ThoughtProbe: Classifier-Guided LLM Thought Space Exploration via Probing Representations
作者: Zijian Wang, Chang Xu
分类: cs.CL
发布日期: 2025-10-31
备注: EMNLP2025 main conference
💡 一句话要点
ThoughtProbe:通过探测表征,利用分类器引导LLM进行思维空间探索,提升推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理 表征学习 分类器 树搜索
📋 核心要点
- 现有方法在利用LLM进行推理时,难以有效探索和利用其隐藏的推理特征。
- ThoughtProbe利用分类器引导LLM进行树状响应空间探索,优先考虑高分候选答案。
- 实验表明,ThoughtProbe能有效覆盖并识别有效推理链,在算术推理任务上取得显著提升。
📝 摘要(中文)
本文介绍了一种新颖的推理时框架ThoughtProbe,它利用大型语言模型(LLM)的隐藏推理特征来提高其推理性能。与先前操纵隐藏表征以引导LLM生成的工作不同,我们将这些表征用作判别信号,以指导树状结构的响应空间探索。在每个节点扩展中,分类器充当评分和排序机制,通过优先考虑得分较高的候选者进行延续,从而有效地分配计算资源。完成树扩展后,我们从所有分支收集答案,形成候选答案池。然后,我们提出了一种分支聚合方法,通过聚合其CoT得分来边缘化所有支持分支,从而从池中识别出最佳答案。实验结果表明,我们的框架的全面探索不仅涵盖了有效的推理链,而且有效地识别了它们,从而在多个算术推理基准测试中取得了显着改进。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂推理任务中,难以有效利用其内部隐藏的推理过程和知识的问题。现有方法通常直接操纵LLM的生成过程,或者依赖于预训练阶段的知识,缺乏对推理过程的细粒度控制和探索,导致推理性能受限。
核心思路:ThoughtProbe的核心思路是将LLM的隐藏层表征作为判别信号,用于指导推理过程中的搜索。通过训练一个分类器来评估LLM在不同推理步骤中的状态,并利用该分类器来指导树状搜索,优先探索更有可能产生正确答案的分支。这种方法能够更有效地利用LLM的推理能力,并避免在无效的推理路径上浪费计算资源。
技术框架:ThoughtProbe的整体框架包括以下几个主要阶段:1) 节点扩展:基于LLM生成多个候选推理步骤;2) 分类器评分:使用训练好的分类器对每个候选步骤的隐藏层表征进行评分,评估其合理性;3) 树搜索:根据分类器评分,优先扩展得分较高的节点,构建推理树;4) 答案聚合:从所有分支收集答案,并根据分支的CoT得分进行加权平均,得到最终答案。
关键创新:ThoughtProbe的关键创新在于利用分类器来指导LLM的推理过程。与传统的基于生成的方法不同,ThoughtProbe通过显式地评估LLM的内部状态,并根据评估结果来调整推理策略,从而实现了更高效和可靠的推理。此外,ThoughtProbe还提出了一种分支聚合方法,能够有效地利用多个推理路径的信息,提高最终答案的准确性。
关键设计:分类器的训练是ThoughtProbe的关键。论文使用LLM的隐藏层表征作为输入,并使用监督学习方法训练分类器,使其能够区分正确的和错误的推理步骤。分类器的具体结构和训练数据选择对最终性能有重要影响。此外,树搜索的策略(例如,宽度优先搜索或深度优先搜索)以及分支聚合的权重计算方法也是需要仔细设计的关键参数。
