Diffuse Thinking: Exploring Diffusion Language Models as Efficient Thought Proposers for Reasoning
作者: Chenyang Shao, Sijian Ren, Fengli Xu, Yong Li
分类: cs.CL
发布日期: 2025-10-31
💡 一句话要点
提出Diffuse Thinking框架,利用扩散语言模型高效生成推理过程中的中间步骤,提升复杂推理任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 大型语言模型 推理 并行生成 中间步骤 协同推理 计算效率
📋 核心要点
- 大型语言模型在推理任务中计算开销大,自回归生成方式导致性能提升不明显。
- 利用扩散语言模型并行生成多样性推理步骤,降低计算负担,同时保证推理质量。
- 提出Diffuse Thinking框架,结合扩散模型和大型语言模型,在复杂推理任务上表现出色。
📝 摘要(中文)
近年来,大型语言模型(LLMs)取得了显著进展,测试时扩展法则持续增强其推理能力。通过系统评估和探索各种中间推理步骤,LLMs展现出生成深思熟虑的推理步骤的潜力,从而显著提高推理准确性。然而,LLMs的自回归生成范式导致推理性能随测试时计算资源的扩展并非最优,通常需要过多的计算开销来生成推理步骤,而性能提升却很小。相比之下,扩散语言模型(DLMs)可以通过单次前向传播中的并行去噪高效地生成多样化的样本,这启发我们利用它们来生成中间推理步骤,从而减轻与自回归生成相关的计算负担,同时保持质量。在这项工作中,我们提出了一个高效的协同推理框架,利用DLMs生成候选推理步骤,并利用LLMs评估其质量。在各种基准测试上的实验表明,我们的框架在复杂的推理任务中取得了强大的性能,为未来的研究提供了一个有希望的方向。我们的代码已在https://anonymous.4open.science/r/Diffuse-Thinking-EC60开源。
🔬 方法详解
问题定义:现有的大型语言模型在进行复杂推理时,依赖自回归的方式生成中间推理步骤(thoughts),这导致计算成本很高,并且推理性能的提升与计算资源的投入不成比例。换句话说,为了获得更好的推理结果,需要消耗大量的计算资源来生成更多的中间步骤,但收益却递减。
核心思路:论文的核心思路是利用扩散语言模型(DLMs)来高效地生成多样化的中间推理步骤。DLMs通过并行去噪过程,可以在单次前向传播中生成多个候选的推理步骤,从而显著降低计算成本。然后,利用大型语言模型(LLMs)来评估这些候选步骤的质量,选择最佳的步骤进行推理。
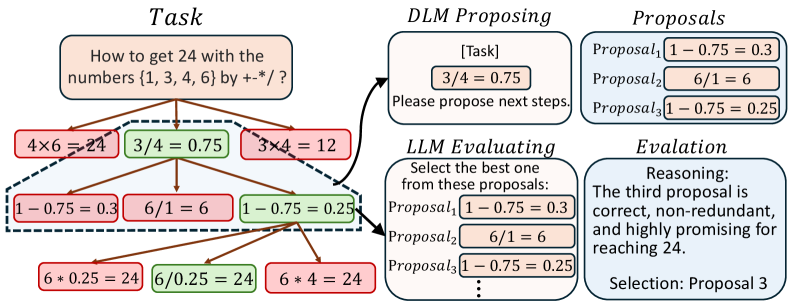
技术框架:Diffuse Thinking框架包含两个主要模块:扩散语言模型(DLM)和大型语言模型(LLM)。首先,DLM并行生成多个候选的中间推理步骤。然后,LLM对这些候选步骤进行评估,并选择质量最高的步骤。最终,选择的步骤被用于指导后续的推理过程。整个框架是一个协同推理的过程,DLM负责生成,LLM负责评估。
关键创新:该论文的关键创新在于将扩散语言模型引入到推理过程中,用于高效地生成中间推理步骤。与传统的自回归生成方法相比,扩散模型可以并行生成多个候选步骤,从而显著降低计算成本。此外,该框架还结合了大型语言模型的评估能力,确保生成的推理步骤的质量。
关键设计:论文中没有详细说明具体的参数设置、损失函数或网络结构等技术细节,这些细节可能依赖于所使用的具体扩散语言模型和大型语言模型。但是,关键的设计在于如何有效地利用扩散模型生成多样化的候选步骤,以及如何利用大型语言模型准确地评估这些步骤的质量。这可能涉及到一些特定的prompt工程或微调策略。
🖼️ 关键图片

📊 实验亮点
