Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
作者: Hyunji Lee, Wenhao Yu, Hongming Zhang, Kaixin Ma, Jiyeon Kim, Dong Yu, Minjoon Seo
分类: cs.CL
发布日期: 2025-10-30
💡 一句话要点
分析Mamba-Transformer混合模型,提出数据增强方法提升记忆回溯和语言建模能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 混合模型 状态空间模型 注意力机制 记忆回溯 数据增强
📋 核心要点
- 现有混合模型架构设计选择不够明确,限制了其性能的进一步提升。
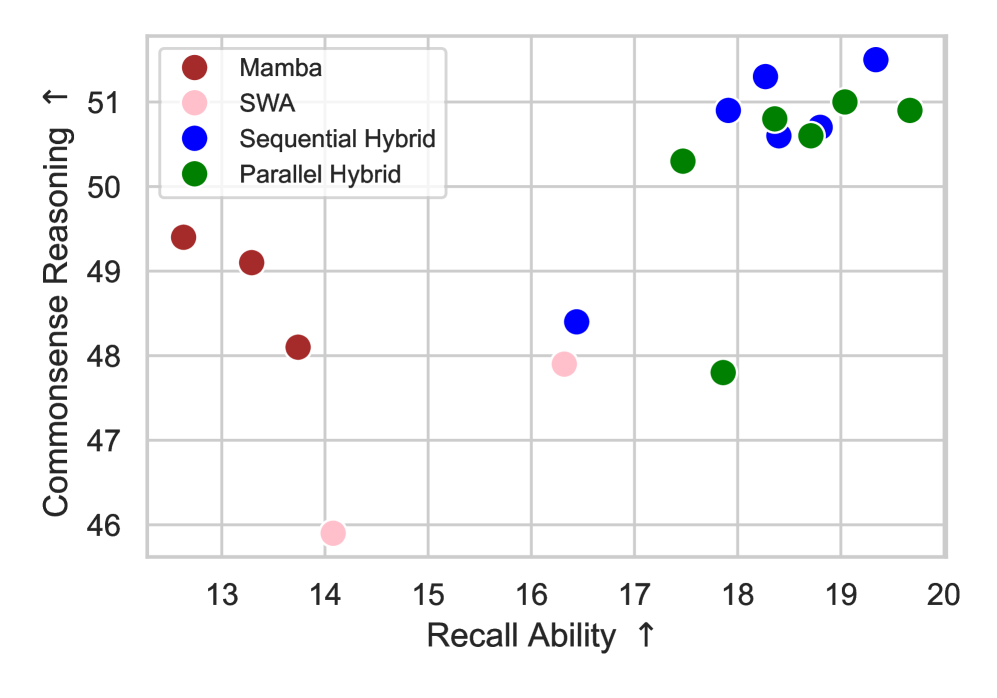
- 通过分析记忆利用率,论文提出顺序和并行混合架构的适用场景,并引入数据增强方法。
- 实验表明,数据增强方法能有效提升召回率,且具有良好的泛化能力。
📝 摘要(中文)
混合模型结合了状态空间模型(SSMs)的效率和注意力机制的高召回能力,表现出强大的性能。然而,这些混合模型背后的架构设计选择仍然不够明确。本文从记忆利用和整体性能的角度分析了混合架构,并提出了一种互补方法来进一步提高其有效性。我们首先研究了SSM和注意力层的顺序和并行集成之间的区别。我们的分析揭示了一些有趣的发现,包括顺序混合模型在较短的上下文中表现更好,而并行混合模型对于较长的上下文更有效。我们还引入了一种以数据为中心的方法,即持续训练经过释义增强的数据集,从而进一步提高召回率,同时保留其他能力。它在不同的基础模型中具有良好的泛化能力,并且优于旨在提高召回率的架构修改。我们的发现提供了对混合SSM-注意力模型的更深入理解,并为设计针对各种用例量身定制的架构提供了实用的指导。
🔬 方法详解
问题定义:现有结合状态空间模型(SSMs)和注意力机制的混合模型,虽然兼具效率和高召回率,但其架构设计背后的原理尚不明确。如何选择合适的混合方式(顺序或并行)以及如何进一步提升其记忆回溯能力是亟待解决的问题。现有方法主要集中在架构修改上,效果有限。
