The Structure of Relation Decoding Linear Operators in Large Language Models
作者: Miranda Anna Christ, Adrián Csiszárik, Gergely Becsó, Dániel Varga
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-30
备注: NeurIPS 2025 (Spotlight)
💡 一句话要点
揭示大语言模型关系解码线性算子的结构,发现其主要基于语义属性而非特定关系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 关系解码 线性算子 语义属性 张量网络 知识表示 交叉评估
📋 核心要点
- 现有方法难以有效理解和压缩大语言模型中关系解码的线性算子。
- 论文提出通过张量网络压缩和交叉评估协议来分析关系解码器的结构。
- 实验表明关系解码器主要提取语义属性,而非特定关系,并可高度压缩。
📝 摘要(中文)
本文研究了Hernandez等人[2023]提出的用于解码Transformer语言模型中特定关系事实的线性算子的结构。我们将他们对单一关系的研究扩展到一系列关系,并系统地绘制了它们的组织结构。我们表明,这些关系解码器的集合可以通过简单的三阶张量网络高度压缩,而不会显著降低解码精度。为了解释这种令人惊讶的冗余,我们开发了一种交叉评估协议,在该协议中,我们将每个线性解码器算子应用于每个其他关系的主语。我们的结果表明,这些线性映射并不编码不同的关系,而是提取重复出现的、粗粒度的语义属性(例如,首都所在的国家和食物所在的国家都属于国家-X属性)。这种以属性为中心的结构既阐明了算子的可压缩性,也突出了它们为什么只泛化到语义上接近的新关系。因此,我们的研究结果将Transformer语言模型中的线性关系解码解释为主要基于属性,而不是特定于关系。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLM)中用于关系解码的线性算子的内部结构。现有方法通常将这些算子视为独立的、关系特定的解码器,但缺乏对其组织方式和泛化能力的深入理解。痛点在于,这些算子可能存在冗余,且泛化能力受限,难以应用于新的、语义上不同的关系。
