Do LLMs Signal When They're Right? Evidence from Neuron Agreement
作者: Kang Chen, Yaoning Wang, Kai Xiong, Zhuoka Feng, Wenhe Sun, Haotian Chen, Yixin Cao
分类: cs.CL
发布日期: 2025-10-30
💡 一句话要点
提出神经元一致性解码(NAD),利用LLM内部神经元信号提升无标签集成解码效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 集成解码 神经元激活 无监督学习 早期停止
📋 核心要点
- 现有LLM集成解码方法依赖外部信号评估候选答案,但这些信号校准性差,限制了性能。
- 论文提出神经元一致性解码(NAD),利用神经元激活的稀疏性和跨样本一致性来选择最佳候选答案。
- 实验表明,NAD在数学、科学和编码基准测试中表现出色,并能显著减少token使用量。
📝 摘要(中文)
大型语言模型(LLM)通常通过采样-评估-集成解码器来增强推理能力,在没有ground truth的情况下实现无标签增益。然而,目前主流策略仅使用token概率、熵或自评估等外部输出来评估候选答案,这些信号在后训练后可能校准不良。本文分析了基于神经元激活的内部行为,发现了三个结论:(1)外部信号是更丰富的内部动态的低维投影;(2)正确的响应比错误的响应激活的独特神经元数量明显更少;(3)来自正确响应的激活表现出更强的跨样本一致性,而错误的响应则发散。受这些观察的启发,本文提出神经元一致性解码(NAD),这是一种无监督的best-of-N方法,它仅使用内部信号,无需可比较的文本输出,通过激活稀疏性和跨样本神经元一致性来选择候选答案。NAD能够在生成的前32个token内进行早期正确性预测,并支持激进的提前停止。在具有可验证答案的数学和科学基准测试中,NAD与多数投票相匹配;在多数投票不适用的开放式编码基准测试中,NAD始终优于Avg@64。通过尽早修剪没有希望的轨迹,NAD将token使用量减少了99%,同时生成质量的损失最小,表明内部信号为无标签集成解码提供了可靠、可扩展和高效的指导。
🔬 方法详解
问题定义:现有的大型语言模型在进行集成解码时,通常依赖于外部信号(如token概率、熵、自评估等)来评估候选答案的质量。然而,这些外部信号在经过后训练后,往往校准不良,导致选择的答案不准确。此外,对于开放式任务(如代码生成),多数投票等集成方法难以应用,需要更有效的无监督选择策略。
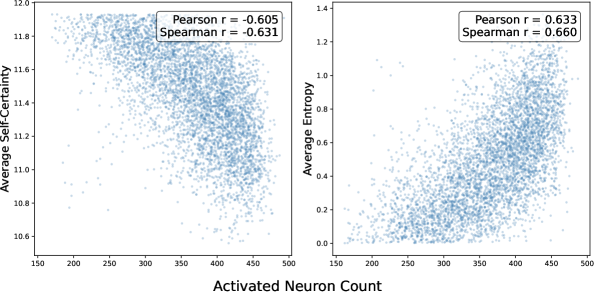
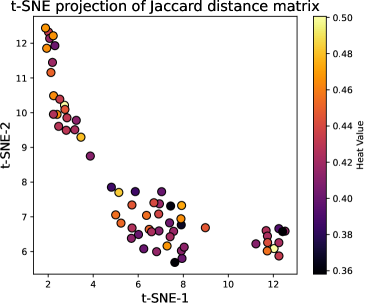
核心思路:论文的核心思路是利用LLM内部的神经元激活信息来判断答案的正确性。作者发现,正确的答案通常激活更少的神经元,并且不同样本之间的神经元激活模式更加一致。因此,可以通过神经元激活的稀疏性和一致性来选择最佳候选答案,而无需依赖外部信号。
技术框架:NAD (Neuron Agreement Decoding) 的整体框架如下:1. 采样:从LLM中采样N个候选答案。2. 神经元激活提取:提取每个候选答案生成过程中每一层神经元的激活值。3. 激活稀疏性评估:计算每个候选答案激活的神经元数量,作为稀疏性指标。4. 跨样本神经元一致性评估:计算不同候选答案之间神经元激活模式的相似度,作为一致性指标。5. 候选答案选择:综合考虑激活稀疏性和一致性,选择得分最高的候选答案。6. 早期停止:根据NAD的得分,可以提前停止生成过程,减少计算量。
关键创新:NAD最重要的技术创新在于,它完全依赖于LLM内部的神经元激活信息来进行候选答案的选择,而无需任何外部信号或标签。这使得NAD能够应用于各种任务,包括开放式任务,并且具有更好的鲁棒性。此外,NAD还能够进行早期正确性预测,从而实现激进的提前停止,显著减少计算量。
关键设计:NAD的关键设计包括:1. 激活稀疏性度量:可以使用激活神经元的数量或激活值的L1范数来衡量稀疏性。2. 跨样本神经元一致性度量:可以使用余弦相似度或互信息等方法来衡量不同样本之间神经元激活模式的相似度。3. 早期停止策略:可以设置一个阈值,当NAD的得分超过该阈值时,就提前停止生成过程。论文中使用了前32个token的神经元激活信息进行早期预测。
🖼️ 关键图片
📊 实验亮点
实验结果表明,NAD在数学和科学基准测试中与多数投票的性能相当,但在开放式编码基准测试中,NAD始终优于Avg@64。更重要的是,NAD能够通过早期停止策略,将token使用量减少99%,同时生成质量的损失最小。这表明NAD能够以极低的计算成本,实现高效的集成解码。
🎯 应用场景
该研究成果可应用于各种需要集成解码的LLM应用场景,例如数学问题求解、科学推理、代码生成等。通过利用内部神经元信号,可以提高答案的准确性和效率,尤其是在缺乏外部监督信号或计算资源受限的情况下,具有重要的应用价值。未来,该方法可以进一步扩展到其他类型的模型和任务中。
📄 摘要(原文)
Large language models (LLMs) commonly boost reasoning via sample-evaluate-ensemble decoders, achieving label free gains without ground truth. However, prevailing strategies score candidates using only external outputs such as token probabilities, entropies, or self evaluations, and these signals can be poorly calibrated after post training. We instead analyze internal behavior based on neuron activations and uncover three findings: (1) external signals are low dimensional projections of richer internal dynamics; (2) correct responses activate substantially fewer unique neurons than incorrect ones throughout generation; and (3) activations from correct responses exhibit stronger cross sample agreement, whereas incorrect ones diverge. Motivated by these observations, we propose Neuron Agreement Decoding (NAD), an unsupervised best-of-N method that selects candidates using activation sparsity and cross sample neuron agreement, operating solely on internal signals and without requiring comparable textual outputs. NAD enables early correctness prediction within the first 32 generated tokens and supports aggressive early stopping. Across math and science benchmarks with verifiable answers, NAD matches majority voting; on open ended coding benchmarks where majority voting is inapplicable, NAD consistently outperforms Avg@64. By pruning unpromising trajectories early, NAD reduces token usage by 99% with minimal loss in generation quality, showing that internal signals provide reliable, scalable, and efficient guidance for label free ensemble decoding.