Unravelling the Mechanisms of Manipulating Numbers in Language Models
作者: Michal Štefánik, Timothee Mickus, Marek Kadlčík, Bertram Højer, Michal Spiegel, Raúl Vázquez, Aman Sinha, Josef Kuchař, Philipp Mondorf
分类: cs.CL, cs.AI, cs.LG, cs.NE
发布日期: 2025-10-30
💡 一句话要点
揭示语言模型中数字处理机制,探究其误差根源与精度下限
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 数字处理 可解释性 通用探针 误差分析
📋 核心要点
- 大型语言模型在数字处理上存在精度问题,但其输入嵌入表示却表现出一致性和准确性,这构成了研究的核心矛盾。
- 该研究通过创建通用探针,分析不同LLM在处理数字时的内部机制,揭示了数字表示的可互换性和系统性。
- 实验结果表明,即使存在输出错误,LLM在隐藏状态中对数字的处理依然高度精确,并能追溯错误到特定层。
📝 摘要(中文)
近期研究表明,不同的大型语言模型(LLM)在数字的输入嵌入表示上会收敛到相似且精确的状态。然而,这与LLM在处理数字信息时容易产生错误输出的现象相矛盾。本文旨在通过探索语言模型如何处理数字,并量化这些机制的精度下限来解释这一矛盾。研究发现,尽管存在错误,不同的语言模型学习到的数字表示是可互换的、系统的、高度精确的,并且在隐藏状态和输入上下文类型中是通用的。这使得我们能够为每个LLM创建通用探针,并将信息(包括输出错误的根源)追溯到特定层。我们的结果为预训练LLM如何处理数字奠定了基础,并概述了更精确的探测技术在改进LLM架构方面的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理数字信息时出现的精度问题。尽管LLM在数字的输入嵌入表示上表现出一致性和准确性,但实际输出中却经常出现错误。现有的方法未能充分解释这种矛盾现象,也缺乏对LLM内部数字处理机制的深入理解。
核心思路:论文的核心思路是通过创建通用探针,深入分析不同LLM在处理数字时的内部机制,从而揭示数字表示的可互换性、系统性和精确性。通过追踪信息流,可以将输出错误追溯到特定的网络层,从而更好地理解误差的根源。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 分析不同LLM对数字的输入嵌入表示;2) 创建通用探针,用于提取LLM隐藏状态中的数字信息;3) 分析LLM在不同层对数字的处理过程,追踪信息流;4) 定位导致输出错误的特定网络层;5) 量化LLM数字处理机制的精度下限。
关键创新:该研究的关键创新在于:1) 提出了利用通用探针分析LLM数字处理机制的方法,能够深入理解LLM内部的数字表示和计算过程;2) 揭示了不同LLM在数字处理上的共性,即数字表示的可互换性、系统性和精确性;3) 能够将输出错误追溯到特定的网络层,为改进LLM的数字处理能力提供了新的思路。
关键设计:论文的关键设计包括:1) 通用探针的设计,需要能够有效地提取LLM隐藏状态中的数字信息,并具有一定的泛化能力;2) 信息流追踪方法,需要能够准确地追踪数字信息在LLM中的传递过程,并定位导致错误的特定网络层;3) 精度量化方法,需要能够客观地评估LLM数字处理机制的精度下限。
🖼️ 关键图片
📊 实验亮点
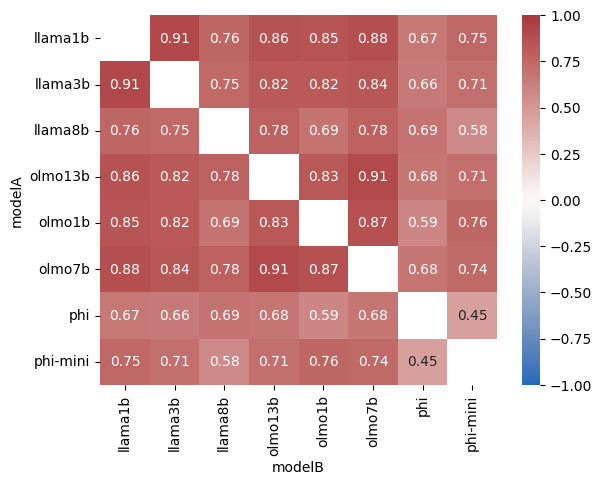
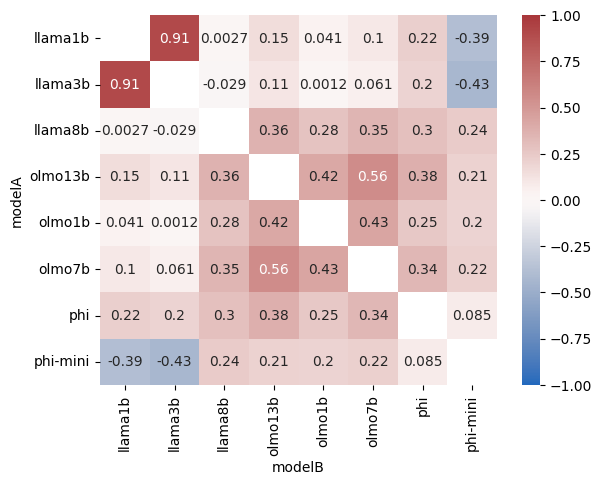
研究发现,尽管LLM输出可能存在错误,但其内部对数字的表示是高度精确和通用的。通过通用探针,研究者能够将输出错误追溯到特定的网络层,从而揭示了误差产生的具体位置。这一发现为改进LLM的数字处理能力提供了关键线索。
🎯 应用场景
该研究成果可应用于提升大型语言模型在金融、科学计算等领域的数字处理能力,减少计算错误,提高模型可靠性。通过理解LLM内部的数字处理机制,可以设计更高效、更精确的LLM架构,并为LLM的安全性评估提供参考。
📄 摘要(原文)
Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.