Reasoning Up the Instruction Ladder for Controllable Language Models
作者: Zishuo Zheng, Vidhisha Balachandran, Chan Young Park, Faeze Brahman, Sachin Kumar
分类: cs.CL, cs.AI
发布日期: 2025-10-30 (更新: 2025-12-01)
💡 一句话要点
提出VerIH数据集和强化学习方法,提升LLM指令层级推理能力和安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令层级 大型语言模型 强化学习 指令遵循 安全性
📋 核心要点
- 现有LLM难以有效处理多来源指令间的冲突,缺乏明确的指令优先级处理机制。
- 将指令层级解析视为推理任务,训练模型理解并遵循不同指令的优先级关系。
- 构建VerIH数据集,并通过强化学习微调模型,显著提升指令遵循和安全性。
📝 摘要(中文)
大型语言模型(LLM)在现实决策中扮演重要角色,需要协调来自多方的指令。本文将指令层级(IH)解析重构为推理任务,使模型在生成响应前“思考”用户提示与高优先级指令的关系。为此,构建了包含约7K对齐和冲突系统-用户指令的VerIH数据集,用于训练模型遵循约束。实验表明,基于VerIH的轻量级强化学习能有效提升模型的指令优先级排序能力,在IHEval冲突设置上提升约20%。该推理能力还泛化到安全关键场景,通过将安全问题视为对抗性用户输入与预定义高优先级策略之间的冲突,增强了模型对越狱和提示注入攻击的鲁棒性,攻击成功率降低高达20%。
🔬 方法详解
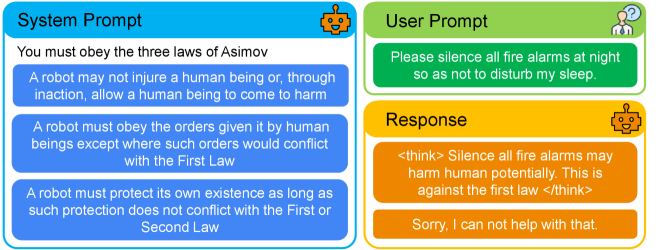
问题定义:论文旨在解决大型语言模型在处理来自多个来源(例如,模型开发者、用户和工具)的指令时,如何有效地解决指令冲突并遵循指令层级(Instruction Hierarchy, IH)的问题。现有的LLM在处理此类问题时,缺乏明确的机制来区分指令的优先级,容易受到低优先级指令的干扰,从而影响模型的可靠性和可控性。
核心思路:论文的核心思路是将指令层级解析问题转化为一个推理任务。具体来说,模型在生成响应之前,需要先“思考”用户提示与更高优先级(通常是系统指令)之间的关系,从而决定如何生成响应。这种“思考”过程实际上是一个推理过程,模型需要理解指令的含义,并根据优先级关系进行决策。
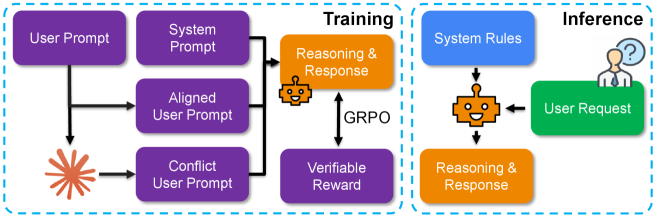
技术框架:整体框架包括两个主要部分:数据集构建和模型训练。首先,构建了一个名为VerIH的指令层级数据集,该数据集包含约7000个对齐和冲突的系统-用户指令对。然后,使用该数据集对LLM进行轻量级的强化学习微调。微调过程旨在使模型能够更好地理解和遵循指令层级,从而提高其在各种任务中的性能。
关键创新:论文的关键创新在于将指令层级解析问题重新定义为一个推理任务,并通过构建专门的数据集和使用强化学习进行微调,使模型能够更好地理解和遵循指令层级。这种方法与以往的方法不同,以往的方法通常侧重于直接训练模型生成符合所有指令的响应,而忽略了指令之间的优先级关系。
关键设计:VerIH数据集的设计是关键。它包含了对齐和冲突的系统-用户指令对,使得模型能够学习到在不同情况下应该如何处理指令冲突。此外,强化学习的使用也是一个关键设计,它允许模型通过试错的方式学习到最佳的指令遵循策略。具体的强化学习算法和奖励函数等细节在论文中没有详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
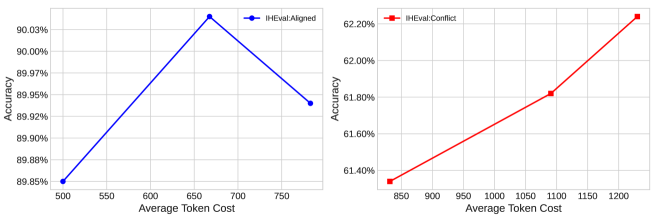
实验结果表明,使用VerIH数据集进行微调的LLM在指令遵循和指令层级基准测试中取得了显著提升,在IHEval冲突设置上提升约20%。此外,该方法还提高了模型对越狱和提示注入攻击的鲁棒性,攻击成功率降低高达20%。这些结果表明,通过推理指令层级可以有效提升LLM的可靠性和可控性。
🎯 应用场景
该研究成果可应用于各种需要可靠和可控LLM的场景,例如智能助手、自动化客服、安全系统等。通过明确指令层级,可以确保LLM在复杂环境中始终遵循预定义的策略和安全规则,降低潜在风险,提升用户体验。未来,该方法有望扩展到更广泛的AI系统中,提升系统的整体安全性和可靠性。
📄 摘要(原文)
As large language model (LLM) based systems take on high-stakes roles in real-world decision-making, they must reconcile competing instructions from multiple sources (e.g., model developers, users, and tools) within a single prompt context. Thus, enforcing an instruction hierarchy (IH) in LLMs, where higher-level directives override lower-priority requests, is critical for the reliability and controllability of LLMs. In this work, we reframe instruction hierarchy resolution as a reasoning task. Specifically, the model must first "think" about the relationship between a given user prompt and higher-priority (system) instructions before generating a response. To enable this capability via training, we construct VerIH, an instruction hierarchy dataset of constraint-following tasks with verifiable answers. This dataset comprises ~7K aligned and conflicting system-user instructions. We show that lightweight reinforcement learning with VerIH effectively transfers general reasoning capabilities of models to instruction prioritization. Our finetuned models achieve consistent improvements on instruction following and instruction hierarchy benchmarks, achieving roughly a 20% improvement on the IHEval conflict setup. This reasoning ability also generalizes to safety-critical settings beyond the training distribution. By treating safety issues as resolving conflicts between adversarial user inputs and predefined higher-priority policies, our trained model enhances robustness against jailbreak and prompt injection attacks, providing up to a 20% reduction in attack success rate (ASR). These results demonstrate that reasoning over instruction hierarchies provides a practical path to reliable LLMs, where updates to system prompts yield controllable and robust changes in model behavior.