OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
作者: Min Zhang, Hao Chen, Hao Chen, Wenqi Zhang, Didi Zhu, Xin Lin, Bo Jiang, Aimin Zhou, Fei Wu, Kun Kuang
分类: cs.CL
发布日期: 2025-10-30
💡 一句话要点
提出OmniEduBench,用于全面评估中文教育领域大语言模型能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 教育基准 中文评测 知识维度 能力培养 智能教育 LLM评估
📋 核心要点
- 现有LLM教育基准侧重知识维度,忽略能力培养评估,且缺乏学科和题型多样性,尤其是在中文环境下。
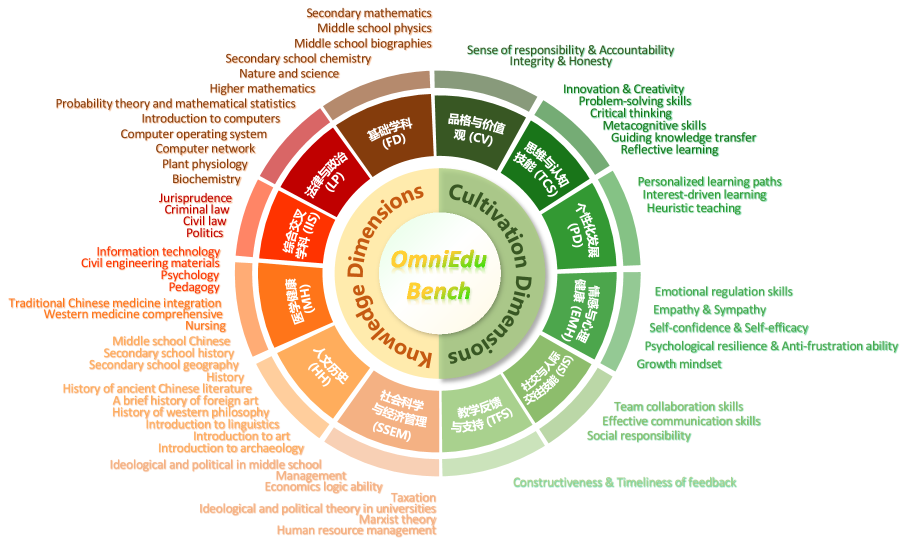
- OmniEduBench构建包含知识和培养维度,覆盖61个学科和11种题型的中文教育基准,以全面评估LLM能力。
- 实验表明,现有LLM在知识维度表现尚可,但在培养维度与人类智能差距显著,存在巨大提升空间。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,各种基于LLM的工作已广泛应用于教育领域。然而,现有的大多数LLM及其基准主要侧重于知识维度,很大程度上忽略了对实际教育场景至关重要的能力培养的评估。此外,当前的基准通常仅限于单一学科或问题类型,缺乏足够的多元性,尤其是在中文环境中。为了解决这一差距,我们推出了OmniEduBench,这是一个全面的中文教育基准。OmniEduBench包含24.602K个高质量的问答对,数据被细致地分为两个核心维度:知识维度和培养维度,分别包含18.121K和6.481K个条目。每个维度又进一步细分为6个细粒度类别,涵盖总共61个不同的科目(知识维度41个,培养维度20个)。此外,该数据集具有丰富的题型,包括11种常见的考试题型,为全面评估LLM在教育领域的能力提供了坚实的基础。对11个主流开源和闭源LLM的广泛实验揭示了明显的性能差距。在知识维度上,只有Gemini-2.5 Pro超过了60%的准确率,而在培养维度上,表现最佳的模型QWQ仍然落后于人类智能近30%。这些结果突出了巨大的改进空间,并强调了LLM在教育领域应用所面临的挑战。
🔬 方法详解
问题定义:现有的大语言模型教育评测基准主要关注知识掌握程度,忽略了对学生能力培养的评估,例如批判性思维、创造力等。此外,现有基准覆盖的学科和题型有限,难以全面评估LLM在真实教育场景中的应用潜力。尤其是在中文教育领域,高质量、综合性的评测基准仍然匮乏。
核心思路:为了解决上述问题,论文构建了一个名为OmniEduBench的中文教育基准。该基准的核心思路是将教育目标分解为知识维度和培养维度,并针对每个维度设计了细粒度的分类和多样化的题型。通过这种方式,可以更全面、更深入地评估LLM在教育领域的表现。
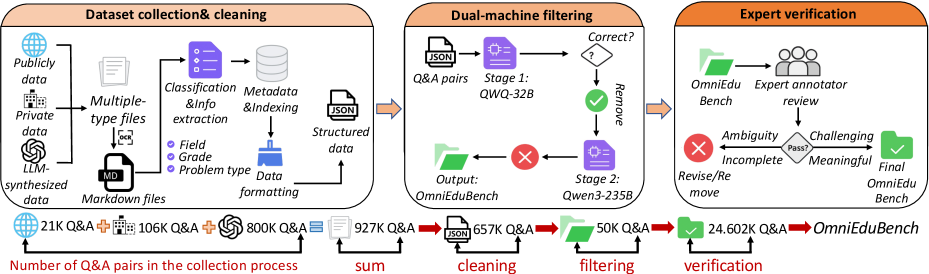
技术框架:OmniEduBench数据集的构建流程主要包括以下几个阶段:1) 确定知识维度和培养维度的细粒度分类;2) 收集和整理涵盖不同学科和题型的教育数据;3) 对数据进行清洗、标注和质量控制;4) 将数据划分为训练集、验证集和测试集。数据集包含24.602K个高质量的问答对,分为知识维度(18.121K)和培养维度(6.481K),每个维度又细分为6个类别,覆盖61个学科,包含11种题型。
关键创新:OmniEduBench的关键创新在于其对教育目标的全面覆盖和细粒度划分。与以往的基准相比,OmniEduBench不仅关注知识的掌握,还关注能力的培养,例如批判性思维、创造力、解决问题的能力等。此外,OmniEduBench还提供了更丰富的学科和题型,可以更全面地评估LLM在教育领域的应用潜力。
关键设计:数据集的构建过程中,作者们精心设计了每个维度和类别的题目,力求覆盖不同的知识点和能力点。在数据清洗和标注方面,采用了多轮人工审核的方式,确保数据的质量和准确性。此外,作者还设计了一套评估指标,用于衡量LLM在不同维度和类别上的表现。
🖼️ 关键图片

📊 实验亮点
