Language Models Are Borrowing-Blind: A Multilingual Evaluation of Loanword Identification across 10 Languages
作者: Mérilin Sousa Silva, Sina Ahmadi
分类: cs.CL
发布日期: 2025-10-30
备注: Under review
💡 一句话要点
大型语言模型在跨语种外来语识别任务中表现不佳,揭示其“借用盲区”问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 外来语识别 语言模型 多语言评估 少数民族语言 自然语言处理
📋 核心要点
- 现有NLP系统在外来语识别方面存在偏差,倾向于使用外来语而非本土词汇,对少数民族语言造成威胁。
- 该研究通过多语言评估,考察预训练语言模型是否具备区分外来语和本土词汇的能力,揭示模型的“借用盲区”。
- 实验结果表明,即使提供明确指令和上下文信息,模型在外来语识别方面表现不佳,证实了现有NLP系统的偏差。
📝 摘要(中文)
本文研究了预训练语言模型(包括大型语言模型)是否具备识别外来语的能力。外来语是指从一种语言借用到另一种语言,并逐渐融入接收语言词汇中的词语。说话者通常能够区分外来语和本土词汇,尤其是在双语社区,强势语言不断将词汇强加于弱势语言。本文在10种语言上评估了多个模型。结果表明,尽管有明确的指令和上下文信息,模型在区分外来语和本土词汇方面表现不佳。这些发现证实了之前的证据,即现代自然语言处理系统对外来语而非本土词汇表现出偏差。这项工作对开发用于少数民族语言的自然语言处理工具以及支持在受强势语言词汇压力下的社区中进行语言保护具有重要意义。
🔬 方法详解
问题定义:论文旨在评估预训练语言模型在区分外来语和本土词汇方面的能力。现有方法,特别是大型语言模型,在处理少数民族语言时,倾向于使用外来语而非本土词汇,这可能加速少数民族语言的衰退。因此,准确识别外来语对于开发更好的少数民族语言NLP工具至关重要。
核心思路:论文的核心思路是通过设计一个多语言的外来语识别任务,来考察预训练语言模型是否能够像人类一样区分外来语和本土词汇。如果模型能够有效识别外来语,则表明其具备一定的语言文化意识,可以更好地应用于少数民族语言处理。反之,则需要进一步研究如何消除模型对外来语的偏见。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择10种语言作为评估对象;2) 构建包含外来语和本土词汇的数据集,并为每个词汇提供上下文信息;3) 选择多个预训练语言模型(包括大型语言模型)进行评估;4) 设计评估指标,衡量模型区分外来语和本土词汇的准确率;5) 分析实验结果,探讨模型在外来语识别方面的优势和不足。
关键创新:该研究的关键创新在于:1) 首次系统性地评估了预训练语言模型在外来语识别方面的能力,揭示了模型存在的“借用盲区”问题;2) 构建了一个多语言的外来语识别数据集,为后续研究提供了benchmark;3) 提出了针对少数民族语言NLP工具开发的建议,强调了消除模型对外来语偏见的重要性。
关键设计:论文的关键设计包括:1) 选择了10种不同语系的语言,以保证评估的泛化性;2) 在数据集中,为每个词汇提供了上下文信息,以模拟真实的语言使用场景;3) 使用了多种预训练语言模型,包括不同规模和架构的模型,以考察模型规模和架构对外来语识别能力的影响;4) 使用了准确率作为评估指标,简单直观地衡量模型区分外来语和本土词汇的能力。
🖼️ 关键图片
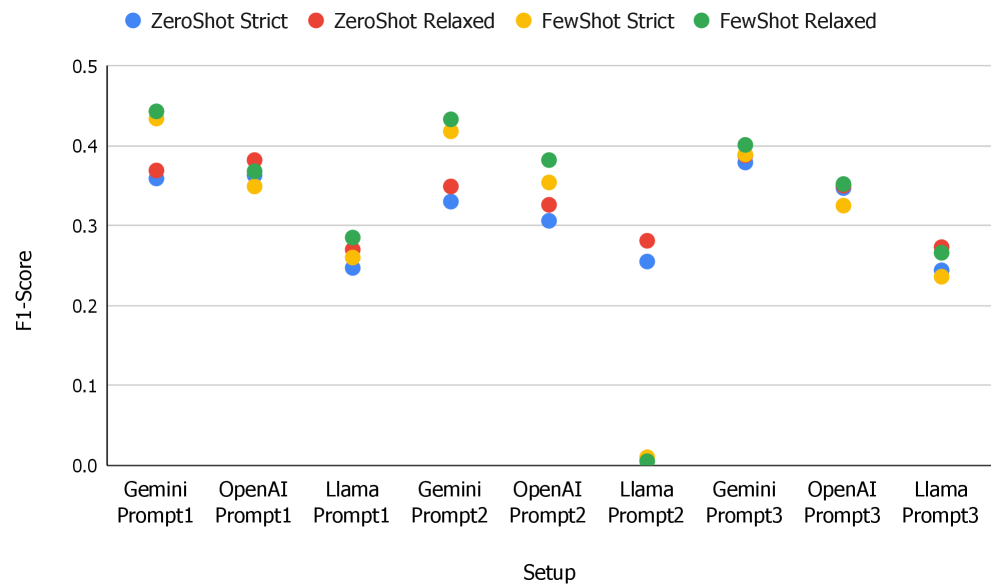
📊 实验亮点
实验结果表明,即使提供明确的指令和上下文信息,预训练语言模型在区分外来语和本土词汇方面表现不佳。这证实了现代NLP系统对外来语而非本土词汇存在偏差。具体性能数据未知,但整体表现显著低于人类水平,表明模型在语言文化理解方面存在明显不足。
🎯 应用场景
该研究成果可应用于开发更精准的少数民族语言NLP工具,例如机器翻译、语音识别等,从而更好地支持少数民族语言的保护和传承。此外,该研究也提醒研究人员在构建和训练语言模型时,需要关注模型可能存在的文化偏见,避免加剧语言不平等现象。
📄 摘要(原文)
Throughout language history, words are borrowed from one language to another and gradually become integrated into the recipient's lexicon. Speakers can often differentiate these loanwords from native vocabulary, particularly in bilingual communities where a dominant language continuously imposes lexical items on a minority language. This paper investigates whether pretrained language models, including large language models, possess similar capabilities for loanword identification. We evaluate multiple models across 10 languages. Despite explicit instructions and contextual information, our results show that models perform poorly in distinguishing loanwords from native ones. These findings corroborate previous evidence that modern NLP systems exhibit a bias toward loanwords rather than native equivalents. Our work has implications for developing NLP tools for minority languages and supporting language preservation in communities under lexical pressure from dominant languages.