Towards Global Retrieval Augmented Generation: A Benchmark for Corpus-Level Reasoning
作者: Qi Luo, Xiaonan Li, Tingshuo Fan, Xinchi Chen, Xipeng Qiu
分类: cs.CL, cs.AI
发布日期: 2025-10-30 (更新: 2025-11-04)
💡 一句话要点
提出GlobalRAG框架,解决现有RAG方法在语料库级别推理任务中的不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 语料库级别推理 全局推理 多工具协作
📋 核心要点
- 现有RAG方法侧重于局部信息检索,难以处理需要跨文档集合进行推理的全局任务。
- GlobalRAG通过多工具协作,结合块级检索、LLM智能过滤和聚合模块,实现语料库级别的推理。
- 实验表明,GlobalRAG在GlobalQA基准测试中显著优于现有RAG方法,F1值提升明显。
📝 摘要(中文)
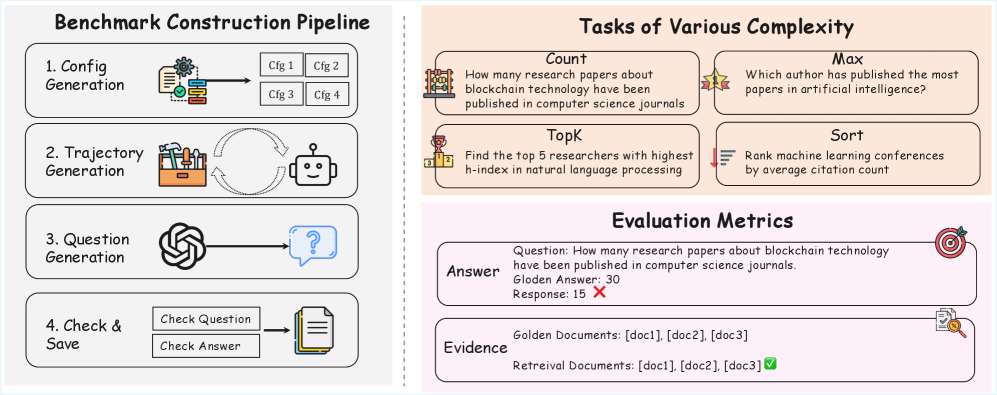
检索增强生成(RAG)已成为减少大型语言模型(LLM)幻觉的主要方法。目前的RAG评估基准主要集中于局部RAG:从一小部分文档中检索相关块,以回答仅需要特定文本块内局部理解的查询。然而,许多实际应用需要一种根本不同的能力——全局RAG——它涉及聚合和分析整个文档集合中的信息,以获得语料库级别的见解(例如,“2023年被引用次数最多的前10篇论文是什么?”)。在本文中,我们介绍了GlobalQA——第一个专门用于评估全局RAG能力的基准,涵盖四种核心任务类型:计数、极值查询、排序和top-k提取。通过对不同模型和基线的系统评估,我们发现现有的RAG方法在全局任务上的表现很差,最强的基线仅达到1.51的F1分数。为了应对这些挑战,我们提出了GlobalRAG,一个多工具协作框架,它通过块级检索保持结构连贯性,结合LLM驱动的智能过滤器来消除噪声文档,并集成聚合模块来进行精确的符号计算。在Qwen2.5-14B模型上,GlobalRAG实现了6.63的F1,而最强基线的F1为1.51,验证了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决现有检索增强生成(RAG)方法在处理需要语料库级别推理任务时的不足。现有RAG方法主要关注局部信息检索,即从少量文档中检索相关片段来回答问题,无法有效处理需要聚合和分析整个文档集合信息的全局性问题。现有方法在处理计数、极值查询、排序和top-k提取等任务时表现不佳,主要痛点在于无法有效整合分散在不同文档中的信息,且容易受到噪声文档的干扰。
核心思路:GlobalRAG的核心思路是构建一个多工具协作框架,该框架能够有效地从整个文档集合中检索相关信息,并通过LLM驱动的智能过滤器消除噪声文档,最终利用聚合模块进行精确的符号计算。这种设计旨在克服现有RAG方法在处理全局任务时的局限性,提高模型在语料库级别推理任务中的性能。
技术框架:GlobalRAG框架包含以下主要模块:1) 块级检索模块:用于从整个文档集合中检索相关的文本块,保持结构连贯性。2) LLM驱动的智能过滤器:利用大型语言模型对检索到的文档进行过滤,消除噪声文档,提高信息质量。3) 聚合模块:用于对过滤后的信息进行聚合和分析,进行精确的符号计算,例如计数、排序等。整个流程首先通过块级检索获取候选文档,然后利用LLM进行过滤,最后通过聚合模块得到最终答案。
关键创新:GlobalRAG的关键创新在于其多工具协作的框架设计,以及LLM驱动的智能过滤器的应用。与现有RAG方法相比,GlobalRAG不仅关注局部信息检索,更注重信息的聚合和分析,能够有效处理需要语料库级别推理的任务。LLM驱动的智能过滤器能够有效消除噪声文档,提高信息质量,从而提高模型的准确性。
关键设计:GlobalRAG框架中,LLM驱动的智能过滤器是关键设计之一。该过滤器利用大型语言模型对检索到的文档进行评估,判断其与问题的相关性,并根据评估结果进行过滤。具体的实现细节包括选择合适的LLM模型、设计合适的提示语(prompt)以及设定合理的过滤阈值。此外,聚合模块的设计也至关重要,需要根据不同的任务类型选择合适的聚合算法,例如计数任务可以使用计数器,排序任务可以使用排序算法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GlobalRAG在GlobalQA基准测试中显著优于现有RAG方法。在Qwen2.5-14B模型上,GlobalRAG实现了6.63的F1分数,而最强基线的F1分数为1.51,提升幅度超过300%。这一结果验证了GlobalRAG框架的有效性,表明其能够有效处理需要语料库级别推理的任务。
🎯 应用场景
GlobalRAG在知识密集型任务中具有广泛的应用前景,例如科研文献分析、市场情报分析、法律文件检索等。它可以帮助用户快速从大量文档中提取关键信息,进行深度分析和推理,从而提高工作效率和决策质量。未来,GlobalRAG可以进一步扩展到其他领域,例如金融分析、医疗诊断等,为各行各业提供更智能化的信息服务。
📄 摘要(原文)
Retrieval-augmented generation (RAG) has emerged as a leading approach to reducing hallucinations in large language models (LLMs). Current RAG evaluation benchmarks primarily focus on what we call local RAG: retrieving relevant chunks from a small subset of documents to answer queries that require only localized understanding within specific text chunks. However, many real-world applications require a fundamentally different capability -- global RAG -- which involves aggregating and analyzing information across entire document collections to derive corpus-level insights (for example, "What are the top 10 most cited papers in 2023?"). In this paper, we introduce GlobalQA -- the first benchmark specifically designed to evaluate global RAG capabilities, covering four core task types: counting, extremum queries, sorting, and top-k extraction. Through systematic evaluation across different models and baselines, we find that existing RAG methods perform poorly on global tasks, with the strongest baseline achieving only 1.51 F1 score. To address these challenges, we propose GlobalRAG, a multi-tool collaborative framework that preserves structural coherence through chunk-level retrieval, incorporates LLM-driven intelligent filters to eliminate noisy documents, and integrates aggregation modules for precise symbolic computation. On the Qwen2.5-14B model, GlobalRAG achieves 6.63 F1 compared to the strongest baseline's 1.51 F1, validating the effectiveness of our method.