MARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
作者: Qi Luo, Xiaonan Li, Yuxin Wang, Tingshuo Fan, Yuan Li, Xinchi Chen, Xipeng Qiu
分类: cs.CL
发布日期: 2025-10-31
💡 一句话要点
提出MARAG-R1,通过强化学习的多工具Agentic检索,提升LLM在复杂推理任务中的信息获取能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多工具检索 强化学习 大型语言模型 Agentic检索
📋 核心要点
- 现有RAG系统依赖单一检索器,限制了LLM对外部知识的全面获取,尤其是在需要语料库级别推理的任务中。
- MARAG-R1提出一种强化学习的多工具RAG框架,使LLM能动态协调多种检索机制,更广泛、精确地获取信息。
- 实验表明,MARAG-R1在GlobalQA、HotpotQA和2WikiMultiHopQA等任务上显著优于现有方法,达到新的SOTA。
📝 摘要(中文)
大型语言模型(LLMs)擅长推理和生成,但受限于静态预训练数据,导致事实不准确和对新信息的适应性较弱。检索增强生成(RAG)通过将LLMs与外部知识相结合来解决这个问题。然而,RAG的有效性关键取决于模型是否能充分访问相关信息。现有的RAG系统依赖于单一检索器和固定的top-k选择,限制了对语料库的狭窄和静态子集的访问。因此,这种单一检索器模式已成为全面外部信息获取的主要瓶颈,尤其是在需要语料库级别推理的任务中。为了克服这一限制,我们提出了MARAG-R1,一个强化学习的多工具RAG框架,使LLMs能够动态地协调多种检索机制,以实现更广泛和更精确的信息访问。MARAG-R1为模型配备了四种检索工具——语义搜索、关键词搜索、过滤和聚合——并通过一个两阶段的训练过程学习如何以及何时使用它们:监督微调,然后是强化学习。这种设计允许模型交错进行推理和检索,逐步收集足够的证据进行语料库级别的综合。在GlobalQA、HotpotQA和2WikiMultiHopQA上的实验表明,MARAG-R1显著优于强大的基线,并在语料库级别的推理任务中取得了新的state-of-the-art结果。
🔬 方法详解
问题定义:现有RAG方法依赖于单一检索器,无法充分利用多种检索策略,导致在需要复杂推理和多步信息整合的任务中表现不佳。痛点在于无法动态地根据任务需求选择合适的检索工具,限制了信息获取的广度和深度。
核心思路:MARAG-R1的核心思路是赋予LLM一个“智能体”的角色,使其能够根据当前任务状态,动态地选择和组合不同的检索工具,从而更有效地获取所需信息。通过强化学习,训练LLM学会如何以及何时使用这些工具,实现更灵活和高效的检索过程。
技术框架:MARAG-R1包含以下主要模块:1) LLM作为智能体,负责推理和决策;2) 四种检索工具:语义搜索、关键词搜索、过滤和聚合;3) 强化学习模块,用于训练LLM智能体。整体流程是:LLM首先根据当前问题进行初步推理,然后选择一个或多个检索工具获取相关信息,将检索结果与问题结合,再次推理并决定下一步行动,直到获得足够的信息来回答问题。
关键创新:MARAG-R1最重要的创新点在于引入了强化学习来优化多工具检索策略。与传统的固定检索流程不同,MARAG-R1允许LLM根据任务需求动态地调整检索策略,从而更有效地获取相关信息。这种Agentic检索方式能够更好地适应复杂推理任务的需求。
关键设计:MARAG-R1采用两阶段训练方法:首先使用监督微调来初始化LLM智能体,使其具备基本的检索能力;然后使用强化学习来优化检索策略。强化学习的目标是最大化奖励,奖励函数的设计考虑了回答的准确性和检索效率。具体而言,如果LLM能够正确回答问题,则获得正奖励;如果检索步骤过多,则受到惩罚。此外,论文还详细描述了四种检索工具的具体实现方式,例如语义搜索使用预训练的embedding模型,关键词搜索使用TF-IDF等。
🖼️ 关键图片
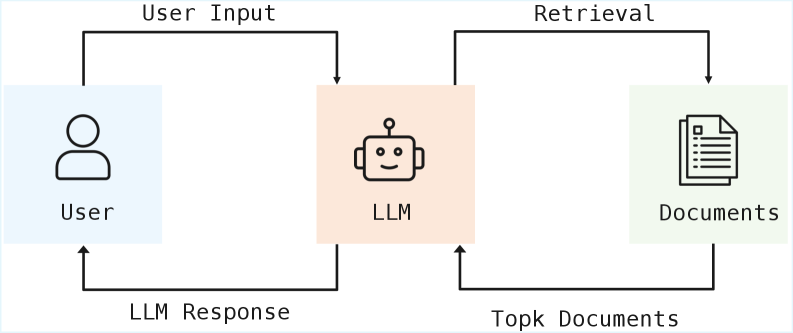
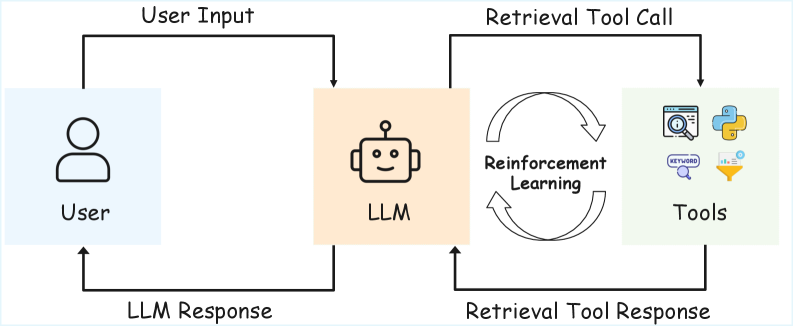
📊 实验亮点
