Semantically-Aware LLM Agent to Enhance Privacy in Conversational AI Services
作者: Jayden Serenari, Stephen Lee
分类: cs.CL
发布日期: 2025-10-30
备注: Accepted to IEEE Big Data 2025
💡 一句话要点
提出LOPSIDED框架,增强会话AI中LLM的隐私保护能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会话AI 隐私保护 大型语言模型 个人身份信息 假名化
📋 核心要点
- 会话AI系统面临隐私泄露风险,用户共享的个人身份信息(PII)可能被暴露,导致安全问题。
- LOPSIDED框架通过动态替换用户提示中的敏感PII实体为语义一致的假名,保护隐私并维持上下文完整性。
- 实验结果表明,LOPSIDED相比基线方法,显著降低了语义效用错误,同时提升了隐私保护效果。
📝 摘要(中文)
随着会话式人工智能系统的日益普及,隐私泄露问题日益严重,尤其是在用户与大型语言模型(LLM)交互时共享敏感个人数据时。与这些模型共享的对话可能包含个人身份信息(PII),如果泄露,可能导致安全漏洞或身份盗窃。为了应对这一挑战,我们提出了局部优化与语义完整性导向实体检测的匿名化(LOPSIDED)框架,这是一种语义感知的隐私代理,旨在保护使用远程LLM时的敏感PII数据。与以往通常会降低响应质量的工作不同,我们的方法动态地将用户提示中的敏感PII实体替换为语义一致的假名,从而保持对话的上下文完整性。一旦模型生成其响应,假名将自动去匿名化,确保用户收到准确、保护隐私的输出。我们使用来自ShareGPT的真实对话评估我们的方法,我们进一步增强和注释这些对话,以评估命名实体是否与模型的响应在上下文中相关。我们的结果表明,LOPSIDED将语义效用错误减少了5倍,同时增强了隐私。
🔬 方法详解
问题定义:论文旨在解决会话式AI系统中,用户与LLM交互时,由于用户输入中包含敏感个人身份信息(PII)而导致的隐私泄露问题。现有方法在保护隐私的同时,往往会降低LLM响应的质量,例如直接删除PII可能导致上下文信息丢失,影响LLM的理解和生成能力。
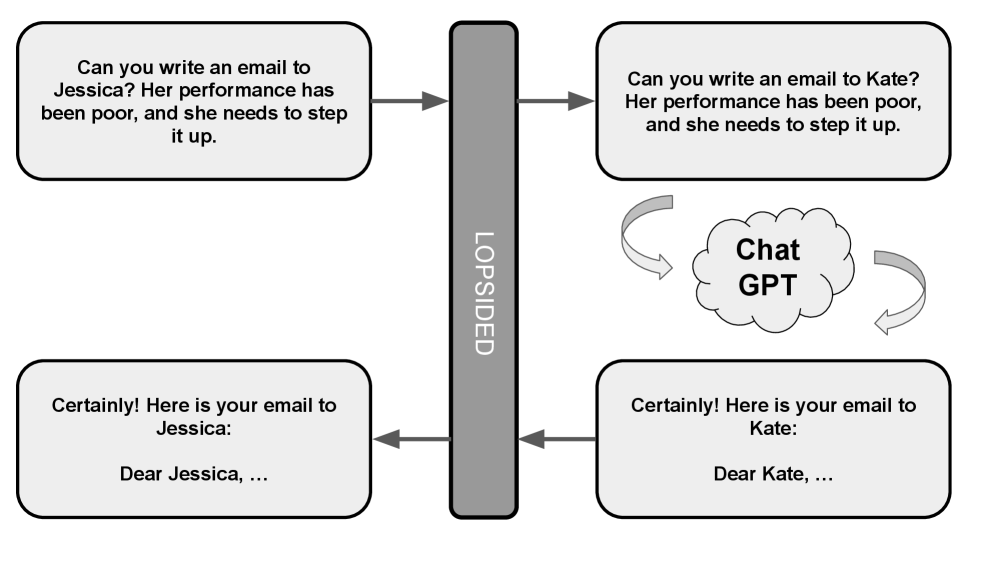
核心思路:论文的核心思路是在用户输入发送给LLM之前,动态地将敏感PII实体替换为语义一致的假名(pseudonym),从而保护用户的隐私。在LLM生成响应后,再将假名替换回原始的PII,确保用户获得准确且隐私保护的输出。这种方法旨在在保护隐私的同时,尽可能地保持对话的上下文完整性,避免影响LLM的性能。
技术框架:LOPSIDED框架主要包含以下几个模块:1) PII实体检测:识别用户输入中的敏感PII实体。2) 假名生成:为每个PII实体生成语义一致的假名。3) 假名替换:将用户输入中的PII实体替换为生成的假名。4) LLM交互:将替换后的输入发送给LLM进行处理。5) 响应生成:LLM根据替换后的输入生成响应。6) 去假名化:将LLM响应中的假名替换回原始的PII实体。7) 输出:将去假名化后的响应返回给用户。
关键创新:LOPSIDED的关键创新在于其语义感知的假名生成和替换机制。与简单的PII删除或随机替换不同,LOPSIDED能够生成与原始PII在语义上相关的假名,从而更好地保持对话的上下文信息。这种语义一致性有助于LLM更好地理解用户意图,生成更准确和相关的响应。
关键设计:论文中未明确给出假名生成的具体算法或模型细节,但强调了语义一致性的重要性。可能采用的方法包括:1) 基于知识图谱的实体链接和关系推理,找到与原始PII相关的实体作为假名。2) 使用预训练语言模型(如BERT)计算PII实体之间的语义相似度,选择相似度高的实体作为假名。3) 使用生成模型(如GPT)根据原始PII的上下文生成合适的假名。具体的损失函数和网络结构等技术细节未知。