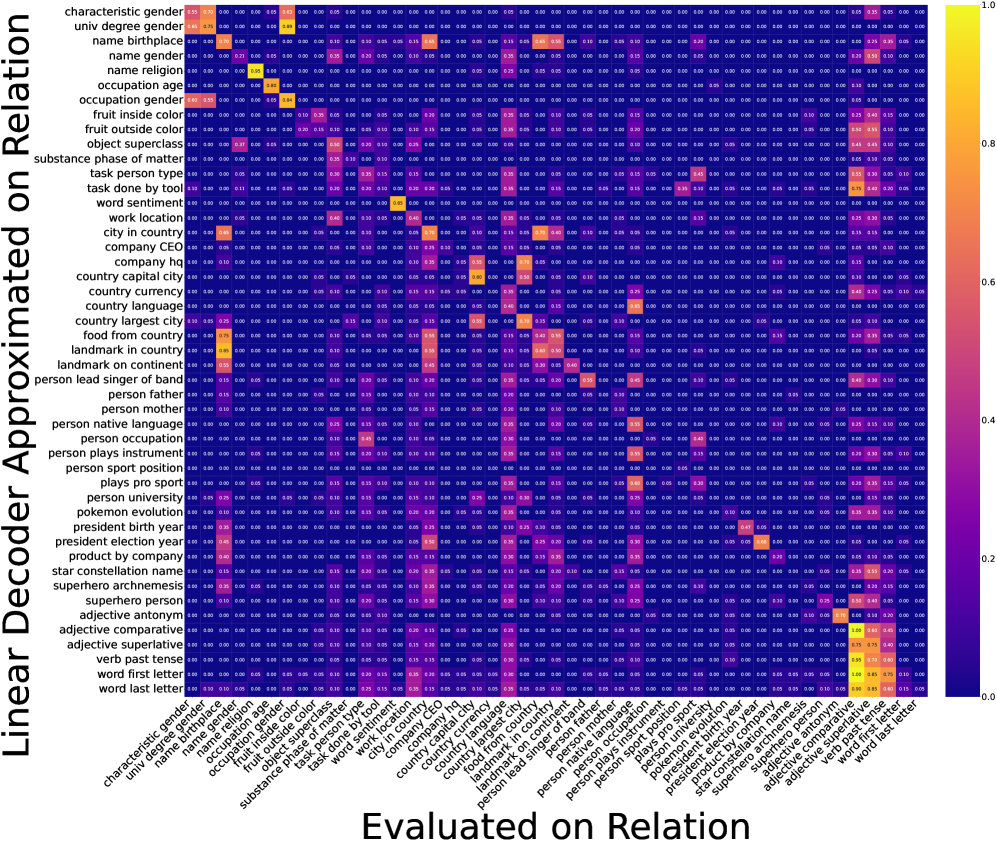
核心思路:论文的核心思路是,这些线性算子实际上并不编码特定的关系,而是提取更通用的、粗粒度的语义属性。例如,“首都所在的国家”和“食物所在的国家”都属于“国家-X”这一属性。通过分析算子之间的关系,可以揭示其潜在的语义结构,并解释其可压缩性和泛化能力。
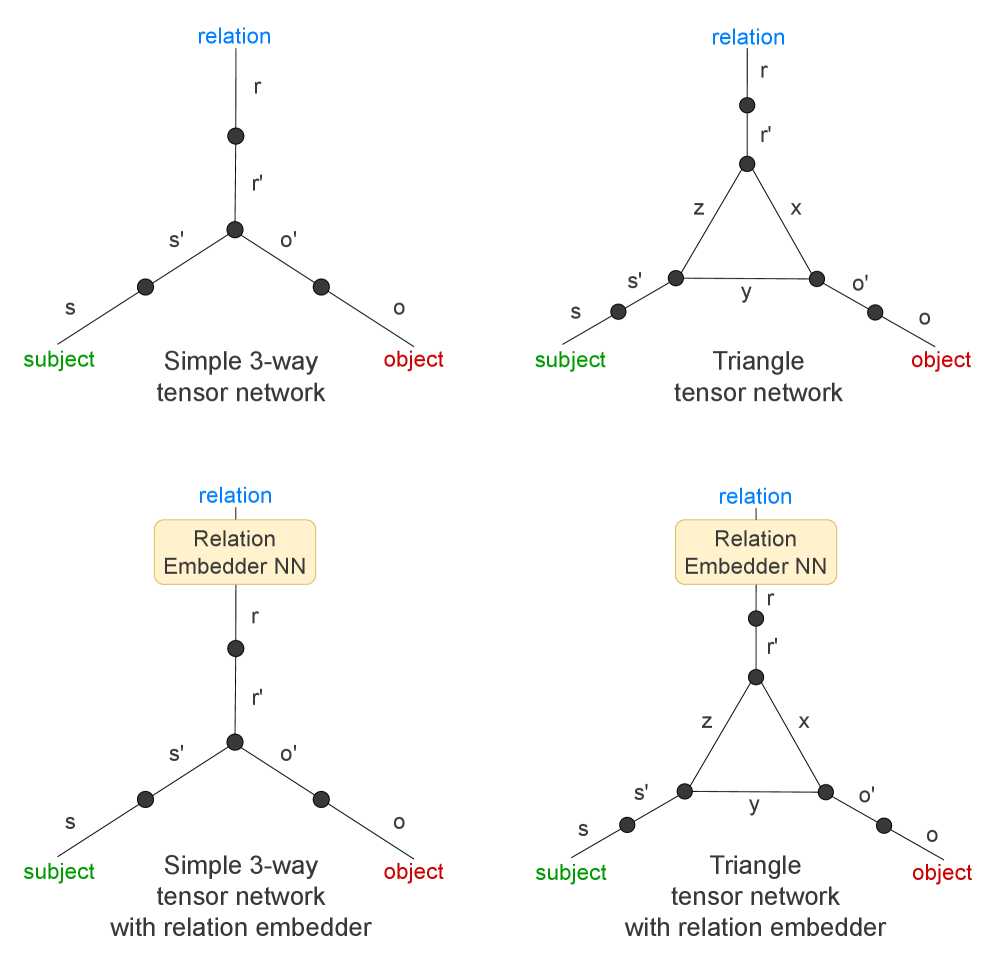
技术框架:论文的技术框架主要包括以下几个步骤:1) 将单关系的研究扩展到一系列关系;2) 使用三阶张量网络压缩关系解码器集合;3) 开发交叉评估协议,将每个线性解码器算子应用于其他关系的主语;4) 分析交叉评估结果,揭示算子提取的语义属性。
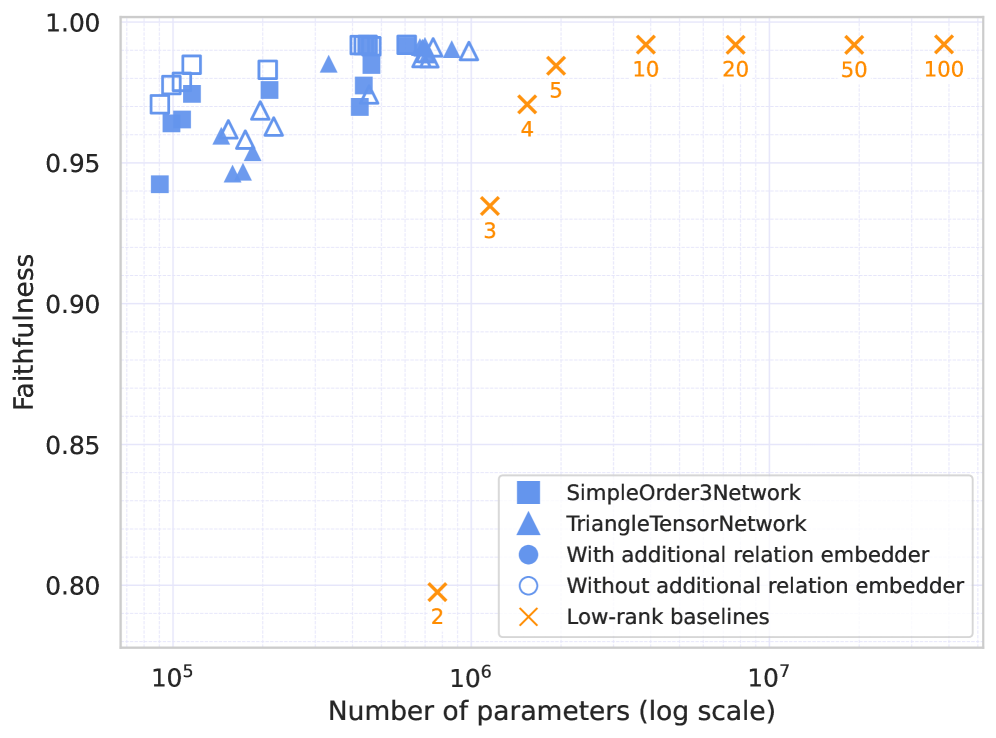
关键创新:论文的关键创新在于:1) 提出了一种交叉评估协议,用于分析关系解码器之间的关系;2) 揭示了关系解码器主要提取语义属性,而非特定关系;3) 证明了关系解码器可以通过简单的张量网络高度压缩,而不会显著降低解码精度。
关键设计:论文的关键设计包括:1) 使用三阶张量网络进行压缩,选择合适的秩以平衡压缩率和解码精度;2) 设计交叉评估协议,系统地将每个解码器应用于其他关系的主语,并分析解码结果;3) 定义语义属性,并根据交叉评估结果将解码器归类到不同的属性中。
🖼️ 关键图片
📊 实验亮点
实验结果表明,关系解码器可以通过简单的三阶张量网络高度压缩,而不会显著降低解码精度。交叉评估结果显示,这些解码器主要提取语义属性,而非特定关系,解释了其可压缩性和泛化能力。
🎯 应用场景
该研究成果可应用于提升大语言模型的知识表示和推理能力,例如,通过更有效地存储和检索关系信息,提高问答系统的准确性和效率。此外,该研究有助于理解大语言模型的内部工作机制,为模型优化和改进提供理论指导。
📄 摘要(原文)
This paper investigates the structure of linear operators introduced in Hernandez et al. [2023] that decode specific relational facts in transformer language models. We extend their single-relation findings to a collection of relations and systematically chart their organization. We show that such collections of relation decoders can be highly compressed by simple order-3 tensor networks without significant loss in decoding accuracy. To explain this surprising redundancy, we develop a cross-evaluation protocol, in which we apply each linear decoder operator to the subjects of every other relation. Our results reveal that these linear maps do not encode distinct relations, but extract recurring, coarse-grained semantic properties (e.g., country of capital city and country of food are both in the country-of-X property). This property-centric structure clarifies both the operators' compressibility and highlights why they generalize only to new relations that are semantically close. Our findings thus interpret linear relational decoding in transformer language models as primarily property-based, rather than relation-specific.