Evontree: Ontology Rule-Guided Self-Evolution of Large Language Models
作者: Mingchen Tu, Zhiqiang Liu, Juan Li, Liangyurui Liu, Junjie Wang, Lei Liang, Wen Zhang
分类: cs.CL, cs.AI
发布日期: 2025-10-30
💡 一句话要点
Evontree:利用本体规则引导大语言模型自进化,提升领域知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 领域知识 本体规则 自进化 知识蒸馏
📋 核心要点
- 现有方法在医疗等数据敏感领域,因缺乏高质量领域数据,导致大语言模型难以适应专业应用。
- Evontree利用少量高质量本体规则,从大语言模型中提取、验证和增强领域知识,无需大量外部数据。
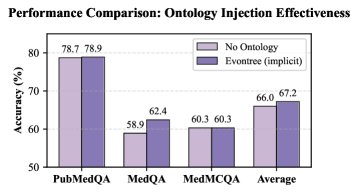
- 实验表明,Evontree在医学问答任务上优于未修改的模型和监督基线,准确率提升高达3.7%。
📝 摘要(中文)
大型语言模型(LLMs)通过大规模预训练和精选的微调数据,在多个领域展现了卓越的能力。然而,在医疗保健等数据敏感领域,缺乏高质量、领域特定的训练语料阻碍了LLMs在专业应用中的适应性。同时,领域专家已将领域知识提炼成本体规则,这些规则形式化了概念之间的关系,并确保了知识管理存储库的完整性。我们将LLMs视为人类知识的隐式存储库,并提出了Evontree,这是一个新颖的框架,它利用一小部分高质量的本体规则来系统地提取、验证和增强LLMs中的领域知识,而无需大量的外部数据集。具体来说,Evontree从原始模型中提取领域本体,使用两个核心本体规则检测不一致性,并通过自蒸馏微调来强化精炼后的知识。在Llama3-8B-Instruct和Med42-v2上进行的医学问答基准测试的大量实验表明,Evontree始终优于未修改的模型和领先的监督基线,准确率提高了3.7%。这些结果证实了该方法在LLMs的低资源领域适应方面的有效性、效率和鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在数据敏感领域,如医疗保健,因缺乏高质量领域特定训练数据而难以适应专业应用的问题。现有方法依赖大量外部数据集进行微调,但在低资源场景下表现不佳,且难以保证知识的准确性和一致性。
核心思路:论文的核心思路是将LLMs视为人类知识的隐式存储库,并利用领域专家提炼的本体规则来引导LLMs进行知识提取、验证和增强。通过这种方式,可以在不依赖大量外部数据的情况下,提升LLMs在特定领域的知识水平和推理能力。
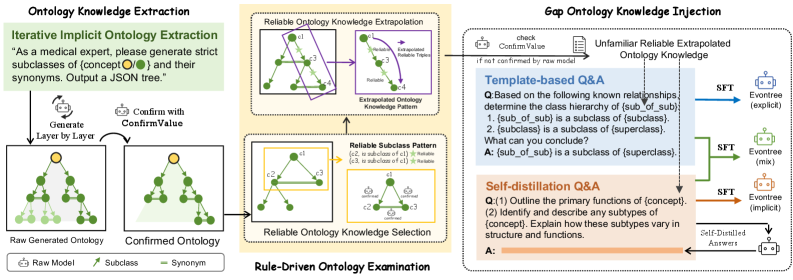
技术框架:Evontree框架包含三个主要阶段:1) 领域本体提取:从原始LLM中提取领域本体知识。2) 知识一致性验证:使用两个核心本体规则(例如,is-a关系和part-of关系)检测提取的知识中的不一致性。3) 自蒸馏微调:利用验证后的知识,通过自蒸馏的方式对LLM进行微调,以强化和巩固领域知识。
关键创新:Evontree的关键创新在于利用本体规则来指导LLM的自进化过程,无需大量外部数据集。这种方法能够有效地提取、验证和增强LLM中的领域知识,并提高其在特定领域的性能。与现有方法相比,Evontree更加高效、鲁棒,并且适用于低资源场景。
关键设计:论文中使用了两个核心本体规则进行知识一致性验证,具体规则的定义和应用方式在论文中有详细描述。自蒸馏微调过程中,使用了特定的损失函数来引导模型学习验证后的知识。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Evontree在医学问答基准测试中,使用Llama3-8B-Instruct和Med42-v2模型,均优于未修改的模型和领先的监督基线。具体而言,Evontree的准确率提升高达3.7%,证明了其在低资源领域适应方面的有效性、效率和鲁棒性。这些结果表明,利用本体规则引导大语言模型自进化是一种有前景的方法。
🎯 应用场景
Evontree框架可应用于医疗、法律、金融等数据敏感领域,提升大语言模型在这些领域的专业能力。该研究有助于构建更可靠、更专业的AI系统,辅助医生诊断、律师分析案情、金融分析师进行风险评估等。未来,该方法可扩展到更多领域,并与其他知识表示方法相结合,进一步提升大语言模型的智能化水平。
📄 摘要(原文)
Large language models (LLMs) have demonstrated exceptional capabilities across multiple domains by leveraging massive pre-training and curated fine-tuning data. However, in data-sensitive fields such as healthcare, the lack of high-quality, domain-specific training corpus hinders LLMs' adaptation for specialized applications. Meanwhile, domain experts have distilled domain wisdom into ontology rules, which formalize relationships among concepts and ensure the integrity of knowledge management repositories. Viewing LLMs as implicit repositories of human knowledge, we propose Evontree, a novel framework that leverages a small set of high-quality ontology rules to systematically extract, validate, and enhance domain knowledge within LLMs, without requiring extensive external datasets. Specifically, Evontree extracts domain ontology from raw models, detects inconsistencies using two core ontology rules, and reinforces the refined knowledge via self-distilled fine-tuning. Extensive experiments on medical QA benchmarks with Llama3-8B-Instruct and Med42-v2 demonstrate consistent outperformance over both unmodified models and leading supervised baselines, achieving up to a 3.7% improvement in accuracy. These results confirm the effectiveness, efficiency, and robustness of our approach for low-resource domain adaptation of LLMs.