🖼️ 关键图片

📊 实验亮点
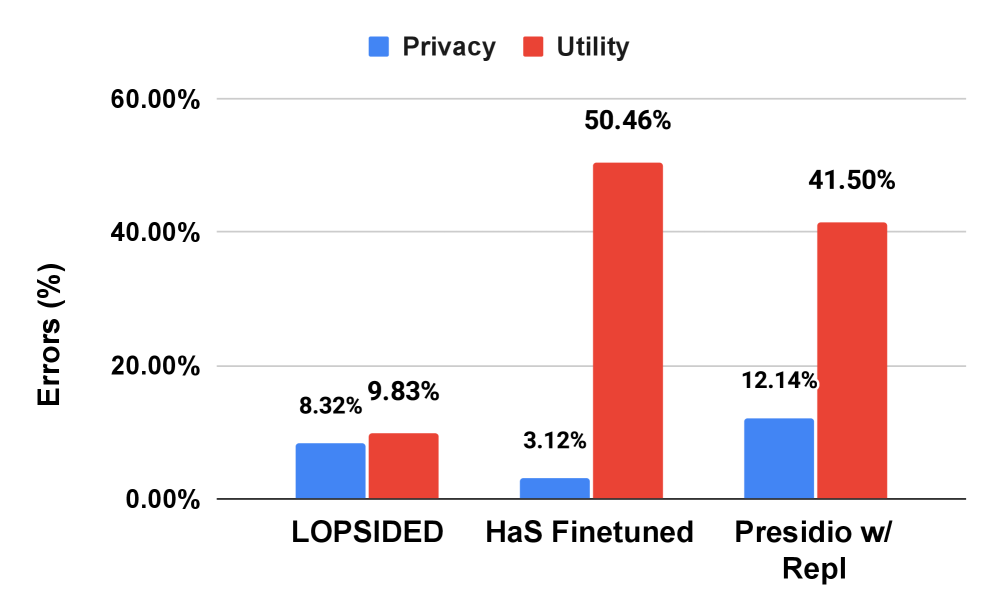
实验结果表明,LOPSIDED框架在增强隐私保护的同时,显著降低了语义效用错误。与基线方法相比,LOPSIDED将语义效用错误降低了5倍。该结果表明,LOPSIDED能够在保护用户隐私的同时,保持对话的上下文完整性,避免影响LLM的性能。
🎯 应用场景
该研究成果可应用于各种会话式AI服务中,例如智能客服、虚拟助手、在线医疗咨询等。通过保护用户在对话中分享的敏感信息,可以提高用户对AI系统的信任度,促进会话式AI技术的更广泛应用。未来,该技术还可以扩展到保护其他类型的敏感数据,例如财务信息、健康记录等。
📄 摘要(原文)
With the increasing use of conversational AI systems, there is growing concern over privacy leaks, especially when users share sensitive personal data in interactions with Large Language Models (LLMs). Conversations shared with these models may contain Personally Identifiable Information (PII), which, if exposed, could lead to security breaches or identity theft. To address this challenge, we present the Local Optimizations for Pseudonymization with Semantic Integrity Directed Entity Detection (LOPSIDED) framework, a semantically-aware privacy agent designed to safeguard sensitive PII data when using remote LLMs. Unlike prior work that often degrade response quality, our approach dynamically replaces sensitive PII entities in user prompts with semantically consistent pseudonyms, preserving the contextual integrity of conversations. Once the model generates its response, the pseudonyms are automatically depseudonymized, ensuring the user receives an accurate, privacy-preserving output. We evaluate our approach using real-world conversations sourced from ShareGPT, which we further augment and annotate to assess whether named entities are contextually relevant to the model's response. Our results show that LOPSIDED reduces semantic utility errors by a factor of 5 compared to baseline techniques, all while enhancing privacy.