SlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
作者: Yiqiao Jin, Rachneet Kaur, Zhen Zeng, Sumitra Ganesh, Srijan Kumar
分类: cs.CL
发布日期: 2025-10-30 (更新: 2025-11-01)
备注: https://slideagent.github.io/
💡 一句话要点
提出SlideAgent,用于多页视觉文档理解的分层Agent框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多页文档理解 视觉文档理解 分层Agent 多模态学习 幻灯片理解
📋 核心要点
- 现有系统难以处理复杂的多页视觉文档,尤其是在元素和页面上的细粒度推理方面。
- SlideAgent采用分层Agent框架,将推理分解为全局、页面和元素三个层次,构建结构化表示。
- 实验结果表明,SlideAgent在多页视觉文档理解任务上,显著优于专有模型和开源模型。
📝 摘要(中文)
多页视觉文档,如手册、宣传册、演示文稿和海报,通过布局、颜色、图标和跨页引用传递关键信息。虽然大型语言模型(LLM)在文档理解方面提供了机会,但当前的系统在处理复杂的多页视觉文档时存在困难,尤其是在元素和页面上的细粒度推理方面。我们介绍了SlideAgent,一个通用的Agent框架,用于理解多模态、多页和多布局的文档,特别是幻灯片。SlideAgent采用专门的Agent,并将推理分解为三个专门的层次——全局、页面和元素——以构建一个结构化的、与查询无关的表示,该表示既能捕捉到总体主题,又能捕捉到详细的视觉或文本线索。在推理过程中,SlideAgent选择性地激活专门的Agent进行多层次推理,并将它们的输出整合到连贯的、上下文感知的答案中。大量的实验表明,SlideAgent比专有模型(总体+7.9)和开源模型(总体+9.8)都有显著的改进。
🔬 方法详解
问题定义:论文旨在解决多页视觉文档理解的问题,现有方法难以进行细粒度的元素和页面推理,无法有效捕捉文档的全局主题和局部细节。现有方法在处理复杂布局和多模态信息时表现不佳。
核心思路:论文的核心思路是采用分层Agent框架,将文档理解任务分解为全局、页面和元素三个层次。通过专门的Agent在不同层次上进行推理,从而实现对文档的全面理解。这种分层结构能够更好地捕捉文档的整体结构和局部细节。
技术框架:SlideAgent框架包含三个主要层次的Agent:全局Agent负责理解文档的整体主题和结构;页面Agent负责理解单个页面的内容和布局;元素Agent负责理解页面中的具体元素(如文本、图像、图标)。在推理过程中,首先由全局Agent对文档进行初步理解,然后由页面Agent和元素Agent对每个页面进行详细分析,最后将各个Agent的输出整合起来,生成最终的答案。
关键创新:SlideAgent的关键创新在于其分层Agent框架,它能够有效地分解复杂的多页视觉文档理解任务,并利用专门的Agent在不同层次上进行推理。这种分层结构使得模型能够更好地捕捉文档的整体结构和局部细节,从而提高理解的准确性和效率。与现有方法相比,SlideAgent能够更好地处理复杂布局和多模态信息。
关键设计:SlideAgent的具体实现细节包括:每个Agent的具体结构(例如,可以使用Transformer模型);Agent之间的通信机制(例如,可以使用注意力机制);以及如何将各个Agent的输出整合起来(例如,可以使用加权平均或更复杂的融合方法)。论文中可能还涉及一些超参数的设置,例如Agent的数量、Transformer模型的层数等。损失函数的设计可能包括交叉熵损失、对比损失等,以提高模型的性能。
🖼️ 关键图片


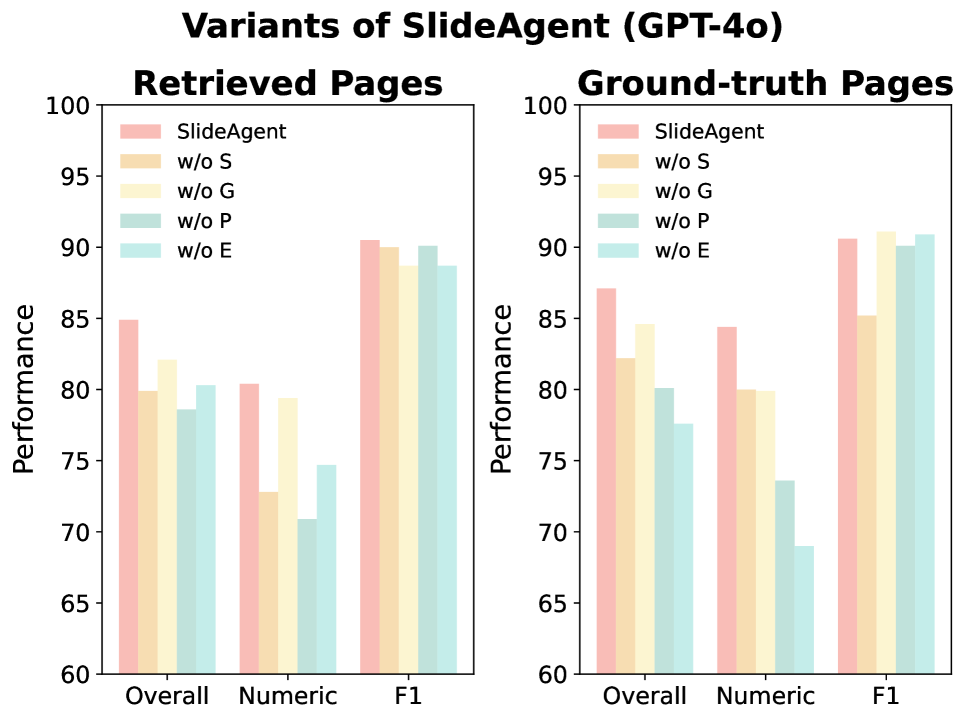
📊 实验亮点
SlideAgent在多页视觉文档理解任务上取得了显著的性能提升。实验结果表明,SlideAgent比专有模型(总体+7.9)和开源模型(总体+9.8)都有显著的改进。这些结果表明,SlideAgent的分层Agent框架能够有效地提高文档理解的准确性和效率。
🎯 应用场景
SlideAgent可应用于多种场景,如自动文档摘要、智能问答系统、信息检索、教育辅助工具等。例如,它可以帮助用户快速理解复杂的演示文稿,或者自动生成文档的摘要。该研究的潜在价值在于提高文档处理的效率和准确性,未来可能促进人机交互和知识管理的发展。
📄 摘要(原文)
Multi-page visual documents such as manuals, brochures, presentations, and posters convey key information through layout, colors, icons, and cross-slide references. While large language models (LLMs) offer opportunities in document understanding, current systems struggle with complex, multi-page visual documents, particularly in fine-grained reasoning over elements and pages. We introduce SlideAgent, a versatile agentic framework for understanding multi-modal, multi-page, and multi-layout documents, especially slide decks. SlideAgent employs specialized agents and decomposes reasoning into three specialized levels-global, page, and element-to construct a structured, query-agnostic representation that captures both overarching themes and detailed visual or textual cues. During inference, SlideAgent selectively activates specialized agents for multi-level reasoning and integrates their outputs into coherent, context-aware answers. Extensive experiments show that SlideAgent achieves significant improvement over both proprietary (+7.9 overall) and open-source models (+9.8 overall).