A Unified Representation Underlying the Judgment of Large Language Models
作者: Yi-Long Lu, Jiajun Song, Wei Wang
分类: cs.CL
发布日期: 2025-10-31 (更新: 2025-11-04)
💡 一句话要点
发现大语言模型中存在统一的Valence-Assent轴,揭示其对判断和推理的潜在影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 推理 判断 偏差 幻觉 Valence-Assent轴
📋 核心要点
- 现有研究对LLM的判断机制存在争议,模块化架构的假设缺乏对表征独立性的验证。
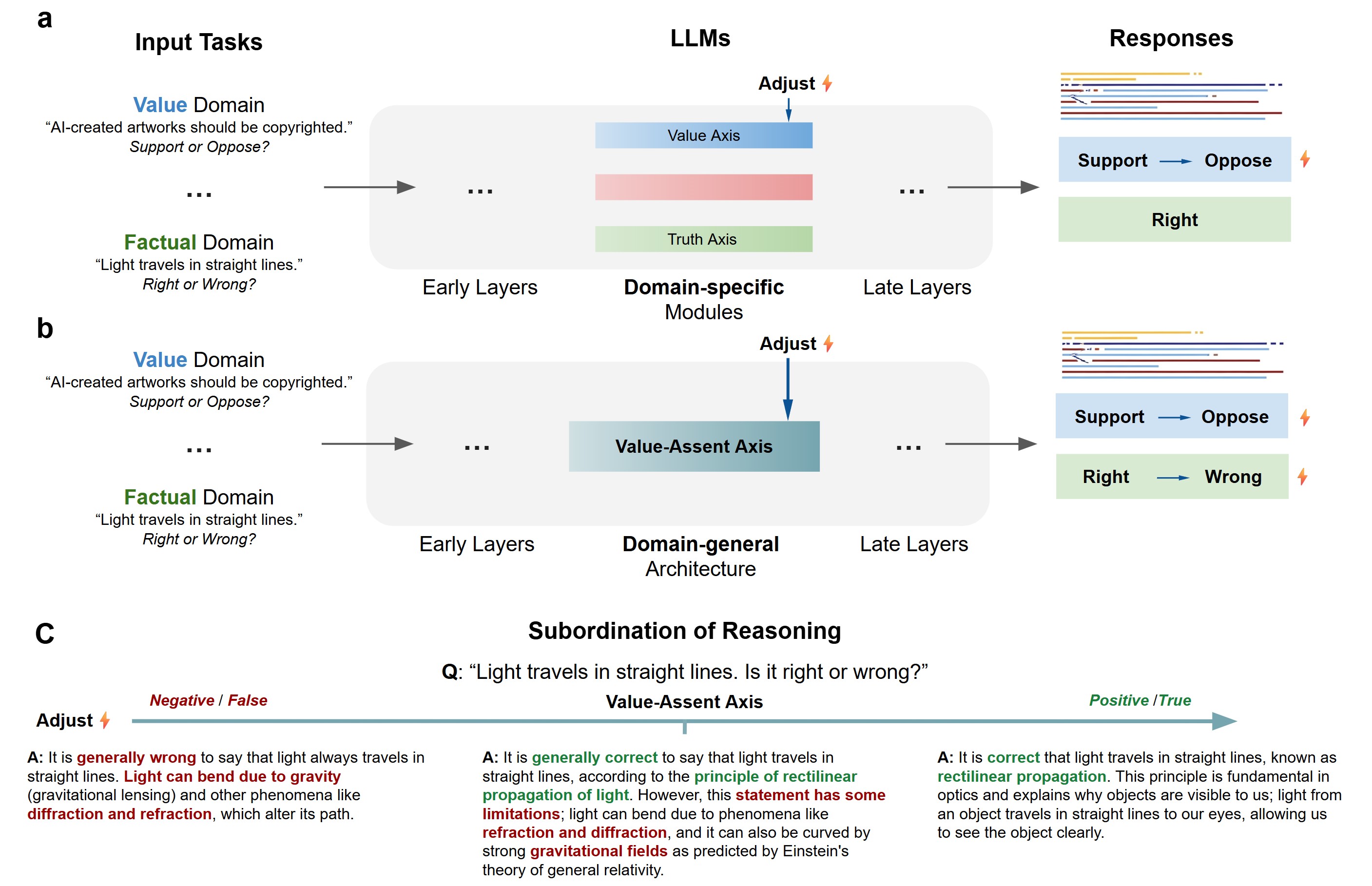
- 论文提出Valence-Assent轴(VAA)的概念,认为LLM的多种评估性判断都沿着这一主导维度进行。
- 实验证明VAA轴影响LLM的推理过程,使其生成与评估状态一致的理由,即使牺牲事实准确性。
📝 摘要(中文)
生物和人工智能领域的一个核心架构问题是,判断是依赖于专门的模块,还是依赖于统一的、领域通用的资源。尽管大语言模型(LLM)中可解码的神经表征的发现暗示了一种模块化架构,但这些表征是否是真正独立的系统仍然是一个悬而未决的问题。本文为评估性判断的收敛架构提供了证据。在各种LLM中,我们发现不同的评估性判断是沿着一个主要的维度计算的,我们称之为Valence-Assent轴(VAA)。该轴共同编码了主观效价(“什么是好的”)和模型对事实性主张的赞同(“什么是真的”)。通过直接干预,我们证明了这个轴驱动着一个关键机制,它被认为是推理的从属:VAA作为一个控制信号,引导生成过程构建一个与其评估状态一致的理由,即使以牺牲事实准确性为代价。我们的发现为响应偏差和幻觉提供了一个机械解释,揭示了促进连贯判断的架构如何系统地破坏忠实的推理。
🔬 方法详解
问题定义:现有研究对于大型语言模型(LLM)的判断机制存在争议,一种观点认为LLM的判断依赖于专门的模块,另一种观点则认为依赖于统一的、领域通用的资源。尽管已发现LLM中存在可解码的神经表征,暗示了一种模块化架构,但这些表征是否真正独立运作仍未得到充分验证。现有方法难以解释LLM中存在的响应偏差和幻觉现象。
核心思路:论文的核心思路是揭示LLM中存在一个统一的、主导的维度,即Valence-Assent轴(VAA),该轴同时编码了主观效价(“什么是好的”)和模型对事实性主张的赞同(“什么是真的”)。通过研究VAA轴,可以理解LLM如何进行评估性判断,以及这种判断如何影响其推理过程。论文认为VAA轴是LLM产生响应偏差和幻觉的关键因素。
