1+1>2: A Synergistic Sparse and Low-Rank Compression Method for Large Language Models
作者: Zeliang Zong, Kai Zhang, Zheyang Li, Wenming Tan, Ye Ren, Yiyan Zhai, Jilin Hu
分类: cs.CL
发布日期: 2025-10-30
备注: 15 pages, 6 figures, EMNLP 2025 findings
💡 一句话要点
提出协同稀疏与低秩压缩方法SSLC,高效压缩大型语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型压缩 稀疏优化 低秩近似 模型加速 协同优化
📋 核心要点
- 大型语言模型部署受限于高昂的计算和存储成本,现有压缩方法(如剪枝和低秩分解)单独使用效果有限。
- 论文提出SSLC方法,将低秩近似和稀疏优化统一建模,通过迭代优化算法,协同压缩模型。
- 实验表明,SSLC在LLaMA和Qwen2.5模型上优于单独方法,在不损失性能情况下压缩50%,加速1.63倍。
📝 摘要(中文)
大型语言模型(LLMs)在语言理解和生成方面表现出卓越的能力;然而,其广泛应用受到大量带宽和计算需求的限制。虽然剪枝和低秩近似各自都表现出有希望的性能,但它们在LLM中的协同作用仍未被充分探索。我们为LLM引入了协同稀疏和低秩压缩(SSLC)方法,该方法利用了这两种技术的优势:低秩近似通过保留其基本结构以最小的信息损失来压缩模型,而稀疏优化消除了非必要的权重,保留了对泛化至关重要的权重。基于理论分析,我们首先将低秩近似和稀疏优化公式化为一个统一的问题,并通过迭代优化算法解决它。在LLaMA和Qwen2.5模型(7B-70B)上的实验表明,SSLC在没有任何额外训练步骤的情况下,始终超越了独立方法,实现了最先进的结果。值得注意的是,SSLC在不降低性能的情况下将Qwen2.5压缩了50%,并实现了至少1.63倍的加速,为高效的LLM部署提供了实用的解决方案。
🔬 方法详解
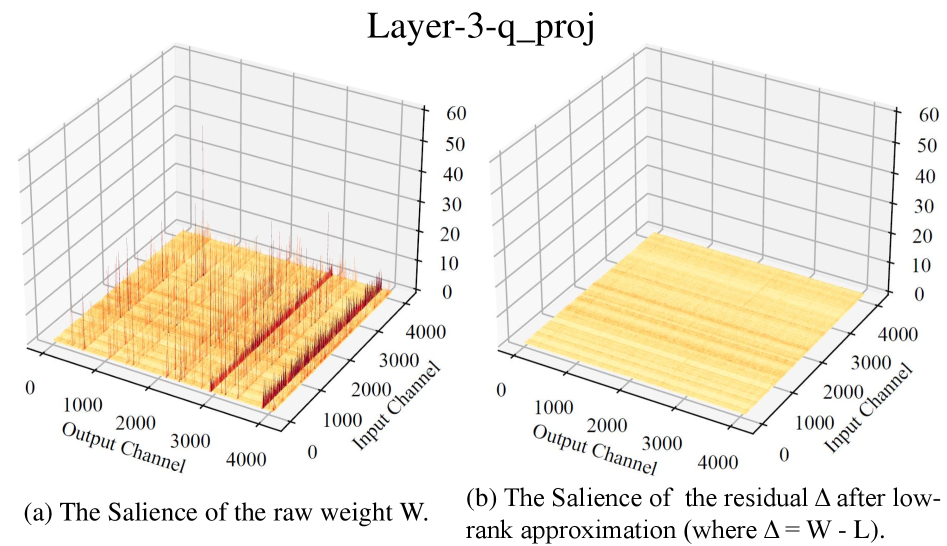
问题定义:大型语言模型参数量巨大,部署成本高昂。现有的模型压缩方法,如剪枝和低秩分解,虽然可以降低模型大小,但单独使用时往往难以在压缩率和性能之间取得平衡。剪枝容易导致模型泛化能力下降,而低秩分解可能丢失重要的模型结构信息。因此,如何协同利用这两种方法,实现更高的压缩率和更好的性能,是一个亟待解决的问题。
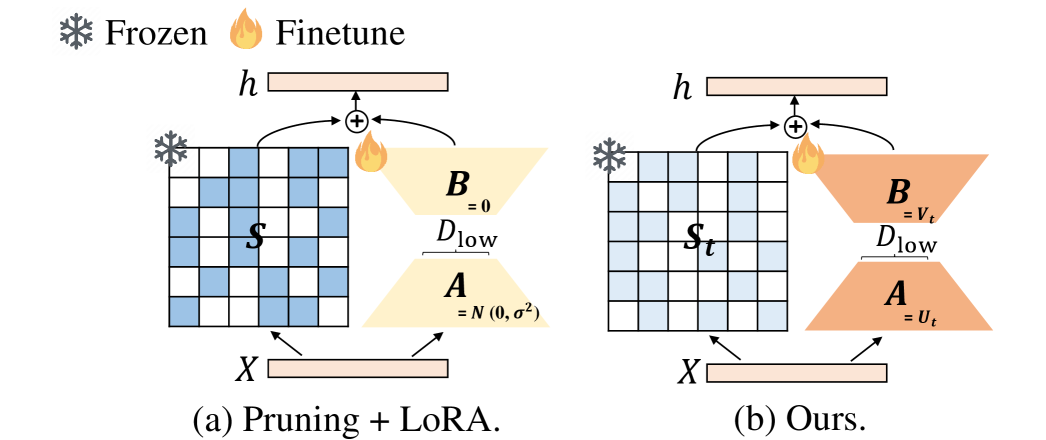
核心思路:论文的核心思路是将低秩近似和稀疏优化结合起来,形成一个协同压缩框架。低秩近似用于保留模型的主要结构信息,减少冗余参数,而稀疏优化则用于去除不重要的权重,进一步压缩模型。通过协同优化这两种方法,可以充分利用它们的优势,实现更高的压缩率,同时保持模型的性能。
技术框架:SSLC方法的技术框架主要包含以下几个步骤:1. 统一建模:将低秩近似和稀疏优化问题统一到一个数学模型中。2. 迭代优化:设计迭代优化算法,交替更新低秩矩阵和稀疏掩码。3. 模型压缩:利用优化后的低秩矩阵和稀疏掩码对原始模型进行压缩。具体来说,首先对模型的权重矩阵进行低秩分解,得到两个低秩矩阵。然后,对权重矩阵进行稀疏化,得到一个稀疏掩码。最后,将低秩矩阵和稀疏掩码应用于原始模型,得到压缩后的模型。
关键创新:SSLC方法的关键创新在于将低秩近似和稀疏优化统一到一个框架中,并设计了迭代优化算法来协同优化这两种方法。与传统的独立使用剪枝或低秩分解的方法相比,SSLC方法能够更好地平衡压缩率和性能,实现更高的压缩效率。此外,该方法无需额外的训练步骤,可以直接应用于预训练模型,降低了部署成本。
