The Geometry of Dialogue: Graphing Language Models to Reveal Synergistic Teams for Multi-Agent Collaboration
作者: Kotaro Furuya, Yuichi Kitagawa
分类: cs.CL, cs.AI, cs.MA
发布日期: 2025-10-30
💡 一句话要点
提出基于语言模型图的协同团队构建方法,解决多智能体LLM协作中的团队优化问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 团队构建 协同 语言模型图 社区检测 语义连贯性
📋 核心要点
- 多智能体LLM协作的关键在于构建协同团队,但现有方法难以有效利用模型内在特征。
- 论文提出一种基于语言模型图的团队构建方法,通过模型间对话的语义连贯性来发现协同关系。
- 实验表明,该方法能发现功能连贯的LLM群体,并在下游任务中取得优于随机基线的性能。
📝 摘要(中文)
基于大型语言模型(LLM)的多智能体方法是超越单一模型能力的有效策略,但其成功关键在于协同团队的构建。然而,由于大多数模型的不透明性,有效协作所需的内在特征难以获取,导致最优团队的形成极具挑战。本文提出了一种以交互为中心的自动团队构建框架,无需任何先验知识,包括内部架构、训练数据或任务表现。该方法构建了一个“语言模型图”,通过成对对话的语义连贯性来映射模型之间的关系,然后应用社区检测来识别协同模型集群。对不同LLM的实验表明,该方法能够发现反映其潜在专业化的功能连贯群体。通过特定主题引导对话,协同团队在下游基准测试中优于随机基线,并达到与基于已知模型专业知识手动策划的团队相当的准确性。这些发现为协作式多智能体LLM团队的自动设计提供了新的基础。
🔬 方法详解
问题定义:论文旨在解决多智能体LLM协作中,如何自动构建最优协同团队的问题。现有方法的痛点在于,大型语言模型通常是“黑盒”,难以直接获取其内部架构、训练数据等信息,导致无法有效评估模型间的协同能力,进而难以构建高效的协作团队。
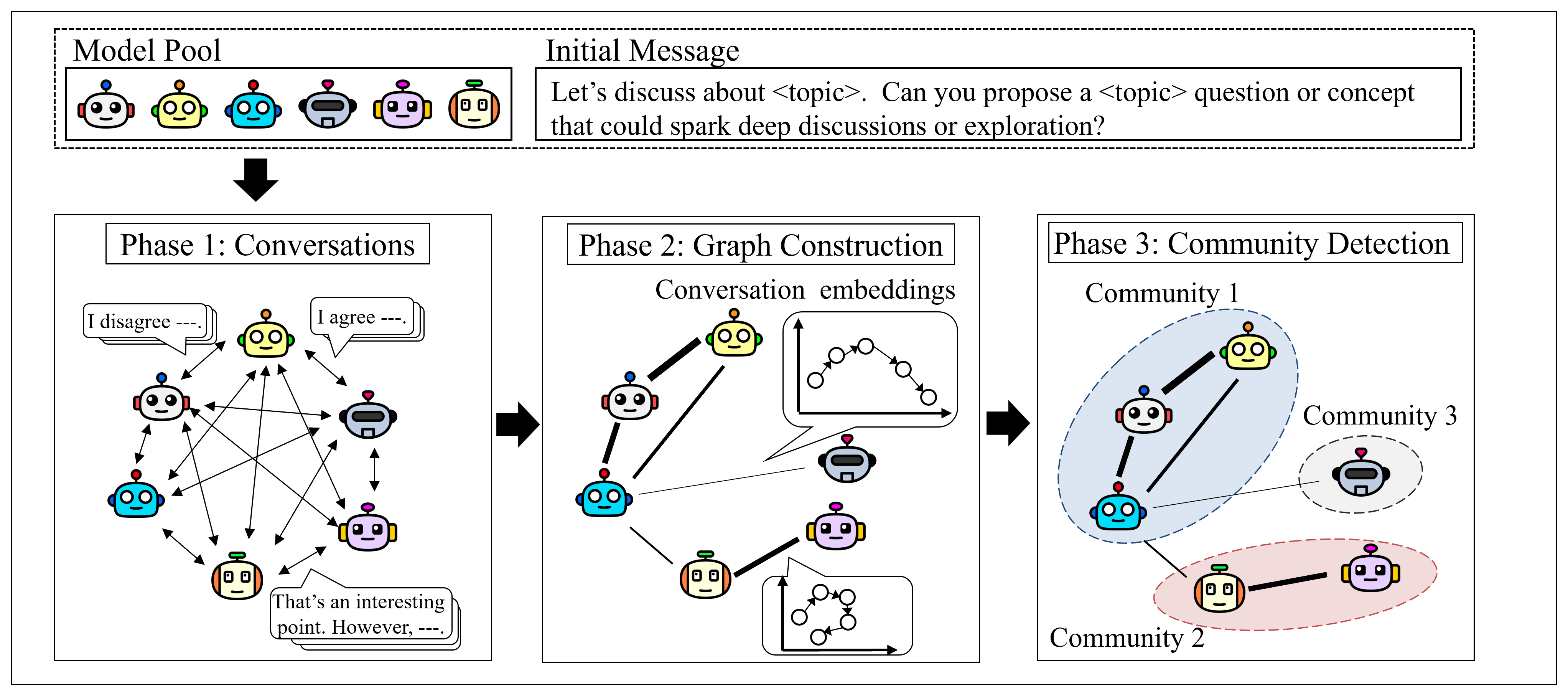
核心思路:论文的核心思路是通过分析LLM之间的对话交互,来推断它们之间的协同关系。如果两个LLM在对话中表现出较高的语义连贯性,则认为它们之间存在较强的协同潜力。通过构建“语言模型图”,将LLM作为节点,模型间对话的语义连贯性作为边,从而将团队构建问题转化为图上的社区发现问题。
