Detecting Data Contamination in LLMs via In-Context Learning
作者: Michał Zawalski, Meriem Boubdir, Klaudia Bałazy, Besmira Nushi, Pablo Ribalta
分类: cs.CL, cs.AI
发布日期: 2025-10-30
💡 一句话要点
提出CoDeC,通过上下文学习检测LLM中的数据污染
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据污染检测 上下文学习 大型语言模型 模型评估 记忆检测
📋 核心要点
- 大型语言模型可能受到训练数据污染,导致评估结果失真,现有方法难以准确检测和量化这种污染。
- CoDeC的核心思想是利用上下文学习对模型性能的影响来区分模型记忆的数据和未见过的数据。
- 实验表明,CoDeC能够产生可解释的污染分数,有效区分已见和未见数据集,并揭示了开放权重模型中的记忆现象。
📝 摘要(中文)
本文提出了一种实用且精确的方法,即基于上下文的数据污染检测(CoDeC),用于检测和量化大型语言模型中训练数据污染。CoDeC通过测量上下文学习如何影响模型性能来区分训练期间记忆的数据和训练分布之外的数据。研究发现,上下文示例通常会提高未见过数据集的置信度,但如果数据集是训练的一部分,则可能会降低置信度,这是由于记忆模式受到干扰。实验表明,CoDeC产生可解释的污染分数,可以清楚地分离已见和未见的数据集,并揭示了具有未公开训练语料库的开放权重模型中存在强烈的记忆证据。该方法简单、自动化,并且与模型和数据集无关,易于与基准评估集成。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练数据污染检测的问题。现有方法在检测和量化LLM中的数据污染方面存在不足,难以准确判断模型是否在训练过程中“见过”特定的数据集,从而影响模型评估的可靠性。
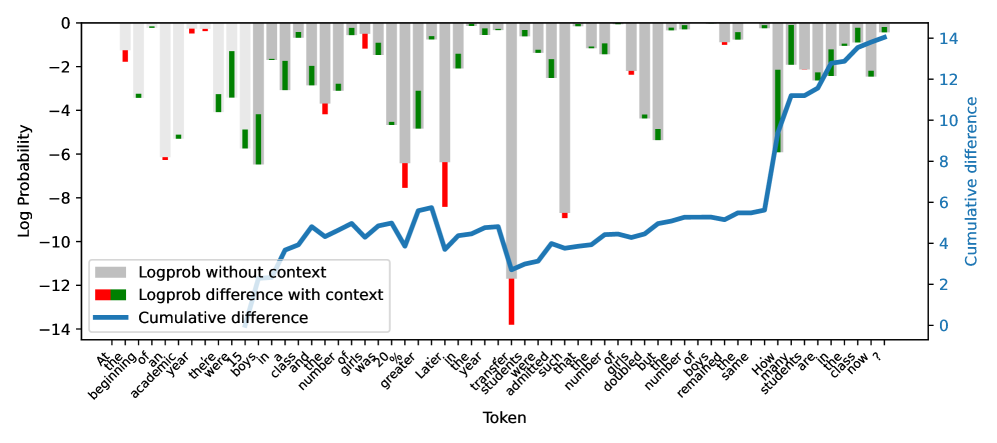
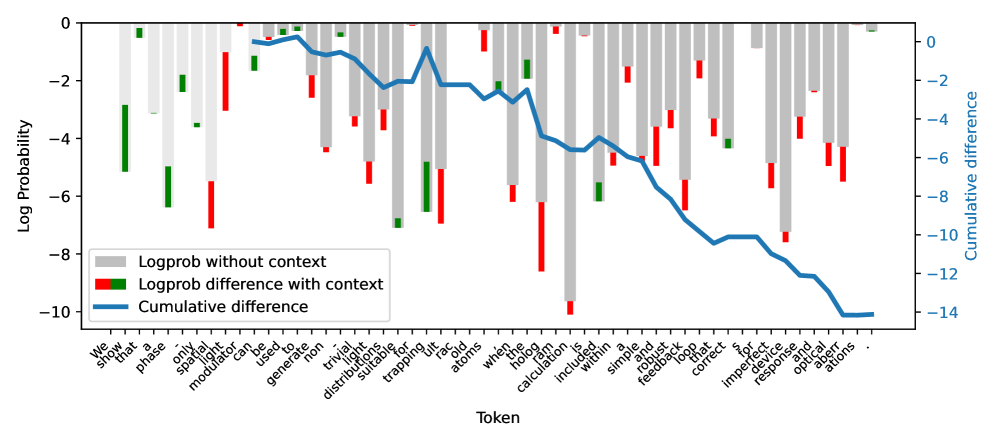
核心思路:CoDeC的核心思路是利用上下文学习(In-Context Learning, ICL)对模型性能的影响。如果模型在训练过程中已经“见过”某个数据集,那么在ICL中提供该数据集的示例可能会干扰模型已有的记忆模式,导致性能下降;反之,如果数据集是模型未见过的,ICL示例通常会提升模型性能。
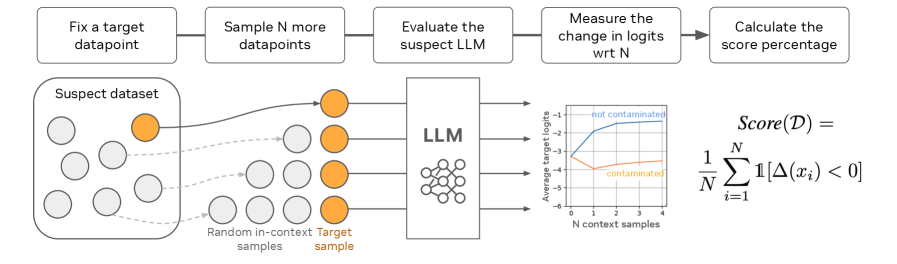
技术框架:CoDeC的整体流程如下:1) 选择一个待评估的数据集。2) 构建包含少量示例的上下文提示(In-Context Examples)。3) 使用带有和不带有上下文提示的LLM对数据集进行预测。4) 计算模型在两种情况下的性能差异,得到一个污染分数。污染分数越高,表明数据集越可能是模型未见过的;污染分数越低,表明数据集越可能是模型训练集的一部分。