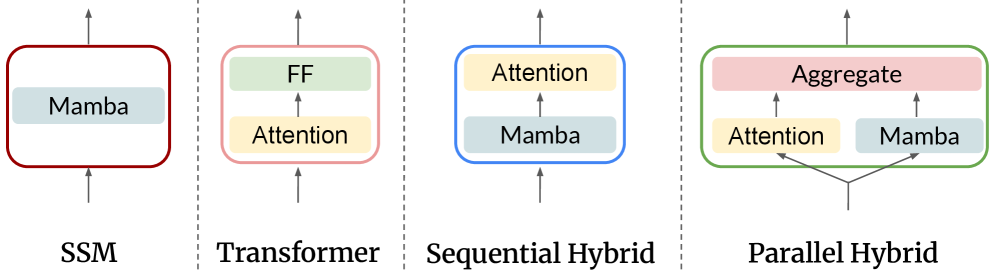
核心思路:论文的核心思路是通过分析不同混合方式(顺序和并行)在不同上下文长度下的表现,理解其内在机制。此外,论文提出一种数据增强方法,通过持续训练经过释义增强的数据集,来提升模型的记忆回溯能力,而非仅仅依赖架构上的修改。
技术框架:论文主要包含两个部分:一是分析不同混合架构(顺序和并行)的性能差异;二是提出并验证基于数据增强的训练方法。没有明确的整体架构图,但研究重点在于混合方式的选择和数据增强策略的应用。
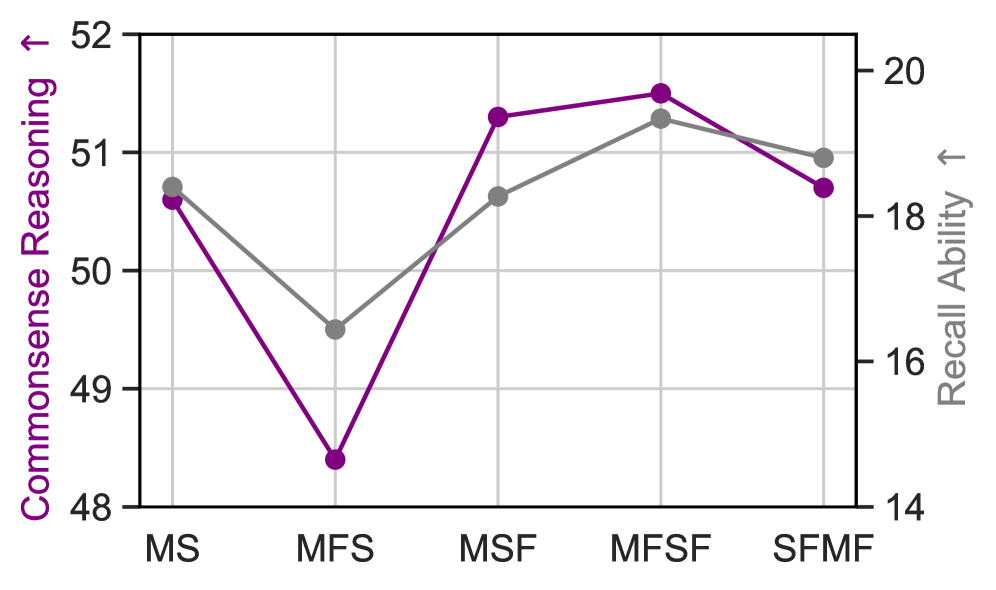
关键创新:论文的关键创新在于提出了一种数据驱动的增强记忆回溯能力的方法,即通过持续训练经过释义增强的数据集。这种方法与传统的架构修改方法不同,它侧重于从数据层面提升模型的记忆能力,并且具有更好的泛化性。
关键设计:数据增强的关键在于生成高质量的释义数据。论文可能采用了回译、同义词替换等方法来生成释义。持续训练策略也很重要,需要仔细调整学习率等超参数,以避免灾难性遗忘。具体参数设置和网络结构细节在摘要中未提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文实验表明,所提出的数据增强方法能够有效提升混合模型的召回率,并且在不同的基础模型上都表现出良好的泛化能力。该方法优于传统的架构修改方法,为提升混合模型的性能提供了一种新的思路。具体的性能提升数据在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要长程依赖建模的自然语言处理任务,例如长文本摘要、机器翻译、对话系统等。通过选择合适的混合架构和采用数据增强方法,可以提升模型在这些任务上的性能,尤其是在需要高召回率的场景下。该研究也为未来混合模型的架构设计提供了指导。
📄 摘要(原文)
Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.