在OmniEduBench上的实验结果表明,现有LLM在知识维度上的表现相对较好,但仍有提升空间,Gemini-2.5 Pro在该维度上超过60%准确率。在培养维度上,LLM的表现远低于人类水平,表现最佳的模型QWQ仍然落后人类智能近30%。这表明LLM在培养学生的批判性思维、创造力等方面的能力仍有待提高。
🎯 应用场景
OmniEduBench可用于评估和提升LLM在教育领域的应用,例如智能辅导系统、自动阅卷系统、个性化学习推荐等。该基准能够帮助研究人员更好地了解LLM在教育领域的优势和不足,从而开发出更有效、更智能的教育工具。此外,OmniEduBench还可以促进教育领域的创新,推动教育的智能化转型。
📄 摘要(原文)
With the rapid development of large language models (LLMs), various LLM-based works have been widely applied in educational fields. However, most existing LLMs and their benchmarks focus primarily on the knowledge dimension, largely neglecting the evaluation of cultivation capabilities that are essential for real-world educational scenarios. Additionally, current benchmarks are often limited to a single subject or question type, lacking sufficient diversity. This issue is particularly prominent within the Chinese context. To address this gap, we introduce OmniEduBench, a comprehensive Chinese educational benchmark. OmniEduBench consists of 24.602K high-quality question-answer pairs. The data is meticulously divided into two core dimensions: the knowledge dimension and the cultivation dimension, which contain 18.121K and 6.481K entries, respectively. Each dimension is further subdivided into 6 fine-grained categories, covering a total of 61 different subjects (41 in the knowledge and 20 in the cultivation). Furthermore, the dataset features a rich variety of question formats, including 11 common exam question types, providing a solid foundation for comprehensively evaluating LLMs' capabilities in education. Extensive experiments on 11 mainstream open-source and closed-source LLMs reveal a clear performance gap. In the knowledge dimension, only Gemini-2.5 Pro surpassed 60\% accuracy, while in the cultivation dimension, the best-performing model, QWQ, still trailed human intelligence by nearly 30\%. These results highlight the substantial room for improvement and underscore the challenges of applying LLMs in education.