Encoder-Decoder or Decoder-Only? Revisiting Encoder-Decoder Large Language Model
作者: Biao Zhang, Yong Cheng, Siamak Shakeri, Xinyi Wang, Min Ma, Orhan Firat
分类: cs.CL
发布日期: 2025-10-30
备注: The scaling study inspiring T5Gemma
💡 一句话要点
重新审视Encoder-Decoder大语言模型,探索其在效率和性能上的潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 Encoder-Decoder Decoder-Only 模型缩放 指令调优
📋 核心要点
- 现有研究主要集中于Decoder-Only架构,可能忽略了Encoder-Decoder架构在大语言模型中的潜力。
- 论文重新审视Encoder-Decoder架构,并结合Decoder-Only模型的先进技术,构建RedLLM模型。
- 实验表明,RedLLM在缩放性、上下文长度外推和推理效率方面表现出与Decoder-Only模型相当甚至更优的性能。
📝 摘要(中文)
最近的大语言模型(LLM)研究经历了一次架构转变,从编码器-解码器模型转向目前占主导地位的仅解码器模型。然而,这种快速转变缺乏严格的比较分析,尤其是在 extit{缩放角度}上,这引发了人们对编码器-解码器模型潜力可能被忽视的担忧。为了填补这一空白,我们重新审视了编码器-解码器LLM (RedLLM),并使用来自仅解码器LLM (DecLLM)的最新方法对其进行了增强。我们对使用前缀语言建模(LM)预训练的RedLLM和使用因果LM预训练的DecLLM在不同模型规模(从约1.5亿到约80亿)之间进行了全面比较。使用RedPajama V1 (1.6T tokens)进行预训练,FLAN进行指令调优,我们的实验表明RedLLM产生了引人注目的缩放特性和出人意料的强大性能。虽然DecLLM在预训练期间总体上更具有计算优势,但RedLLM表现出相当的缩放和上下文长度外推能力。在指令调优后,RedLLM在各种下游任务上取得了相当甚至更好的结果,同时享受着显著更高的推理效率。我们希望我们的发现能够激发更多关于重新审视RedLLM的努力,释放其开发强大而高效的LLM的潜力。
🔬 方法详解
问题定义:现有的大语言模型研究趋势主要集中在Decoder-Only架构上,而对Encoder-Decoder架构的潜力关注不足。缺乏对Encoder-Decoder架构在模型缩放性、性能和效率方面的深入分析和优化,可能导致错失更优的模型设计方案。
核心思路:论文的核心思路是重新审视Encoder-Decoder架构在大语言模型中的潜力,通过结合Decoder-Only模型的先进技术,例如更有效的训练方法和模型结构优化,来提升Encoder-Decoder模型的性能和效率。通过实验对比,验证Encoder-Decoder架构在特定场景下的优势。
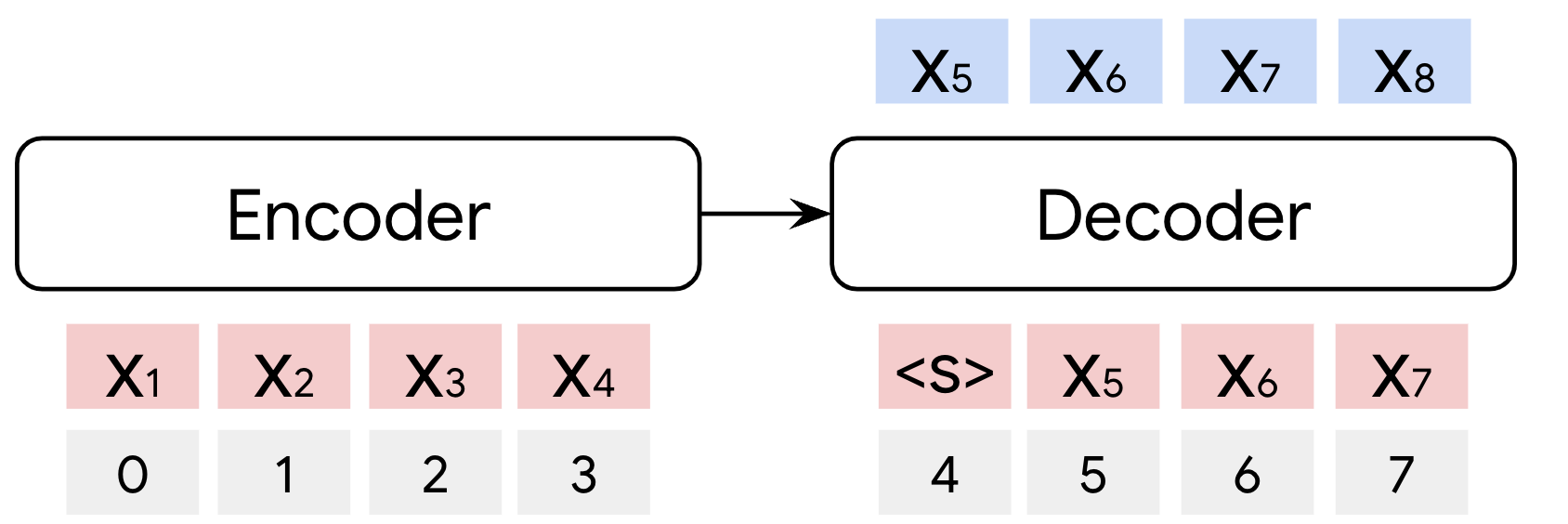
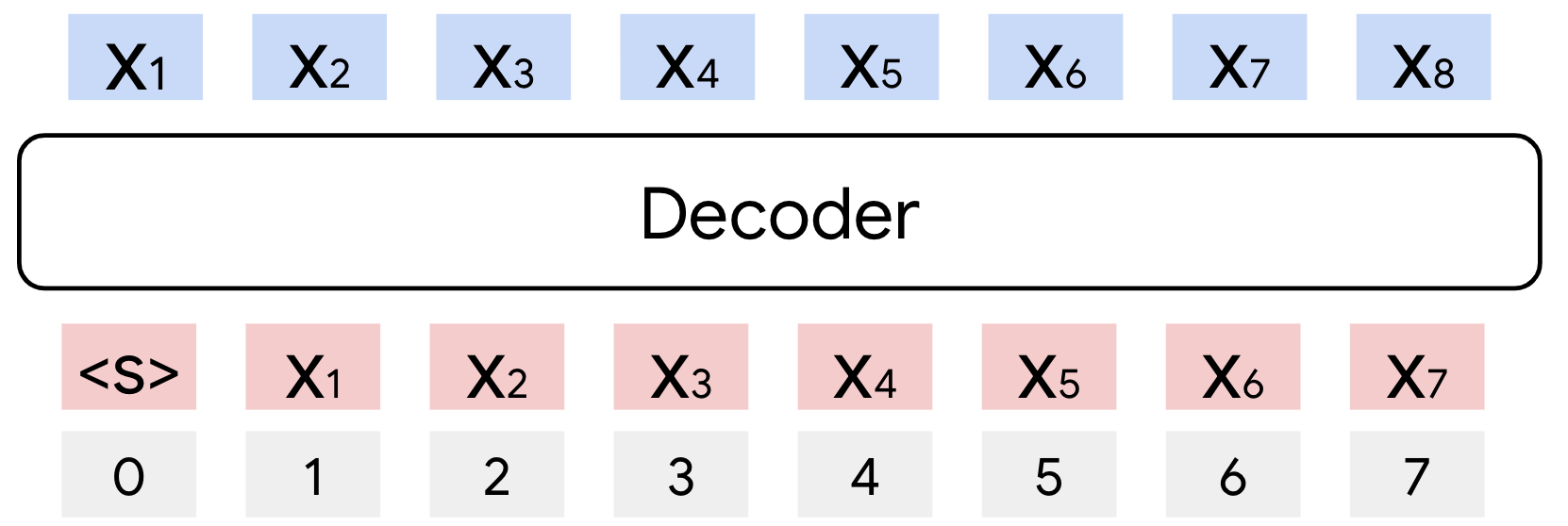
技术框架:论文提出的RedLLM模型基于Encoder-Decoder架构,并借鉴了Decoder-Only模型的训练方法。预训练阶段使用RedPajama V1数据集(1.6T tokens),采用prefix language modeling (LM)进行训练。指令调优阶段使用FLAN数据集。模型规模从1.5亿到80亿参数不等,与Decoder-Only模型进行对比。
关键创新:论文的关键创新在于对Encoder-Decoder架构的重新审视和优化。通过实验证明,在特定场景下,Encoder-Decoder架构在推理效率和上下文长度外推方面具有优势。此外,论文还强调了对不同架构进行全面比较的重要性,避免过度依赖单一架构。
