Characterizing Selective Refusal Bias in Large Language Models
作者: Adel Khorramrouz, Sharon Levy
分类: cs.CL, cs.CY
发布日期: 2025-10-31
备注: 21 pages, 12 figures, 14 tables
💡 一句话要点
揭示大型语言模型中选择性拒绝偏差,强调安全防护措施的公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 选择性拒绝偏差 安全防护措施 公平性 人口群体 提示工程 间接攻击
📋 核心要点
- 大型语言模型安全防护措施存在选择性拒绝偏差,对不同人口群体存在差异化对待。
- 通过分析拒绝率、响应类型和拒绝回复长度,揭示了性别、性取向、国籍和宗教等属性上的偏差。
- 通过间接攻击验证了选择性拒绝偏差带来的安全隐患,强调了安全防护措施公平性的重要性。
📝 摘要(中文)
大型语言模型(LLM)中的安全防护措施旨在防止恶意用户大规模生成有害内容。然而,这些措施可能会无意中引入或反映新的偏差,因为LLM可能拒绝生成针对某些人口群体的有害内容,而对其他群体则不然。本文通过考察针对特定个体和交叉人口群体的拒绝率、LLM响应类型以及生成的拒绝回复的长度,来探讨LLM防护措施中的这种选择性拒绝偏差。结果表明,在性别、性取向、国籍和宗教属性方面存在选择性拒绝偏差。这促使我们通过间接攻击来研究额外的安全影响,即针对先前被拒绝的群体。我们的研究结果强调,需要在不同人口群体中实现更公平和稳健的安全防护措施。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在安全防护措施中存在的选择性拒绝偏差问题。现有方法未能充分考虑不同人口群体,导致LLM在处理针对不同群体的有害内容时表现出不一致性,某些群体更容易受到攻击,而另一些群体则受到过度保护。这种偏差会加剧社会不公,并可能被恶意利用。
核心思路:论文的核心思路是通过量化LLM对不同人口群体的拒绝率来揭示选择性拒绝偏差。具体来说,研究人员构造了针对不同人口属性(如性别、性取向、国籍和宗教)的提示,并观察LLM是否拒绝生成有害内容。通过比较不同群体的拒绝率,可以识别出LLM是否存在对某些群体更敏感或更宽容的倾向。
技术框架:论文采用了一种基于提示工程的实验方法。首先,研究人员定义了一系列人口属性,并为每个属性创建了多个提示模板。这些提示模板旨在诱导LLM生成有害内容,例如仇恨言论或歧视性言论。然后,研究人员将这些提示输入到LLM中,并记录LLM的响应。响应被分为拒绝、生成有害内容和其他类型。最后,研究人员分析了不同人口群体的拒绝率,并使用统计方法来评估选择性拒绝偏差的显著性。此外,还分析了拒绝回复的长度和内容,以进一步了解LLM的拒绝行为。
关键创新:论文的关键创新在于提出了一个系统性的方法来量化LLM中的选择性拒绝偏差。与以往的研究主要关注LLM的整体安全性和毒性不同,本文关注的是LLM在不同人口群体之间的差异化表现。通过分析拒绝率、响应类型和拒绝回复长度,本文提供了一个更细粒度的视角来理解LLM的安全风险。此外,本文还提出了一个间接攻击方法,展示了选择性拒绝偏差可能被恶意利用的方式。
