From Amateur to Master: Infusing Knowledge into LLMs via Automated Curriculum Learning
作者: Nishit Neema, Srinjoy Mukherjee, Sapan Shah, Gokul Ramakrishnan, Ganesh Venkatesh
分类: cs.CL, cs.AI
发布日期: 2025-10-30
💡 一句话要点
ACER:通过自动化课程学习将知识注入大型语言模型,提升领域专业性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识注入 自动化课程学习 持续预训练 领域专业性 布鲁姆分类法 知识迁移
📋 核心要点
- 大型语言模型在特定领域知识方面存在不足,难以胜任需要深入理解的专业任务。
- ACER通过自动化生成课程,并利用布鲁姆分类法构建问答对,系统性地提升模型在特定领域的知识水平。
- 实验表明,ACER显著提升了模型在专业领域的性能,同时防止了灾难性遗忘,并促进了跨领域知识迁移。
📝 摘要(中文)
大型语言模型(LLMs)在通用任务中表现出色,但在经济学和心理学等需要深入理解的专业领域表现不佳。为了解决这个问题,我们引入了自动化课程增强方案(ACER),该方案将通用模型转化为领域专家,同时不牺牲其广泛的能力。ACER首先通过为主题生成目录,然后根据布鲁姆分类法创建问答(QA)对,从而合成全面的教科书式课程。这确保了系统的主题覆盖和难度逐渐增加。由此产生的合成语料库用于持续预训练,并采用交错的课程表,从而在内容和认知维度上对齐学习。使用Llama 3.2(1B和3B)进行的实验表明,在专门的MMLU子集中获得了显著的收益。在微观经济学等具有挑战性的领域,ACER将准确率提高了5个百分点。在所有目标领域中,我们观察到宏平均一致提高了3个百分点。值得注意的是,ACER不仅可以防止灾难性遗忘,还可以促进积极的跨领域知识转移,从而将非目标领域的性能提高了0.7个百分点。除了MMLU之外,ACER还将ARC和GPQA等知识密集型基准的性能提高了2个百分点以上,同时保持了通用推理任务的稳定性能。我们的结果表明,ACER为缩小LLM中的关键领域差距提供了一种可扩展且有效的方案。
🔬 方法详解
问题定义:大型语言模型虽然在通用任务上表现出色,但在经济学、心理学等专业领域,由于缺乏深入的领域知识,性能往往不尽如人意。现有的方法难以在提升领域专业性的同时,保持模型的通用能力,并且容易出现灾难性遗忘现象。
核心思路:ACER的核心思路是通过自动化生成课程,引导模型进行持续预训练,从而将领域知识注入模型。该方法借鉴了人类学习的模式,即从基础知识开始,逐步深入,最终掌握复杂的概念。通过精心设计的课程,模型可以系统地学习领域知识,并避免遗忘已学知识。
