MisSynth: Improving MISSCI Logical Fallacies Classification with Synthetic Data
作者: Mykhailo Poliakov, Nadiya Shvai
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-30
🔗 代码/项目: GITHUB
💡 一句话要点
MisSynth:利用合成数据提升MISSCI谬误逻辑分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 谬误逻辑识别 合成数据生成 检索增强生成 大型语言模型 健康信息 MISSCI数据集
📋 核心要点
- 现有方法难以有效识别扭曲科学发现的健康相关不实信息,尤其是在谬误论证的情况下。
- MisSynth利用检索增强生成(RAG)技术生成合成谬误样本,用于微调大型语言模型,提升分类性能。
- 实验表明,使用MisSynth微调的模型在MISSCI测试集上F1分数提升超过35%,显著优于原始基线。
📝 摘要(中文)
与健康相关的不实信息非常普遍且具有潜在危害。尤其当这些信息扭曲或错误解读科学发现时,识别它们变得更加困难。本研究探讨了合成数据生成和轻量级微调技术对大型语言模型(LLMs)识别谬误论证能力的影响,使用了MISSCI数据集和框架。我们提出了MisSynth,一个应用检索增强生成(RAG)来生成合成谬误样本的流程,然后使用这些样本来微调LLM模型。结果表明,与原始基线相比,微调后的模型在准确性方面取得了显著提高。例如,经过微调的LLaMA 3.1 8B模型在MISSCI测试集上实现了超过35%的F1分数绝对提升。我们证明了引入合成谬误数据来扩充有限的标注资源可以显著提高零样本LLM在真实世界科学不实信息任务中的分类性能,即使在有限的计算资源下也是如此。代码和合成数据集可在https://github.com/mxpoliakov/MisSynth上获取。
🔬 方法详解
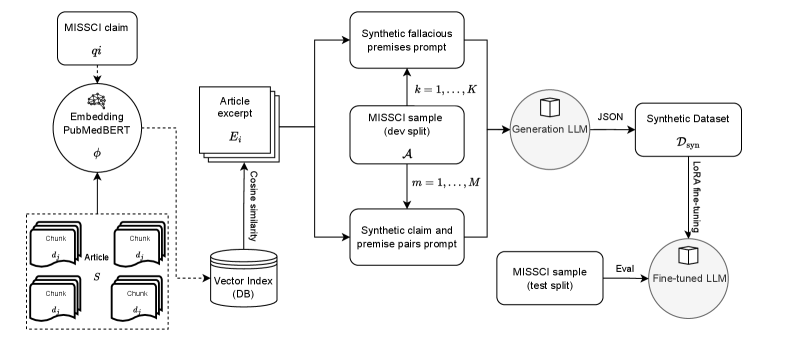
问题定义:论文旨在解决健康相关不实信息中谬误逻辑识别的问题。现有方法在处理此类问题时,面临标注数据稀缺的挑战,导致大型语言模型难以有效识别和分类这些谬误。因此,如何利用有限的标注数据提升模型性能是关键问题。
核心思路:论文的核心思路是利用合成数据增强技术,生成更多样化、更具代表性的谬误样本,从而扩充训练数据集,提升模型泛化能力。通过检索增强生成(RAG),模型可以学习到更多关于谬误论证的知识,从而更好地识别和分类真实世界中的谬误信息。
技术框架:MisSynth的整体框架包含以下几个主要阶段:1) 数据检索:从现有知识库或数据集中检索与谬误论证相关的文本片段。2) 谬误生成:利用检索到的文本片段,通过RAG模型生成新的合成谬误样本。3) 模型微调:使用合成数据微调大型语言模型,使其更好地识别和分类谬误论证。4) 性能评估:在真实世界的MISSCI数据集上评估微调后模型的性能。
关键创新:该论文的关键创新在于提出了一个基于检索增强生成(RAG)的合成数据生成流程,专门用于生成谬误论证样本。与传统的生成方法相比,RAG能够更好地利用现有知识,生成更具逻辑性和真实性的谬误样本,从而更有效地提升模型的分类性能。
关键设计:在RAG模型的设计上,论文可能采用了特定的检索策略,例如基于关键词或语义相似度的检索方法。在生成阶段,可能使用了特定的提示工程(Prompt Engineering)技术,引导模型生成符合特定谬误类型的样本。此外,在微调阶段,可能采用了特定的学习率调度策略或正则化方法,以防止过拟合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用MisSynth生成的合成数据进行微调后,LLaMA 3.1 8B模型在MISSCI测试集上取得了显著的性能提升,F1分数绝对提升超过35%,证明了该方法在提升谬误逻辑分类性能方面的有效性。该结果表明,即使在标注数据有限的情况下,通过合成数据增强技术也能显著提升大型语言模型的性能。
🎯 应用场景
该研究成果可应用于自动识别和过滤在线健康信息中的谬误论证,帮助用户获取更可靠的健康信息。此外,该方法还可扩展到其他领域,例如金融、政治等,用于识别和防范虚假信息和恶意宣传。未来,该研究可以进一步探索更有效的合成数据生成方法和模型微调技术,以提升模型在复杂场景下的识别能力。
📄 摘要(原文)
Health-related misinformation is very prevalent and potentially harmful. It is difficult to identify, especially when claims distort or misinterpret scientific findings. We investigate the impact of synthetic data generation and lightweight fine-tuning techniques on the ability of large language models (LLMs) to recognize fallacious arguments using the MISSCI dataset and framework. In this work, we propose MisSynth, a pipeline that applies retrieval-augmented generation (RAG) to produce synthetic fallacy samples, which are then used to fine-tune an LLM model. Our results show substantial accuracy gains with fine-tuned models compared to vanilla baselines. For instance, the LLaMA 3.1 8B fine-tuned model achieved an over 35% F1-score absolute improvement on the MISSCI test split over its vanilla baseline. We demonstrate that introducing synthetic fallacy data to augment limited annotated resources can significantly enhance zero-shot LLM classification performance on real-world scientific misinformation tasks, even with limited computational resources. The code and synthetic dataset are available on https://github.com/mxpoliakov/MisSynth.