MedCalc-Eval and MedCalc-Env: Advancing Medical Calculation Capabilities of Large Language Models
作者: Kangkun Mao, Jinru Ding, Jiayuan Chen, Mouxiao Bian, Ruiyao Chen, Xinwei Peng, Sijie Ren, Linyang Li, Jie Xu
分类: cs.CL, cs.AI
发布日期: 2025-10-31
🔗 代码/项目: GITHUB
💡 一句话要点
提出MedCalc-Eval和MedCalc-Env,提升大语言模型在医疗计算任务中的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗计算 大型语言模型 强化学习 临床决策支持 基准测试 定量推理 MedCalc-Eval MedCalc-Env
📋 核心要点
- 现有医疗LLM基准测试主要关注问答和描述性推理,忽略了临床决策中关键的定量计算能力。
- 论文提出MedCalc-Eval基准测试和MedCalc-Env强化学习环境,旨在提升LLM在医疗计算任务中的性能。
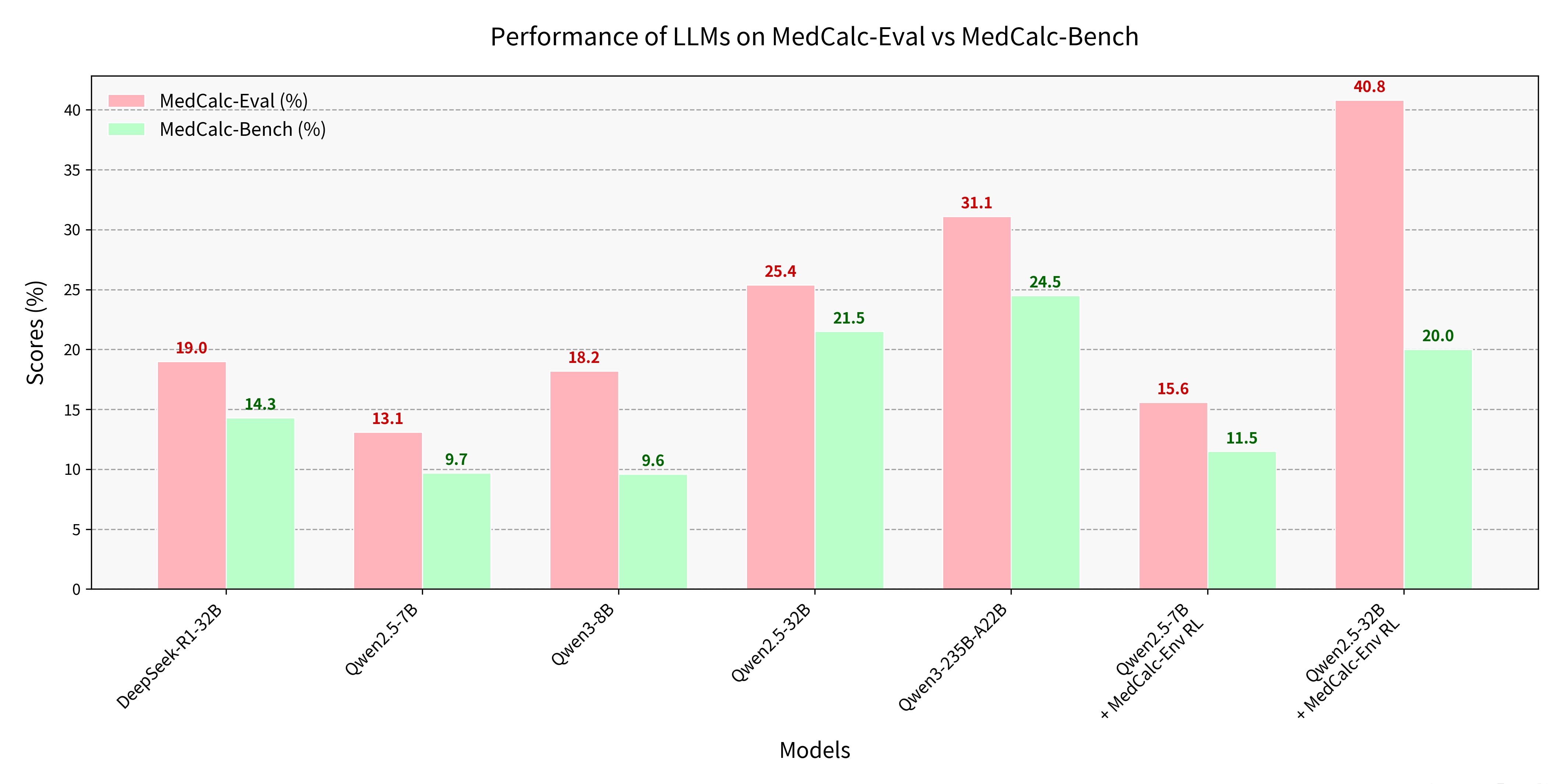
- 通过在MedCalc-Env中微调Qwen2.5-32B模型,在MedCalc-Eval上取得了显著提升,验证了方法的有效性。
📝 摘要(中文)
随着大型语言模型(LLMs)进入医疗领域,大多数基准测试侧重于问答或描述性推理,忽略了对临床决策至关重要的定量推理。现有的数据集,如MedCalc-Bench,涵盖的计算任务有限,且未能反映真实的计算场景。我们推出了MedCalc-Eval,这是评估LLMs医疗计算能力的最大基准,包含700多个任务,分为两类:基于公式(如Cockcroft-Gault、BMI、BSA)和基于规则的评分系统(如Apgar、格拉斯哥昏迷量表)。这些任务涵盖了内科、外科、儿科和心脏科等多个专科,提供了一个更广泛和更具挑战性的评估环境。为了提高性能,我们进一步开发了MedCalc-Env,这是一个基于InternBootcamp框架的强化学习环境,支持多步骤临床推理和规划。在该环境中微调Qwen2.5-32B模型,在MedCalc-Eval上取得了最先进的结果,在数值敏感性、公式选择和推理鲁棒性方面取得了显著提升。剩余的挑战包括单位转换、多条件逻辑和上下文理解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在医疗领域中定量推理能力不足的问题。现有方法主要集中在问答和描述性推理,忽略了临床决策中至关重要的计算能力。现有的医疗计算数据集覆盖范围有限,无法充分反映真实临床场景的复杂性。
核心思路:论文的核心思路是构建一个更全面、更具挑战性的医疗计算基准测试MedCalc-Eval,并设计一个强化学习环境MedCalc-Env,以训练LLM进行多步骤临床推理和规划,从而提升其医疗计算能力。通过强化学习,模型可以学习如何在复杂的临床场景中选择合适的公式和规则,并进行准确的计算。
技术框架:整体框架包括两个主要部分:MedCalc-Eval基准测试和MedCalc-Env强化学习环境。MedCalc-Eval提供了一个包含700多个医疗计算任务的数据集,涵盖了多种公式和评分系统。MedCalc-Env基于InternBootcamp框架,允许LLM在模拟的临床环境中进行多步骤推理和规划,并通过强化学习算法进行训练。
关键创新:论文的关键创新在于构建了一个大规模、多样化的医疗计算基准测试MedCalc-Eval,并提出了一个基于强化学习的训练环境MedCalc-Env。与传统的监督学习方法相比,强化学习能够更好地模拟真实的临床决策过程,并提升模型在复杂场景中的推理能力。
