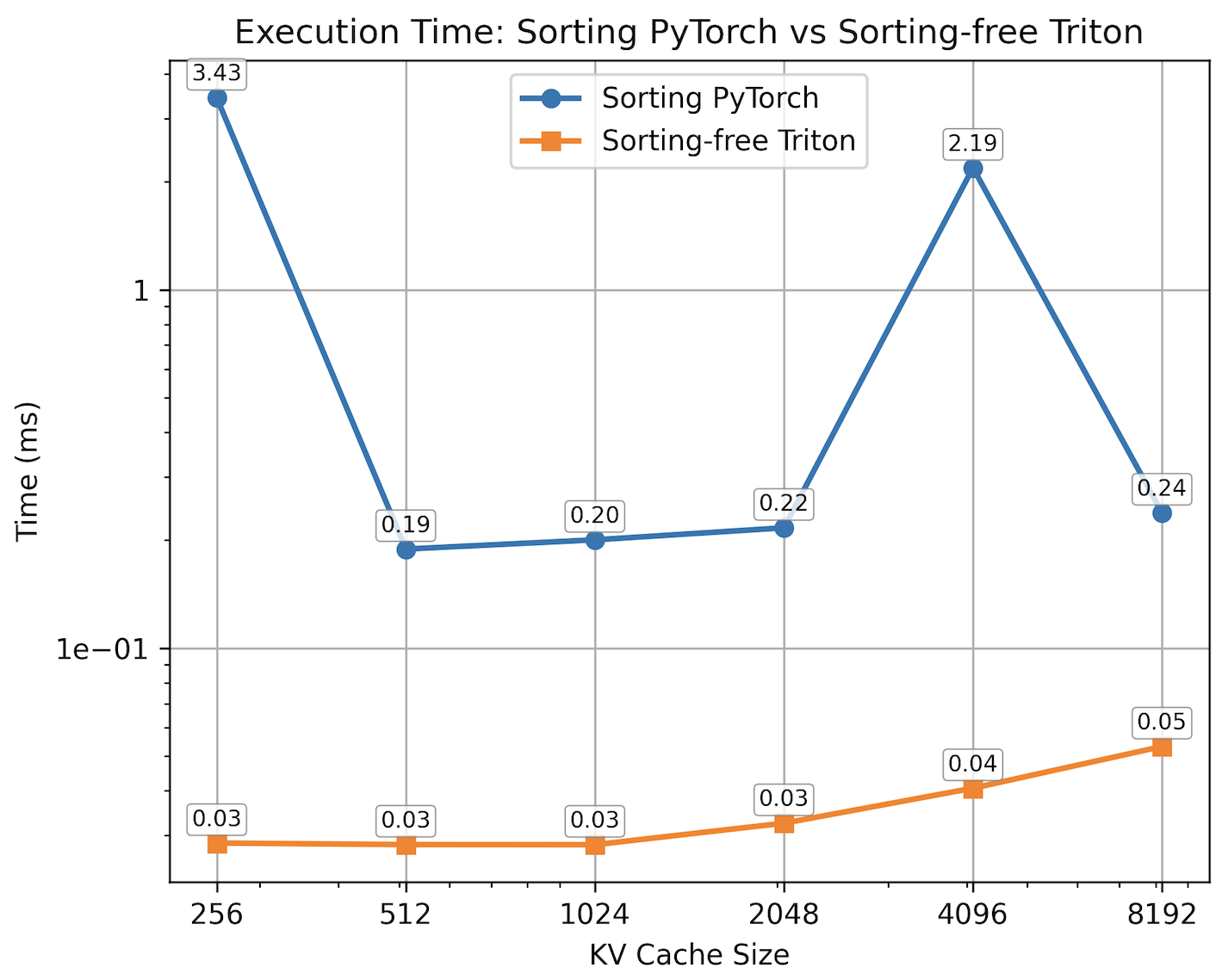
关键设计:SpecAttn的关键设计包括:1) 使用KL散度来衡量草稿模型和目标模型注意力分布的差异,并进行层对齐,确保草稿模型的注意力信息能够有效地传递给目标模型;2) 设计了一种GPU优化的无排序算法,用于快速选择top-p token,避免了排序操作带来的额外开销;3) 动态键值缓存修剪策略,根据预测的重要token,动态地更新键值缓存,只保留相关的键值对,减少内存占用和访问。
🖼️ 关键图片
📊 实验亮点
SpecAttn在PG-19数据集上实现了显著的性能提升。实验结果表明,SpecAttn能够减少超过75%的键值缓存访问,同时困惑度仅增加了15.29%。与现有的稀疏注意力方法相比,SpecAttn在性能和效率上都具有明显的优势。这些结果表明,SpecAttn是一种有效的稀疏注意力方法,可以显著加速LLM的推理过程。
🎯 应用场景
SpecAttn具有广泛的应用前景,可以应用于各种需要加速LLM推理的场景,例如:在线对话系统、文本生成、机器翻译等。通过降低计算复杂度和内存占用,SpecAttn可以使LLM更容易部署在资源受限的设备上,例如移动设备和边缘计算设备。此外,SpecAttn还可以用于加速LLM的训练过程,提高训练效率。
📄 摘要(原文)
Large Language Models (LLMs) face significant computational bottlenecks during inference due to the quadratic complexity of self-attention mechanisms, particularly as context lengths increase. We introduce SpecAttn, a novel training-free approach that seamlessly integrates with existing speculative decoding techniques to enable efficient sparse attention in pre-trained transformers. Our key insight is to exploit the attention weights already computed by the draft model during speculative decoding to identify important tokens for the target model, eliminating redundant computation while maintaining output quality. SpecAttn employs three core techniques: KL divergence-based layer alignment between draft and target models, a GPU-optimized sorting-free algorithm for top-p token selection from draft attention patterns, and dynamic key-value cache pruning guided by these predictions. By leveraging the computational work already performed in standard speculative decoding pipelines, SpecAttn achieves over 75% reduction in key-value cache accesses with a mere 15.29% increase in perplexity on the PG-19 dataset, significantly outperforming existing sparse attention methods. Our approach demonstrates that speculative execution can be enhanced to provide approximate verification without significant performance degradation.