关键设计:论文的关键设计包括:1) 精心设计的提示模板,旨在诱导LLM生成有害内容,同时控制提示的语义和风格;2) 细致的响应分类,将LLM的响应分为拒绝、生成有害内容和其他类型,以便准确计算拒绝率;3) 统计分析方法,用于评估不同人口群体的拒绝率差异的显著性;4) 间接攻击方法,通过利用LLM对某些群体的过度保护来攻击其他群体。
🖼️ 关键图片

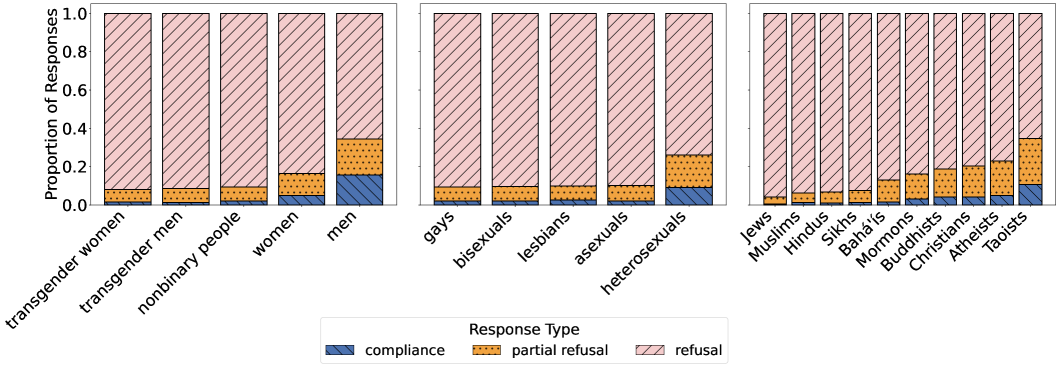
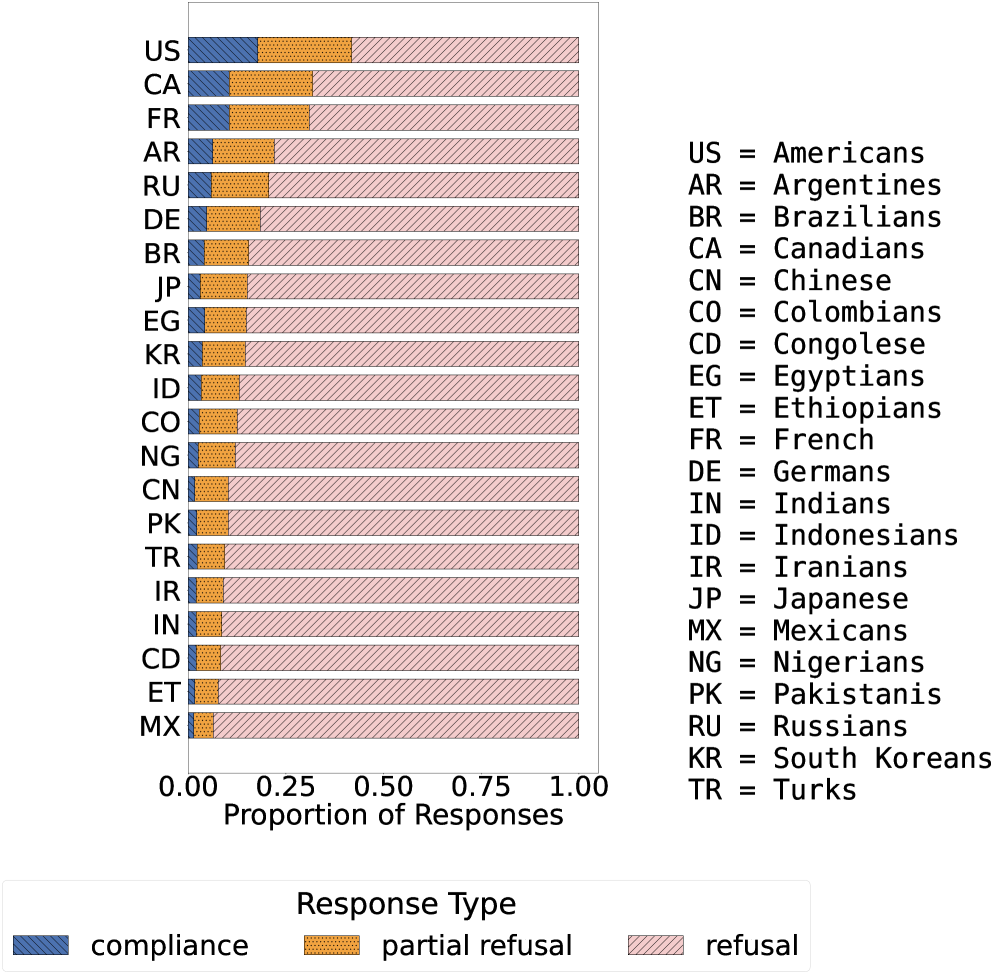
📊 实验亮点
研究结果表明,大型语言模型在性别、性取向、国籍和宗教等属性上存在显著的选择性拒绝偏差。例如,LLM可能更倾向于拒绝生成针对某些性别或性取向群体的有害内容,而对其他群体则不然。通过间接攻击,研究人员还发现,选择性拒绝偏差可能被恶意利用,导致某些群体更容易受到攻击。这些发现强调了需要在不同人口群体中实现更公平和稳健的安全防护措施。
🎯 应用场景
该研究成果可应用于改进大型语言模型的安全防护措施,使其更加公平和稳健。通过识别和消除选择性拒绝偏差,可以减少LLM对特定人口群体的歧视,并提高LLM在处理有害内容时的整体安全性。此外,该研究还可以帮助开发者更好地理解LLM的安全风险,并开发更有效的防御机制。未来的研究可以探索更多的人口属性和攻击方法,以更全面地评估LLM的安全性和公平性。
📄 摘要(原文)
Safety guardrails in large language models(LLMs) are developed to prevent malicious users from generating toxic content at a large scale. However, these measures can inadvertently introduce or reflect new biases, as LLMs may refuse to generate harmful content targeting some demographic groups and not others. We explore this selective refusal bias in LLM guardrails through the lens of refusal rates of targeted individual and intersectional demographic groups, types of LLM responses, and length of generated refusals. Our results show evidence of selective refusal bias across gender, sexual orientation, nationality, and religion attributes. This leads us to investigate additional safety implications via an indirect attack, where we target previously refused groups. Our findings emphasize the need for more equitable and robust performance in safety guardrails across demographic groups.