Rating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks
作者: Rajarshi Haldar, Julia Hockenmaier
分类: cs.CL
发布日期: 2025-10-31
备注: Accepted at EMNLP 2025
💡 一句话要点
揭示LLM评判框架的自洽性问题:评分结果在不同运行中存在不一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自然语言生成 自动评估 内部一致性 NLG评估 LLM评判 自洽性 评分差异
📋 核心要点
- 现有NLG评估方法(如n-gram和embedding)与人类偏好存在差距,LLM评判虽有潜力但可靠性未知。
- 该研究通过实验揭示LLM评判在不同运行中评分存在显著不一致性,质疑其作为评估指标的可靠性。
- 论文量化了LLM评判在不同NLG任务中的不一致性,并探讨了在特定指导下使用LLM评判的可能性。
📝 摘要(中文)
随着自然语言生成(NLG)的广泛应用,对其进行有效评估变得越来越困难。近来,使用大型语言模型(LLM)来评估这些生成结果的方法越来越受欢迎,因为它们比传统的基于n-gram或嵌入的指标更符合人类偏好。我们的实验表明,LLM评判者在不同运行中分配的分数具有较低的内部一致性。这种差异使得他们的评分不一致,在最坏的情况下几乎是任意的,因此难以衡量他们的判断实际上有多好。我们量化了不同NLG任务和基准测试中这种不一致性,并研究在适当的指导下,明智地使用LLM评判者是否仍然有用。
🔬 方法详解
问题定义:论文关注的是使用大型语言模型(LLM)作为NLG系统评判者时,其评分结果的可靠性和一致性问题。现有的基于n-gram或embedding的评估指标无法很好地反映人类的偏好,而LLM评判被认为更符合人类直觉。然而,LLM评判的自洽性,即同一模型对同一NLG结果在不同运行中给出相似评分的能力,尚未得到充分验证,这直接影响了其作为评估指标的有效性。
核心思路:论文的核心思路是通过实验来量化LLM评判在不同运行中的评分差异,从而评估其内部一致性(intra-rater reliability)。如果LLM评判对同一结果的评分波动很大,则说明其作为评估指标的可靠性较低。论文旨在揭示这种不一致性,并探讨在何种条件下LLM评判才能提供有意义的评估结果。
技术框架:论文采用实验研究的方法,主要流程包括:1) 选择不同的NLG任务和基准数据集;2) 使用LLM作为评判者,对NLG模型生成的文本进行评分;3) 多次运行评分过程,记录每次运行的结果;4) 分析不同运行之间的评分差异,计算内部一致性指标(具体指标未知);5) 探讨在特定指导或约束下,LLM评判是否能提高一致性。
关键创新:论文的关键创新在于首次系统性地研究了LLM评判的自洽性问题,并量化了其在不同NLG任务中的不一致性。这挑战了LLM评判作为可靠评估指标的假设,并为未来如何更有效地使用LLM进行NLG评估提供了新的视角。
关键设计:论文的关键设计在于实验设置,需要控制多种因素以确保结果的有效性。这些因素可能包括:选择具有代表性的NLG任务和数据集;选择合适的LLM作为评判者(具体模型未知);设计清晰明确的评分标准;多次独立运行评分过程;选择合适的统计指标来量化评分差异(具体指标未知)。此外,论文可能还探讨了不同的prompting策略或约束条件,以提高LLM评判的一致性。
🖼️ 关键图片


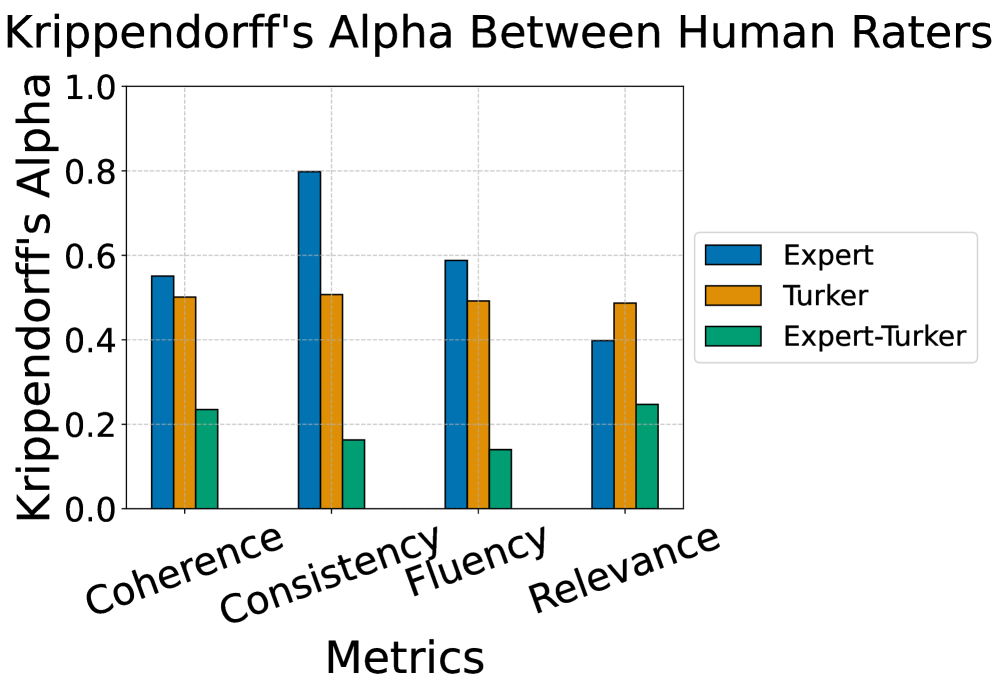
📊 实验亮点
论文通过实验证明,LLM评判在不同运行中对同一NLG结果的评分存在显著差异,表明其内部一致性较低。具体性能数据未知,但研究结果强调了LLM评判作为评估指标的局限性。论文还探讨了在特定指导下使用LLM评判的可能性,但具体提升幅度未知。该研究为未来改进LLM评判方法提供了重要启示。
🎯 应用场景
该研究成果对NLG系统的开发和评估具有重要意义。它可以帮助研究人员和开发者更理性地看待LLM评判的价值,避免盲目依赖不稳定的评估指标。通过深入理解LLM评判的局限性,可以探索更可靠的NLG评估方法,从而推动NLG技术的进步。此外,该研究也为其他领域中LLM的应用提供了借鉴,例如在文本摘要、机器翻译等任务中,LLM的评估能力也可能存在类似的自洽性问题。
📄 摘要(原文)
As Natural Language Generation (NLG) continues to be widely adopted, properly assessing it has become quite difficult. Lately, using large language models (LLMs) for evaluating these generations has gained traction, as they tend to align more closely with human preferences than conventional n-gram or embedding-based metrics. In our experiments, we show that LLM judges have low intra-rater reliability in their assigned scores across different runs. This variance makes their ratings inconsistent, almost arbitrary in the worst case, making it difficult to measure how good their judgments actually are. We quantify this inconsistency across different NLG tasks and benchmarks and see if judicious use of LLM judges can still be useful following proper guidelines.