关键设计:MedCalc-Eval包含两类任务:基于公式的计算和基于规则的评分。MedCalc-Env使用Qwen2.5-32B模型作为基础模型,并采用强化学习算法进行微调。具体的强化学习算法和奖励函数设计未知,但目标是鼓励模型选择正确的公式和规则,并进行准确的计算。
🖼️ 关键图片


📊 实验亮点
通过在MedCalc-Env中微调Qwen2.5-32B模型,在MedCalc-Eval上取得了state-of-the-art的结果。具体性能提升数据未知,但论文强调在数值敏感性、公式选择和推理鲁棒性方面取得了显著提升。该结果表明,强化学习方法能够有效提升LLM在医疗计算任务中的性能。
🎯 应用场景
该研究成果可应用于开发更智能的临床决策支持系统,辅助医生进行诊断、治疗方案制定和风险评估。通过提升LLM的医疗计算能力,可以减少人为错误,提高医疗效率,并为患者提供更精准的个性化医疗服务。未来,该技术有望应用于远程医疗、智能健康管理等领域。
📄 摘要(原文)
As large language models (LLMs) enter the medical domain, most benchmarks evaluate them on question answering or descriptive reasoning, overlooking quantitative reasoning critical to clinical decision-making. Existing datasets like MedCalc-Bench cover few calculation tasks and fail to reflect real-world computational scenarios. We introduce MedCalc-Eval, the largest benchmark for assessing LLMs' medical calculation abilities, comprising 700+ tasks across two types: equation-based (e.g., Cockcroft-Gault, BMI, BSA) and rule-based scoring systems (e.g., Apgar, Glasgow Coma Scale). These tasks span diverse specialties including internal medicine, surgery, pediatrics, and cardiology, offering a broader and more challenging evaluation setting. To improve performance, we further develop MedCalc-Env, a reinforcement learning environment built on the InternBootcamp framework, enabling multi-step clinical reasoning and planning. Fine-tuning a Qwen2.5-32B model within this environment achieves state-of-the-art results on MedCalc-Eval, with notable gains in numerical sensitivity, formula selection, and reasoning robustness. Remaining challenges include unit conversion, multi-condition logic, and contextual understanding. Code and datasets are available at https://github.com/maokangkun/MedCalc-Eval.