关键创新:CoDeC的关键创新在于利用ICL对模型性能的差异化影响来判断数据污染。与传统的依赖于直接比较模型输出与已知数据的记忆检测方法不同,CoDeC通过观察ICL如何改变模型的行为来推断数据污染情况,从而避免了对模型内部参数的直接访问,具有更好的通用性和可解释性。
关键设计:CoDeC的关键设计包括:1) 上下文示例的选择策略:需要选择具有代表性的示例,以确保ICL能够有效影响模型性能。2) 性能指标的选择:可以使用准确率、F1值等指标来衡量模型在有无上下文提示下的性能。3) 污染分数的计算方式:需要设计一个合理的公式,将性能差异转化为可解释的污染分数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoDeC能够有效区分已见和未见的数据集,并揭示了开放权重模型中存在的记忆现象。例如,CoDeC在多个数据集上产生了可解释的污染分数,清晰地分离了已见和未见的数据集。此外,CoDeC还揭示了一些具有未公开训练语料库的开放权重模型存在强烈的记忆证据。
🎯 应用场景
CoDeC可用于评估大型语言模型的训练数据质量,确保模型评估的公平性和可靠性。它可以帮助识别模型可能存在的偏差和漏洞,并指导模型训练数据的清洗和优化。此外,CoDeC还可以应用于模型安全领域,检测模型是否泄露了训练数据中的敏感信息。
📄 摘要(原文)
We present Contamination Detection via Context (CoDeC), a practical and accurate method to detect and quantify training data contamination in large language models. CoDeC distinguishes between data memorized during training and data outside the training distribution by measuring how in-context learning affects model performance. We find that in-context examples typically boost confidence for unseen datasets but may reduce it when the dataset was part of training, due to disrupted memorization patterns. Experiments show that CoDeC produces interpretable contamination scores that clearly separate seen and unseen datasets, and reveals strong evidence of memorization in open-weight models with undisclosed training corpora. The method is simple, automated, and both model- and dataset-agnostic, making it easy to integrate with benchmark evaluations.