MARAG-R1在GlobalQA、HotpotQA和2WikiMultiHopQA等语料库级别的推理任务上取得了显著的性能提升。例如,在HotpotQA上,MARAG-R1超越了所有现有模型,取得了新的state-of-the-art结果。实验结果表明,MARAG-R1能够更有效地利用外部知识,从而提升LLM在复杂推理任务中的表现。
🎯 应用场景
MARAG-R1具有广泛的应用前景,可应用于问答系统、知识图谱构建、智能客服等领域。尤其是在需要复杂推理和多步信息整合的场景下,MARAG-R1能够显著提升信息获取的效率和准确性,为用户提供更优质的服务。未来,该技术有望应用于更广泛的领域,例如科学研究、金融分析等。
📄 摘要(原文)
Large Language Models (LLMs) excel at reasoning and generation but are inherently limited by static pretraining data, resulting in factual inaccuracies and weak adaptability to new information. Retrieval-Augmented Generation (RAG) addresses this issue by grounding LLMs in external knowledge; However, the effectiveness of RAG critically depends on whether the model can adequately access relevant information. Existing RAG systems rely on a single retriever with fixed top-k selection, restricting access to a narrow and static subset of the corpus. As a result, this single-retriever paradigm has become the primary bottleneck for comprehensive external information acquisition, especially in tasks requiring corpus-level reasoning. To overcome this limitation, we propose MARAG-R1, a reinforcement-learned multi-tool RAG framework that enables LLMs to dynamically coordinate multiple retrieval mechanisms for broader and more precise information access. MARAG-R1 equips the model with four retrieval tools -- semantic search, keyword search, filtering, and aggregation -- and learns both how and when to use them through a two-stage training process: supervised fine-tuning followed by reinforcement learning. This design allows the model to interleave reasoning and retrieval, progressively gathering sufficient evidence for corpus-level synthesis. Experiments on GlobalQA, HotpotQA, and 2WikiMultiHopQA demonstrate that MARAG-R1 substantially outperforms strong baselines and achieves new state-of-the-art results in corpus-level reasoning tasks.