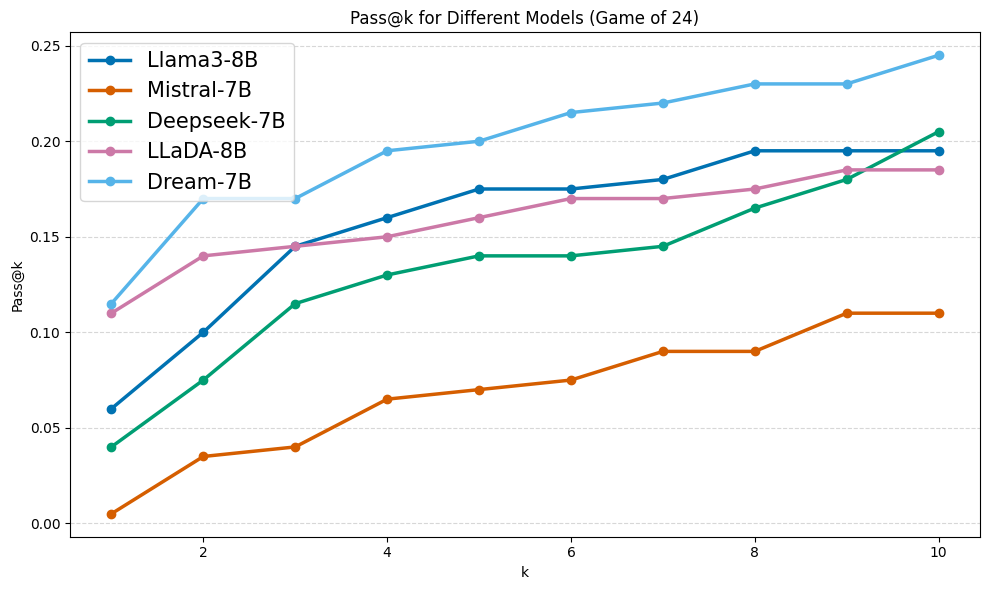
该论文提出的Diffuse Thinking框架在多个复杂推理基准测试中取得了显著的性能提升。具体的数据和对比基线需要在论文中查找,但总体而言,该框架证明了利用扩散语言模型生成中间推理步骤的有效性,并为未来的研究提供了一个有希望的方向。
🎯 应用场景
该研究成果可应用于需要复杂推理能力的各种场景,例如问答系统、智能助手、代码生成等。通过降低推理过程的计算成本,可以使这些应用在资源受限的环境中也能高效运行。此外,该方法还可以提高推理的准确性和可靠性,从而提升用户体验。
📄 摘要(原文)
In recent years, large language models (LLMs) have witnessed remarkable advancements, with the test-time scaling law consistently enhancing the reasoning capabilities. Through systematic evaluation and exploration of a diverse spectrum of intermediate thoughts, LLMs demonstrate the potential to generate deliberate reasoning steps, thereby substantially enhancing reasoning accuracy. However, LLMs' autoregressive generation paradigm results in reasoning performance scaling sub-optimally with test-time computation, often requiring excessive computational overhead to propose thoughts while yielding only marginal performance gains. In contrast, diffusion language models (DLMs) can efficiently produce diverse samples through parallel denoising in a single forward pass, inspiring us to leverage them for proposing intermediate thoughts, thereby alleviating the computational burden associated with autoregressive generation while maintaining quality. In this work, we propose an efficient collaborative reasoning framework, leveraging DLMs to generate candidate thoughts and LLMs to evaluate their quality. Experiments across diverse benchmarks demonstrate that our framework achieves strong performance in complex reasoning tasks, offering a promising direction for future research. Our code is open-source at https://anonymous.4open.science/r/Diffuse-Thinking-EC60.