🖼️ 关键图片

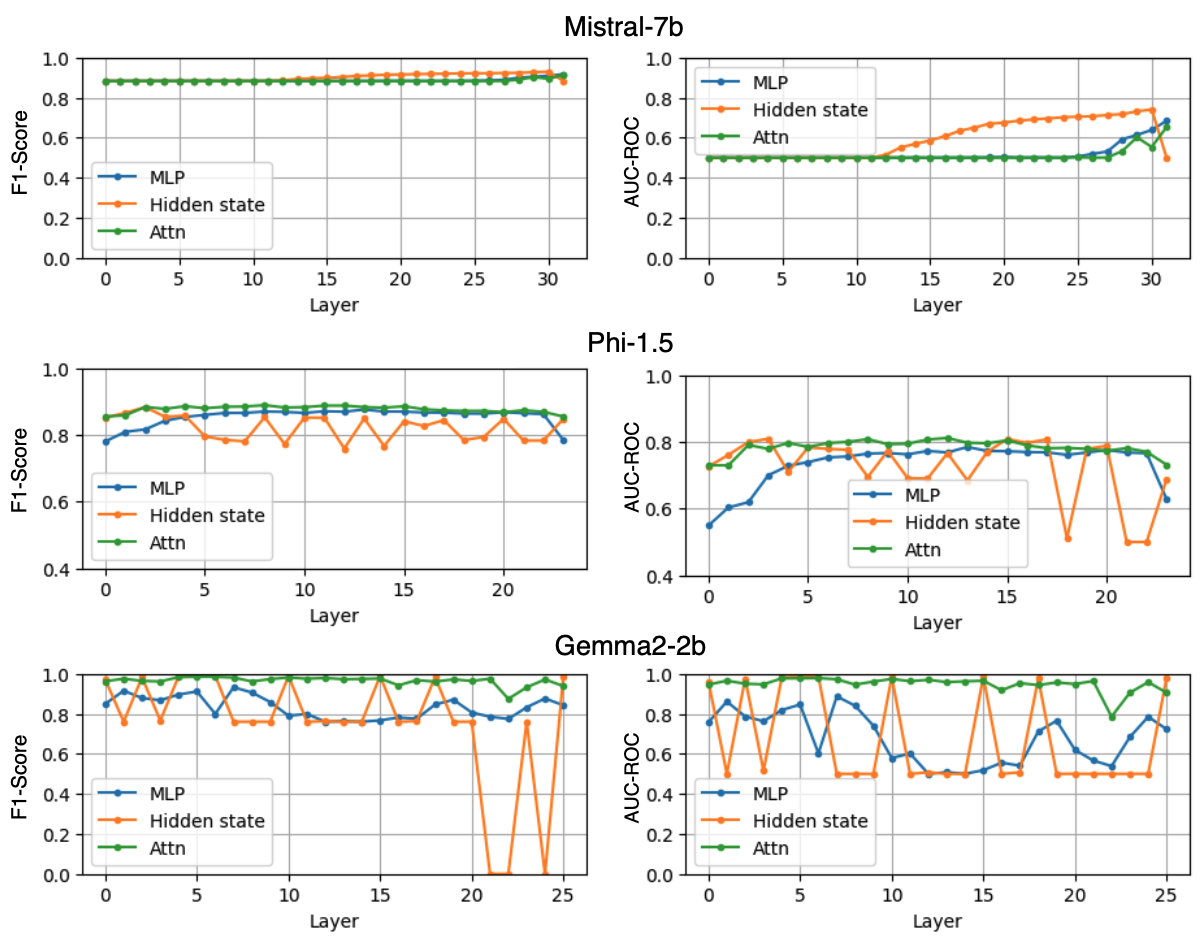
📊 实验亮点
实验结果表明,ThoughtProbe在多个算术推理基准测试中取得了显著的性能提升。例如,在GSM8K数据集上,ThoughtProbe的准确率比基线方法提高了超过10个百分点。此外,实验还表明,ThoughtProbe能够有效地识别和利用有效的推理链,从而提高了推理的可靠性。
🎯 应用场景
ThoughtProbe具有广泛的应用前景,可以应用于各种需要复杂推理的任务中,例如数学问题求解、常识推理、代码生成等。该方法可以提高LLM在这些任务中的准确性和效率,并有望推动人工智能在更广泛领域的应用。此外,ThoughtProbe还可以用于分析LLM的推理过程,帮助我们更好地理解LLM的工作原理。
📄 摘要(原文)
This paper introduces ThoughtProbe, a novel inference time framework that leverages the hidden reasoning features of Large Language Models (LLMs) to improve their reasoning performance. Unlike previous works that manipulate the hidden representations to steer LLM generation, we harness them as discriminative signals to guide the tree structured response space exploration. In each node expansion, a classifier serves as a scoring and ranking mechanism that efficiently allocates computational resources by prioritizing higher score candidates for continuation. After completing the tree expansion, we collect answers from all branches to form a candidate answer pool. We then propose a branch aggregation method that marginalizes over all supporting branches by aggregating their CoT scores, thereby identifying the optimal answer from the pool. Experimental results show that our framework's comprehensive exploration not only covers valid reasoning chains but also effectively identifies them, achieving significant improvements across multiple arithmetic reasoning benchmarks.