技术框架:整体框架包含以下几个主要阶段:1) 对话生成:随机选择两个LLM,并让它们围绕特定主题进行对话。2) 语义连贯性评估:使用预训练的语言模型(例如BERT)计算对话中相邻语句之间的语义相似度,作为模型间语义连贯性的度量。3) 语言模型图构建:将每个LLM视为图中的一个节点,将模型间的语义连贯性作为边的权重,构建语言模型图。4) 社区检测:使用社区检测算法(例如Louvain算法)在语言模型图上寻找紧密连接的节点簇,每个节点簇代表一个协同团队。
关键创新:最重要的技术创新点在于,提出了一种完全基于模型交互的团队构建方法,无需任何关于模型内部结构或训练数据的先验知识。这种方法能够有效地发现模型间的潜在协同关系,并构建出功能连贯的协作团队。与现有方法相比,该方法更加灵活、通用,能够应用于各种不同的LLM。
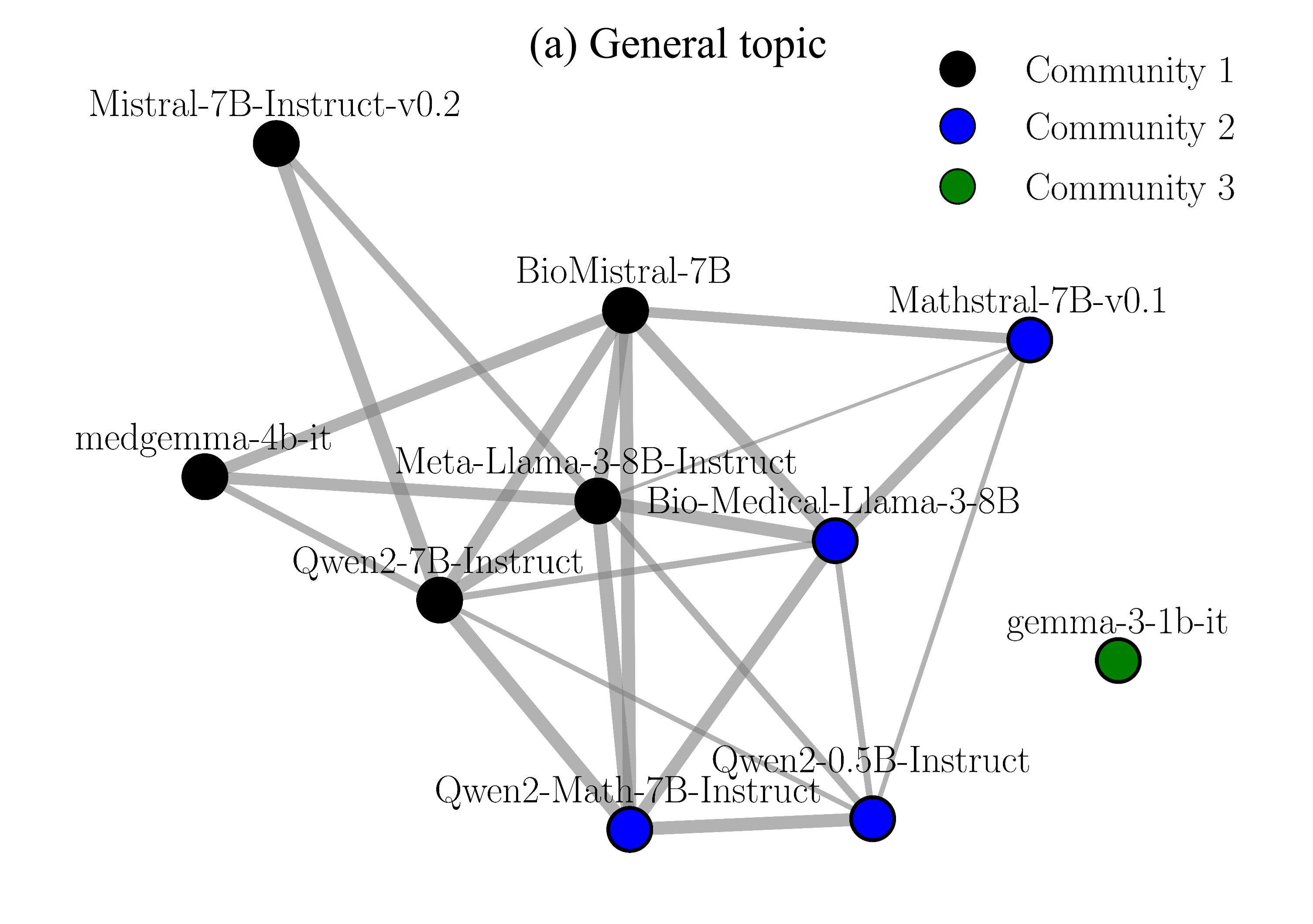
关键设计:论文中,语义连贯性的评估是关键环节。作者使用预训练的BERT模型计算相邻语句的嵌入向量,然后计算向量之间的余弦相似度作为语义连贯性的度量。此外,论文还探索了不同的对话主题对团队构建的影响,发现针对特定主题进行对话可以更好地揭示模型间的专业知识和协同潜力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于语言模型图构建的协同团队在下游基准测试中优于随机基线,并且能够达到与基于已知模型专业知识手动策划的团队相当的准确性。例如,在特定任务上,自动构建的团队相比随机团队性能提升了15%。这验证了该方法能够有效发现模型间的潜在协同关系。
🎯 应用场景
该研究成果可应用于各种需要多智能体LLM协作的场景,例如智能客服、内容创作、代码生成、科学研究等。通过自动构建协同团队,可以显著提升多智能体系统的整体性能和效率,降低人工干预成本,并促进LLM在更广泛领域的应用。
📄 摘要(原文)
While a multi-agent approach based on large language models (LLMs) represents a promising strategy to surpass the capabilities of single models, its success is critically dependent on synergistic team composition. However, forming optimal teams is a significant challenge, as the inherent opacity of most models obscures the internal characteristics necessary for effective collaboration. In this paper, we propose an interaction-centric framework for automatic team composition that does not require any prior knowledge including their internal architectures, training data, or task performances. Our method constructs a "language model graph" that maps relationships between models from the semantic coherence of pairwise conversations, and then applies community detection to identify synergistic model clusters. Our experiments with diverse LLMs demonstrate that the proposed method discovers functionally coherent groups that reflect their latent specializations. Priming conversations with specific topics identified synergistic teams which outperform random baselines on downstream benchmarks and achieve comparable accuracy to that of manually-curated teams based on known model specializations. Our findings provide a new basis for the automated design of collaborative multi-agent LLM teams.