AMO-Bench: Large Language Models Still Struggle in High School Math Competitions
作者: Shengnan An, Xunliang Cai, Xuezhi Cao, Xiaoyu Li, Yehao Lin, Junlin Liu, Xinxuan Lv, Dan Ma, Xuanlin Wang, Ziwen Wang, Shuang Zhou
分类: cs.CL, cs.AI
发布日期: 2025-10-30
备注: 14 pages, 9 figures
💡 一句话要点
提出AMO-Bench,用于评估大语言模型在奥林匹克级别数学问题上的推理能力。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 奥林匹克竞赛 基准数据集 自动评估
📋 核心要点
- 现有数学推理基准对顶尖大语言模型区分度不足,存在性能饱和和数据泄露问题。
- AMO-Bench通过专家验证和原创题目,构建了难度更高、更可靠的数学推理评估基准。
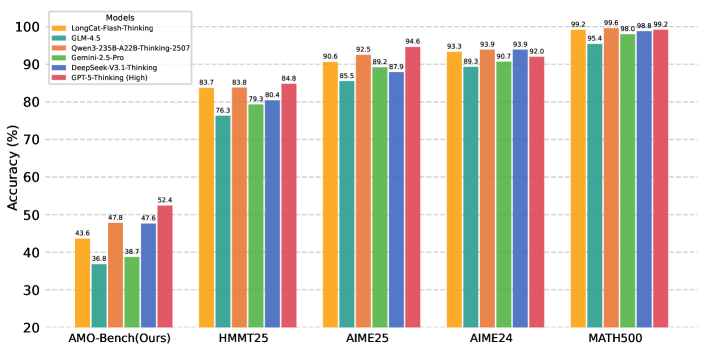
- 实验表明,即使是最先进的LLM在AMO-Bench上的表现仍然有限,但存在随计算量增加的性能提升趋势。
📝 摘要(中文)
本文提出了AMO-Bench,一个包含50道人工设计的、难度达到甚至超过奥林匹克竞赛水平的高级数学推理基准。现有的基准广泛利用高中数学竞赛来评估大语言模型(LLM)的数学推理能力。然而,由于性能饱和(例如,AIME24/25),许多现有的数学竞赛在评估顶尖LLM时变得不太有效。为了解决这个问题,AMO-Bench引入了更严格的挑战,确保所有50个问题都(1)经过专家交叉验证,至少达到国际数学奥林匹克(IMO)的难度标准,并且(2)完全是原创问题,以防止潜在的因数据记忆导致的性能泄漏。此外,AMO-Bench中的每个问题只需要一个最终答案,而不是证明过程,从而实现自动和鲁棒的评分评估。在AMO-Bench上对26个LLM进行的实验结果表明,即使是性能最佳的模型也仅达到52.4%的准确率,而大多数LLM的得分低于40%。除了这些较差的性能之外,我们的进一步分析揭示了随着测试时计算量增加,AMO-Bench上存在有希望的缩放趋势。这些结果突出了当前LLM在数学推理方面仍有很大的改进空间。我们发布AMO-Bench,以促进进一步研究,从而提高语言模型的推理能力。
🔬 方法详解
问题定义:论文旨在解决现有数学推理基准对评估顶尖大语言模型(LLM)的有效性不足的问题。现有的基准,如基于高中数学竞赛的题目,已经出现性能饱和,无法有效区分不同LLM的推理能力。此外,数据泄露(LLM可能已经见过这些题目)也影响了评估的可靠性。
核心思路:核心思路是构建一个难度更高、更可靠的数学推理基准。通过人工设计难度达到甚至超过国际数学奥林匹克(IMO)水平的原创题目,并由专家进行交叉验证,确保题目的难度和质量。同时,只要求最终答案,避免复杂的证明过程,方便自动评估。
技术框架:AMO-Bench基准包含50道数学问题,这些问题都经过了专家验证,确保难度达到IMO级别或更高。问题的设计原则是原创性,避免LLM通过记忆数据获得不公平的优势。评估过程采用自动评分,只需要LLM给出最终答案即可。
关键创新:最重要的创新点在于基准题目的难度和原创性。通过专家交叉验证,确保题目难度达到IMO级别,从而对LLM的推理能力提出更高的要求。完全原创的题目避免了数据泄露问题,使得评估结果更加可靠。
关键设计:AMO-Bench的关键设计在于题目的选择和验证过程。每道题目都经过多位专家的独立评估和交叉验证,确保难度和质量。此外,只要求最终答案的设计简化了评估流程,使得自动评分成为可能。没有提及具体的参数设置、损失函数或网络结构,因为该论文主要关注基准数据集的构建和评估。
🖼️ 关键图片


📊 实验亮点
在AMO-Bench上的实验结果显示,即使是性能最佳的LLM也仅达到52.4%的准确率,大多数LLM的得分低于40%。这表明当前LLM在高级数学推理方面仍有很大的提升空间。进一步的分析表明,随着测试时计算量的增加,LLM在AMO-Bench上的性能呈现出明显的提升趋势,预示着通过增加计算资源可以进一步提高LLM的数学推理能力。
🎯 应用场景
AMO-Bench可用于评估和提升大语言模型在数学、科学、工程等领域的推理能力。通过该基准,研究人员可以更准确地了解LLM的数学推理能力,并开发更有效的训练方法和模型架构,从而推动人工智能在需要复杂推理的实际问题中的应用,例如科学发现、金融建模和工程设计。
📄 摘要(原文)
We present AMO-Bench, an Advanced Mathematical reasoning benchmark with Olympiad level or even higher difficulty, comprising 50 human-crafted problems. Existing benchmarks have widely leveraged high school math competitions for evaluating mathematical reasoning capabilities of large language models (LLMs). However, many existing math competitions are becoming less effective for assessing top-tier LLMs due to performance saturation (e.g., AIME24/25). To address this, AMO-Bench introduces more rigorous challenges by ensuring all 50 problems are (1) cross-validated by experts to meet at least the International Mathematical Olympiad (IMO) difficulty standards, and (2) entirely original problems to prevent potential performance leakages from data memorization. Moreover, each problem in AMO-Bench requires only a final answer rather than a proof, enabling automatic and robust grading for evaluation. Experimental results across 26 LLMs on AMO-Bench show that even the best-performing model achieves only 52.4% accuracy on AMO-Bench, with most LLMs scoring below 40%. Beyond these poor performances, our further analysis reveals a promising scaling trend with increasing test-time compute on AMO-Bench. These results highlight the significant room for improving the mathematical reasoning in current LLMs. We release AMO-Bench to facilitate further research into advancing the reasoning abilities of language models. https://amo-bench.github.io/