Evaluating Perspectival Biases in Cross-Modal Retrieval
作者: Teerapol Saengsukhiran, Peerawat Chomphooyod, Narabodee Rodjananant, Chompakorn Chaksangchaichot, Patawee Prakrankamanant, Witthawin Sripheanpol, Pak Lovichit, Sarana Nutanong, Ekapol Chuangsuwanich
分类: cs.IR, cs.CL
发布日期: 2025-10-30 (更新: 2026-01-24)
💡 一句话要点
提出3XCM基准,评估跨模态检索中由语言和文化差异引起的视角偏差。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态检索 视角偏差 文化关联 语言偏差 多语言 基准数据集 公平性 低资源语言
📋 核心要点
- 现有跨模态检索模型易受语言和文化背景影响,产生视角偏差,导致检索结果不公平。
- 提出3XCM基准,用于隔离和评估跨文化、跨模态、跨语言环境下的视角偏差。
- 实验表明,模型在图像到文本检索中偏好流行语言,文本到图像检索中存在文化关联偏差。
📝 摘要(中文)
多模态检索系统应在语义空间中运行,不受查询的语言或文化背景的影响。然而,在实践中,检索结果系统性地反映了视角偏差:这些偏差受到语言流行度和文化关联的影响。我们引入了跨文化、跨模态、跨语言的多模态(3XCM)基准来隔离这些影响。研究结果表明,对于图像到文本的检索,模型倾向于偏爱来自流行语言的条目,而不是那些语义上忠实的条目。对于文本到图像的检索,我们观察到语义对齐和语言条件文化关联之间的联合嵌入空间中存在一致的“拉锯效应”。当语义表示不够明确时,尤其是在低资源语言中,相似性越来越受文化上熟悉的视觉模式支配,从而导致检索中的系统性关联偏差。我们的发现表明,实现公平的多模态检索需要有针对性的策略,明确地将语言与文化分离,而不是仅仅依赖于更广泛的数据暴露。这项工作强调了将语言和文化偏差视为多模态表征学习中不同的、可衡量的挑战的必要性。
🔬 方法详解
问题定义:论文旨在解决跨模态检索系统中存在的视角偏差问题。现有方法未能充分考虑语言和文化差异对检索结果的影响,导致模型在检索时倾向于选择与流行语言或文化背景相关的结果,而忽略了语义上的准确性。这种偏差在低资源语言中尤为明显,因为模型可能依赖于文化上熟悉的视觉模式来弥补语义信息的不足。
核心思路:论文的核心思路是明确区分语言和文化对跨模态检索的影响,并提出针对性的策略来解耦它们。通过构建一个包含跨文化、跨模态、跨语言数据的基准数据集(3XCM),可以更有效地评估模型在不同语言和文化背景下的表现,从而揭示潜在的偏差。论文强调,仅仅增加数据量并不能解决问题,需要更精细化的方法来处理语言和文化之间的复杂关系。
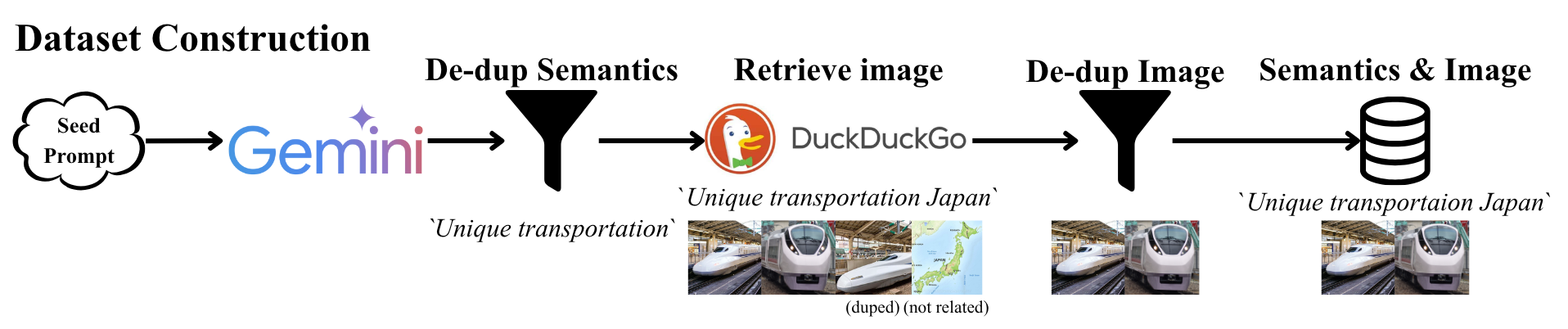
技术框架:论文主要通过构建和分析3XCM基准数据集来研究视角偏差。该基准数据集包含来自不同文化和语言的图像和文本数据,并设计了相应的评估指标来衡量模型在跨文化、跨模态、跨语言环境下的检索性能。研究人员使用现有的跨模态检索模型在3XCM上进行实验,并分析检索结果中的偏差模式。
关键创新:论文的关键创新在于提出了3XCM基准数据集,这是一个专门用于评估跨模态检索中视角偏差的资源。与以往的研究不同,该论文明确区分了语言和文化对检索结果的影响,并强调了针对性策略的重要性。此外,论文还揭示了在文本到图像检索中存在的“拉锯效应”,即语义对齐和语言条件文化关联之间的竞争关系。
关键设计:3XCM基准数据集的设计考虑了以下关键因素:1) 数据的多样性,包含来自不同文化和语言的图像和文本数据;2) 数据的平衡性,尽量保证不同文化和语言的数据量相对均衡;3) 评估指标的合理性,能够准确衡量模型在跨文化、跨模态、跨语言环境下的检索性能。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的跨模态检索模型,论文主要关注的是对现有模型在3XCM上的评估和分析。
🖼️ 关键图片


📊 实验亮点
研究表明,现有模型在图像到文本检索中倾向于选择流行语言,而非语义上最匹配的条目。在文本到图像检索中,观察到语义对齐与文化关联之间存在“拉锯效应”,尤其是在低资源语言中,文化熟悉度会显著影响检索结果。这些发现强调了在多模态检索中解决语言和文化偏差的必要性。
🎯 应用场景
该研究成果可应用于改进跨文化交流、提升多语言信息检索的公平性,并促进更具包容性的人工智能系统设计。通过减少语言和文化偏差,可以提高跨模态检索在教育、旅游、电子商务等领域的应用效果,并避免因文化误解或偏见而产生负面影响。
📄 摘要(原文)
Multimodal retrieval systems are expected to operate in a semantic space, agnostic to the language or cultural origin of the query. In practice, however, retrieval outcomes systematically reflect perspectival biases: deviations shaped by linguistic prevalence and cultural associations. We introduce the Cross-Cultural, Cross-Modal, Cross-lingual Multimodal (3XCM) benchmark to isolate these effects. Results from our studies indicate that, for image-to-text retrieval, models tend to favor entries from prevalent languages over those that are semantically faithful. For text-to-image retrieval, we observe a consistent "tugging effect" in the joint embedding space between semantic alignment and language-conditioned cultural association. When semantic representations are insufficiently resolved, particularly in low-resource languages, similarity is increasingly governed by culturally familiar visual patterns, leading to systematic association bias in retrieval. Our findings suggest that achieving equitable multimodal retrieval necessitates targeted strategies that explicitly decouple language from culture, rather than relying solely on broader data exposure. This work highlights the need to treat linguistic and cultural biases as distinct, measurable challenges in multimodal representation learning.