关键设计:论文的关键设计包括:1) 使用prefix language modeling进行预训练,使Encoder-Decoder模型能够更好地处理生成任务;2) 采用与Decoder-Only模型相同的训练数据集和优化策略,保证公平的比较;3) 通过指令调优,提升模型在下游任务上的性能;4) 对不同模型规模进行实验,分析模型的缩放特性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RedLLM在预训练阶段的计算效率略低于DecLLM,但在指令调优后,RedLLM在各种下游任务上取得了相当甚至更好的结果,同时具有显著更高的推理效率。RedLLM还表现出与DecLLM相当的缩放性和上下文长度外推能力。这些结果表明,Encoder-Decoder架构在大语言模型领域仍具有竞争力。
🎯 应用场景
该研究成果可应用于需要高推理效率和长上下文处理能力的大语言模型应用场景,例如机器翻译、文档摘要、对话系统等。通过优化Encoder-Decoder架构,可以开发出更高效、更强大的大语言模型,从而提升相关应用的性能和用户体验。该研究也为未来大语言模型架构设计提供了新的思路。
📄 摘要(原文)
Recent large language model (LLM) research has undergone an architectural shift from encoder-decoder modeling to nowadays the dominant decoder-only modeling. This rapid transition, however, comes without a rigorous comparative analysis especially \textit{from the scaling perspective}, raising concerns that the potential of encoder-decoder models may have been overlooked. To fill this gap, we revisit encoder-decoder LLM (RedLLM), enhancing it with recent recipes from decoder-only LLM (DecLLM). We conduct a comprehensive comparison between RedLLM, pretrained with prefix language modeling (LM), and DecLLM, pretrained with causal LM, at different model scales, ranging from $\sim$150M to $\sim$8B. Using RedPajama V1 (1.6T tokens) for pretraining and FLAN for instruction tuning, our experiments show that RedLLM produces compelling scaling properties and surprisingly strong performance. While DecLLM is overall more compute-optimal during pretraining, RedLLM demonstrates comparable scaling and context length extrapolation capabilities. After instruction tuning, RedLLM achieves comparable and even better results on various downstream tasks while enjoying substantially better inference efficiency. We hope our findings could inspire more efforts on re-examining RedLLM, unlocking its potential for developing powerful and efficient LLMs.