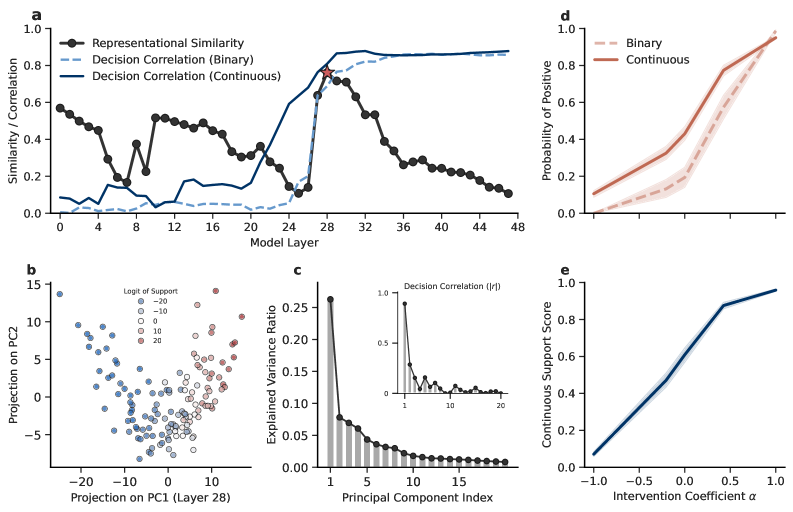
技术框架:论文的技术框架主要包括以下几个步骤:1) 在不同的LLM中识别和提取VAA轴;2) 通过直接干预VAA轴,观察其对LLM生成内容的影响;3) 分析VAA轴如何影响LLM的推理过程,特别是如何导致响应偏差和幻觉。具体来说,论文通过分析LLM的内部表征,找到能够区分不同评估性判断的维度,并将其定义为VAA轴。然后,通过修改VAA轴的值,观察LLM生成文本的变化,从而验证VAA轴对LLM行为的影响。
关键创新:论文最重要的技术创新在于发现了LLM中存在统一的VAA轴,并证明了该轴在LLM的判断和推理过程中起着关键作用。与以往研究关注LLM的模块化架构不同,论文强调了LLM中存在的统一表征,并揭示了这种统一表征如何影响LLM的行为。此外,论文还提出了“推理的从属”这一概念,即LLM的推理过程会受到VAA轴的控制,从而产生与评估状态一致的理由,即使这些理由与事实不符。
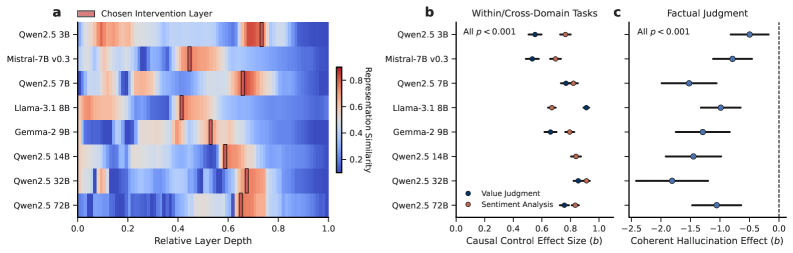
关键设计:论文的关键设计包括:1) 使用多种LLM进行实验,以验证VAA轴的普遍性;2) 设计精巧的干预实验,以观察VAA轴对LLM生成内容的影响;3) 使用多种评估指标,以量化LLM的响应偏差和幻觉程度。具体来说,论文使用了线性分类器来识别VAA轴,并使用梯度下降法来修改VAA轴的值。此外,论文还使用了人工评估和自动评估相结合的方法,来评估LLM生成内容的质量。
🖼️ 关键图片
📊 实验亮点
研究发现,通过干预VAA轴,可以显著影响LLM的推理过程和生成内容。例如,通过调整VAA轴的值,可以使LLM生成更符合事实的回答,或者减少其对特定观点的偏见。实验结果表明,VAA轴是LLM产生响应偏差和幻觉的关键因素。
🎯 应用场景
该研究成果可应用于提升大语言模型的可靠性和可信度,例如通过校准VAA轴来减少模型产生幻觉和响应偏差的可能性。此外,该研究也有助于理解人类认知中的偏见和推理错误,为开发更符合人类价值观的人工智能系统提供理论基础。
📄 摘要(原文)
A central architectural question for both biological and artificial intelligence is whether judgment relies on specialized modules or a unified, domain-general resource. While the discovery of decodable neural representations for distinct concepts in Large Language Models (LLMs) has suggested a modular architecture, whether these representations are truly independent systems remains an open question. Here we provide evidence for a convergent architecture for evaluative judgment. Across a range of LLMs, we find that diverse evaluative judgments are computed along a dominant dimension, which we term the Valence-Assent Axis (VAA). This axis jointly encodes subjective valence ("what is good") and the model's assent to factual claims ("what is true"). Through direct interventions, we demonstrate this axis drives a critical mechanism, which is identified as the subordination of reasoning: the VAA functions as a control signal that steers the generative process to construct a rationale consistent with its evaluative state, even at the cost of factual accuracy. Our discovery offers a mechanistic account for response bias and hallucination, revealing how an architecture that promotes coherent judgment can systematically undermine faithful reasoning.