关键设计:论文中关键的设计包括:1. 统一的优化目标:设计了一个包含低秩约束和稀疏约束的优化目标函数,用于同时优化低秩矩阵和稀疏掩码。2. 迭代优化算法:采用交替最小化的方法,迭代更新低秩矩阵和稀疏掩码,直到收敛。3. 稀疏掩码的生成:使用基于梯度的稀疏化方法,根据权重的重要性生成稀疏掩码。4. 低秩分解的实现:采用奇异值分解(SVD)或随机SVD等方法进行低秩分解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SSLC方法在LLaMA和Qwen2.5模型(7B-70B)上取得了显著的压缩效果。在不进行额外训练的情况下,SSLC超越了单独使用剪枝或低秩分解的方法,实现了最先进的性能。例如,SSLC在不损失性能的情况下将Qwen2.5模型压缩了50%,并实现了至少1.63倍的推理加速。这些结果表明SSLC是一种高效且实用的LLM压缩方法。
🎯 应用场景
SSLC方法可广泛应用于大型语言模型的部署和推理加速,尤其是在资源受限的边缘设备上。通过降低模型大小和计算复杂度,SSLC能够使LLM在移动设备、嵌入式系统等平台上运行,从而推动LLM在智能助手、自动驾驶、物联网等领域的应用。此外,该方法还可以用于模型蒸馏和知识迁移,提高小模型的性能。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable proficiency in language comprehension and generation; however, their widespread adoption is constrained by substantial bandwidth and computational demands. While pruning and low-rank approximation have each demonstrated promising performance individually, their synergy for LLMs remains underexplored. We introduce \underline{S}ynergistic \underline{S}parse and \underline{L}ow-Rank \underline{C}ompression (SSLC) methods for LLMs, which leverages the strengths of both techniques: low-rank approximation compresses the model by retaining its essential structure with minimal information loss, whereas sparse optimization eliminates non-essential weights, preserving those crucial for generalization. Based on theoretical analysis, we first formulate the low-rank approximation and sparse optimization as a unified problem and solve it by iterative optimization algorithm. Experiments on LLaMA and Qwen2.5 models (7B-70B) show that SSLC, without any additional training steps, consistently surpasses standalone methods, achieving state-of-the-arts results. Notably, SSLC compresses Qwen2.5 by 50\% with no performance drop and achieves at least 1.63$\times$ speedup, offering a practical solution for efficient LLM deployment.