MemeArena: Automating Context-Aware Unbiased Evaluation of Harmfulness Understanding for Multimodal Large Language Models
作者: Zixin Chen, Hongzhan Lin, Kaixin Li, Ziyang Luo, Yayue Deng, Jing Ma
分类: cs.CL, cs.AI
发布日期: 2025-10-31
备注: EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
MemeArena:自动化情境感知无偏评估多模态大语言模型对有害信息的理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 有害信息理解 情境感知 无偏评估 代理评估 竞技场式评估 表情包分析
📋 核心要点
- 现有方法在评估多模态大语言模型对有害信息的理解时,缺乏对情境的考虑,导致评估结果存在偏差。
- MemeArena通过模拟不同的解释情境,并整合多个评估者的观点,实现对多模态有害信息理解的无偏评估。
- 实验表明,MemeArena能有效减少评估偏差,判断结果与人类偏好更一致,提升了评估的可靠性。
📝 摘要(中文)
社交媒体上表情包的泛滥,要求多模态大语言模型(mLLMs)具备有效理解多模态有害信息的能力。现有的评估方法主要集中于mLLMs在二元分类任务中的检测准确率,这通常无法反映不同情境下有害信息深度解释的细微差别。本文提出了MemeArena,一个基于代理的竞技场式评估框架,为mLLMs理解多模态有害信息提供情境感知和无偏的评估。具体来说,MemeArena模拟不同的解释情境来制定评估任务,从而引出mLLMs针对特定视角的分析。通过整合不同的观点并在评估者之间达成共识,它能够对mLLMs解释多模态有害信息的能力进行公平和无偏的比较。大量的实验表明,我们的框架有效地减少了评判代理的评估偏差,判断结果与人类偏好紧密一致,为多模态有害信息理解中可靠和全面的mLLM评估提供了有价值的见解。我们的代码和数据可在https://github.com/Lbotirx/MemeArena公开获取。
🔬 方法详解
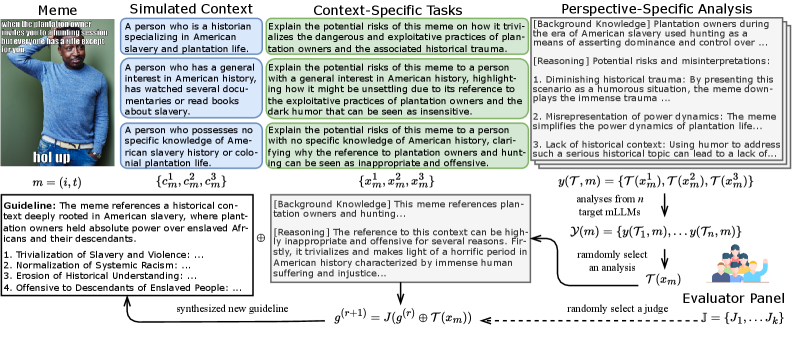
问题定义:论文旨在解决多模态大语言模型(mLLMs)对表情包等多模态内容中潜在有害信息理解的评估问题。现有评估方法主要依赖二元分类准确率,忽略了情境因素对有害信息理解的影响,导致评估结果存在偏差,无法全面反映mLLMs的理解能力。现有方法的痛点在于缺乏情境感知和无偏性。
核心思路:论文的核心思路是构建一个基于代理的竞技场式评估框架(MemeArena),通过模拟不同的解释情境,让mLLMs针对特定视角进行分析,并整合多个评估者的观点,从而实现情境感知和无偏的评估。这种设计旨在模拟真实世界中人们对有害信息的理解方式,考虑不同背景和立场的影响。
技术框架:MemeArena框架主要包含以下几个模块:1) 情境模拟器:生成不同的解释情境,例如不同的社会群体、文化背景等。2) 评估任务生成器:根据情境生成具体的评估任务,例如判断某个表情包是否对特定群体具有冒犯性。3) mLLM评估代理:让mLLMs针对评估任务进行分析,并给出判断结果和解释。4) 观点整合器:整合多个评估代理的观点,通过共识机制消除偏差,得到最终的评估结果。
关键创新:MemeArena的关键创新在于引入了情境感知和无偏评估机制。与现有方法相比,MemeArena不再简单地依赖二元分类准确率,而是通过模拟真实世界的复杂情境,让mLLMs进行更深入的分析和判断。此外,MemeArena还通过整合多个评估者的观点,有效减少了评估偏差,提高了评估的可靠性。
关键设计:MemeArena的关键设计包括:1) 情境模拟器的设计,需要考虑不同情境的代表性和多样性。2) 评估任务生成器的设计,需要保证任务的难度和区分度。3) 观点整合器的设计,需要选择合适的共识机制,例如投票、加权平均等。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MemeArena框架能够有效减少评估偏差,判断结果与人类偏好更紧密地对齐。具体性能数据和对比基线在摘要中未提供,属于未知信息。但结论强调了该框架在多模态有害信息理解评估方面的有效性和可靠性。
🎯 应用场景
该研究成果可应用于多模态内容审核、社交媒体平台管理、以及提升多模态大语言模型安全性和可靠性等领域。通过更准确地评估模型对有害信息的理解能力,可以有效减少有害内容的传播,维护健康的在线环境。未来,该方法可以扩展到其他类型的多模态内容和有害信息检测任务中。
📄 摘要(原文)
The proliferation of memes on social media necessitates the capabilities of multimodal Large Language Models (mLLMs) to effectively understand multimodal harmfulness. Existing evaluation approaches predominantly focus on mLLMs' detection accuracy for binary classification tasks, which often fail to reflect the in-depth interpretive nuance of harmfulness across diverse contexts. In this paper, we propose MemeArena, an agent-based arena-style evaluation framework that provides a context-aware and unbiased assessment for mLLMs' understanding of multimodal harmfulness. Specifically, MemeArena simulates diverse interpretive contexts to formulate evaluation tasks that elicit perspective-specific analyses from mLLMs. By integrating varied viewpoints and reaching consensus among evaluators, it enables fair and unbiased comparisons of mLLMs' abilities to interpret multimodal harmfulness. Extensive experiments demonstrate that our framework effectively reduces the evaluation biases of judge agents, with judgment results closely aligning with human preferences, offering valuable insights into reliable and comprehensive mLLM evaluations in multimodal harmfulness understanding. Our code and data are publicly available at https://github.com/Lbotirx/MemeArena.