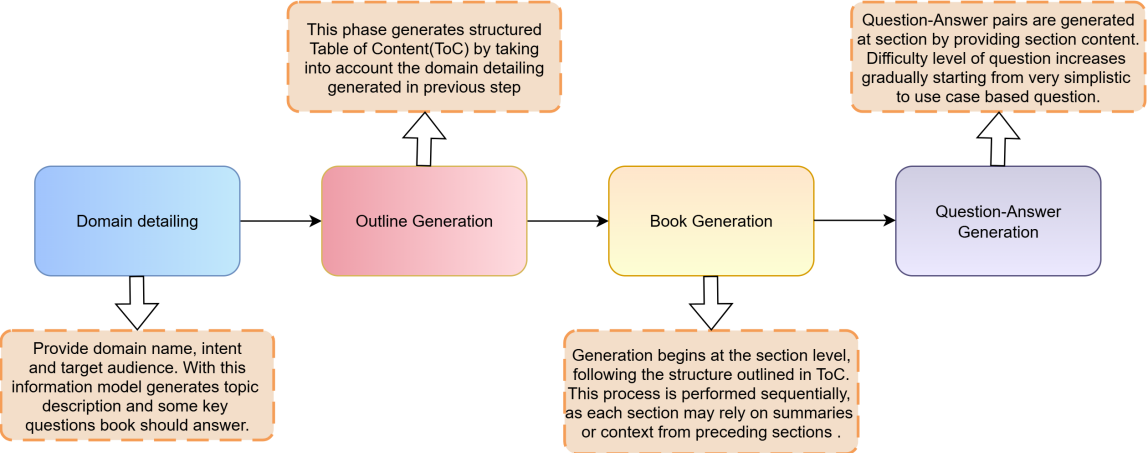
技术框架:ACER主要包含以下几个阶段:1) 课程生成:首先,根据目标领域,自动生成课程目录,类似于教科书的目录。2) 问答对生成:然后,根据布鲁姆分类法,为每个主题生成一系列难度递增的问答对。3) 持续预训练:最后,使用生成的问答对进行持续预训练,并采用交错的课程表,以平衡不同难度级别的内容。
关键创新:ACER的关键创新在于自动化课程生成和基于布鲁姆分类法的难度控制。传统的知识注入方法往往依赖于人工标注的数据,成本高昂且难以扩展。ACER通过自动化生成课程,大大降低了成本,并提高了可扩展性。同时,基于布鲁姆分类法的难度控制,确保了模型能够循序渐进地学习知识,避免了过早接触过于复杂的概念。
关键设计:在课程生成阶段,论文使用了大型语言模型来生成课程目录和问答对。在持续预训练阶段,论文采用了交错的课程表,以平衡不同难度级别的内容。具体的损失函数和网络结构与基础模型(Llama 3.2)保持一致,没有进行额外的修改。
🖼️ 关键图片

📊 实验亮点
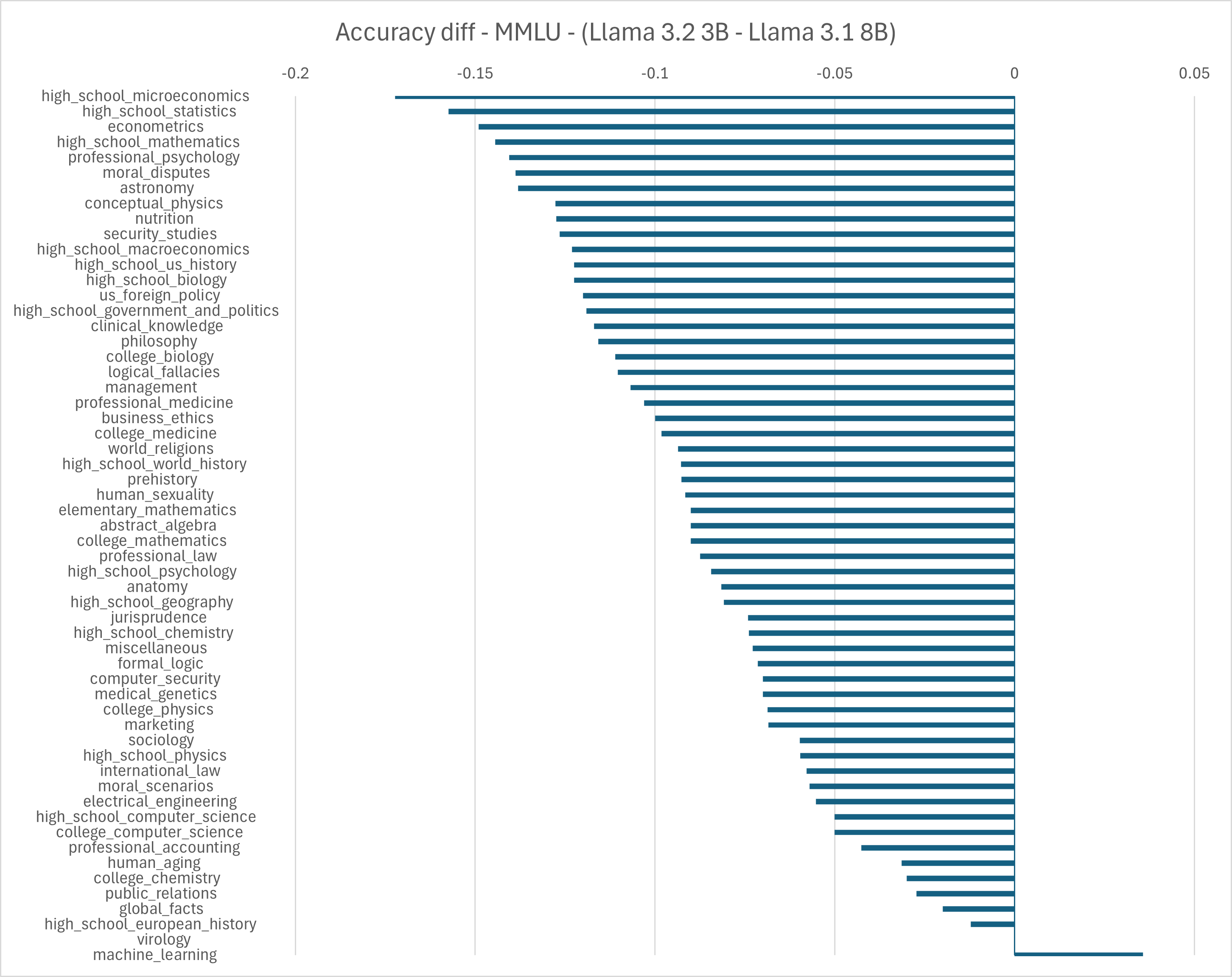
实验结果表明,ACER显著提升了Llama 3.2模型在专业领域的性能。在微观经济学领域,ACER将准确率提高了5个百分点。在所有目标领域中,宏平均一致提高了3个百分点。此外,ACER还提升了模型在ARC和GPQA等知识密集型基准上的性能,提升幅度超过2个百分点,同时保持了通用推理能力。
🎯 应用场景
ACER可应用于各种需要领域专业知识的场景,例如金融分析、医疗诊断、法律咨询等。通过将ACER应用于通用大型语言模型,可以使其具备特定领域的专业能力,从而更好地服务于各行各业。该研究的潜在价值在于降低了领域专家系统的开发成本,并提高了其可扩展性,未来有望推动人工智能在专业领域的广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) excel at general tasks but underperform in specialized domains like economics and psychology, which require deep, principled understanding. To address this, we introduce ACER (Automated Curriculum-Enhanced Regimen) that transforms generalist models into domain experts without sacrificing their broad capabilities. ACER first synthesizes a comprehensive, textbook-style curriculum by generating a table of contents for a subject and then creating question-answer (QA) pairs guided by Bloom's taxonomy. This ensures systematic topic coverage and progressively increasing difficulty. The resulting synthetic corpus is used for continual pretraining with an interleaved curriculum schedule, aligning learning across both content and cognitive dimensions. Experiments with Llama 3.2 (1B and 3B) show significant gains in specialized MMLU subsets. In challenging domains like microeconomics, where baselines struggle, ACER boosts accuracy by 5 percentage points. Across all target domains, we observe a consistent macro-average improvement of 3 percentage points. Notably, ACER not only prevents catastrophic forgetting but also facilitates positive cross-domain knowledge transfer, improving performance on non-target domains by 0.7 points. Beyond MMLU, ACER enhances performance on knowledge-intensive benchmarks like ARC and GPQA by over 2 absolute points, while maintaining stable performance on general reasoning tasks. Our results demonstrate that ACER offers a scalable and effective recipe for closing critical domain gaps in LLMs.