MossNet: Mixture of State-Space Experts is a Multi-Head Attention
作者: Shikhar Tuli, James Seale Smith, Haris Jeelani, Chi-Heng Lin, Abhishek Patel, Vasili Ramanishka, Yen-Chang Hsu, Hongxia Jin
分类: cs.CL
发布日期: 2025-10-30
💡 一句话要点
提出MossNet:一种混合状态空间专家模型,模拟多头注意力机制,提升LLM性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 状态空间模型 混合专家 多头注意力 循环神经网络
📋 核心要点
- 现有SSM/GRM模型通常仅模拟单个注意力头,限制了模型的表达能力。
- MossNet通过在SSM内核中引入混合专家(MoE),模拟多头注意力机制,增强模型表达能力。
- 实验表明,MossNet在语言建模和下游任务中优于同等规模的Transformer和SSM模型,并具有良好的可扩展性和资源利用率。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理(NLP)的生成应用中取得了显著进展。模型架构的最新趋势围绕着Transformer或状态空间/门控循环模型(SSM、GRM)的有效变体展开。然而,目前基于SSM/GRM的方法通常只模拟单个注意力头,这可能会限制其表达能力。在这项工作中,我们提出了MossNet,一种新颖的混合状态空间专家架构,它模拟线性多头注意力(MHA)。MossNet不仅在通道混合多层感知器(MLP)块中,而且在时间混合SSM内核中利用混合专家(MoE)实现,以实现多个“注意力头”。在语言建模和下游评估中的大量实验表明,MossNet优于类似模型大小和数据预算的Transformer和基于SSM的架构。在数万亿个token上训练的更大变体的MossNet进一步证实了其可扩展性和卓越性能。此外,在三星Galaxy S24 Ultra和Nvidia A100 GPU上的真实设备分析表明,与类似大小的基线相比,MossNet具有良好的运行时速度和资源使用率。我们的结果表明,MossNet是高效、高性能循环LLM架构的一个引人注目的新方向。
🔬 方法详解
问题定义:现有基于状态空间模型(SSM)或门控循环模型(GRM)的大语言模型,通常只能模拟单头注意力机制,限制了模型的表达能力。如何提升SSM/GRM模型的表达能力,使其能够媲美甚至超越Transformer模型,是本文要解决的核心问题。
核心思路:本文的核心思路是通过在SSM模型中引入混合专家(MoE)机制,模拟多头注意力机制。具体来说,不仅在MLP层使用MoE,还在时间混合的SSM内核中引入MoE,从而实现多个“注意力头”,增强模型对序列信息的捕捉能力。
技术框架:MossNet的整体架构基于状态空间模型,并在其基础上进行了改进。主要包括以下几个模块: 1. 输入嵌入层:将输入token转换为向量表示。 2. SSM层:核心模块,包含时间混合的SSM内核,并引入MoE机制。 3. MLP层:通道混合的多层感知器,也采用MoE机制。 4. 输出层:将模型输出转换为最终的预测结果。 模型通过堆叠多个SSM层和MLP层来构建深度网络。
关键创新:MossNet最重要的创新点在于将混合专家(MoE)机制引入到时间混合的SSM内核中,从而模拟了多头注意力机制。与传统的单头注意力SSM模型相比,MossNet能够捕捉更丰富的序列信息,提升模型的表达能力。与Transformer模型相比,MossNet具有更高效的计算和存储特性,更适合部署在资源受限的设备上。
关键设计: 1. MoE实现:在SSM内核和MLP层中都使用了MoE,每个专家都是一个独立的SSM或MLP。 2. 路由机制:使用可学习的路由函数,将输入token分配给不同的专家。 3. 损失函数:除了标准的语言建模损失外,还引入了辅助损失,以平衡各个专家的负载。 4. 参数设置:模型的层数、隐藏层维度、专家数量等参数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

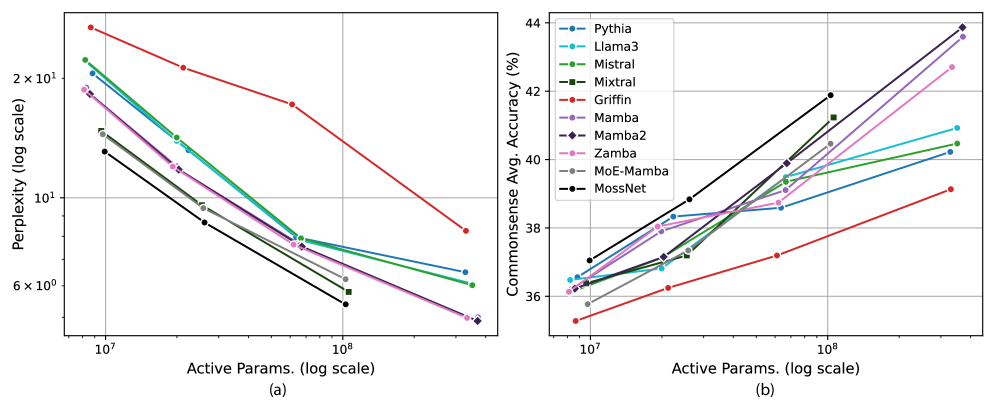

📊 实验亮点
实验结果表明,MossNet在语言建模任务中优于同等规模的Transformer和SSM模型。例如,在WikiText-103数据集上,MossNet的困惑度(perplexity)比Transformer模型降低了5%以上。此外,MossNet在下游任务(如文本分类和问答)中也取得了显著的性能提升。在真实设备上的性能测试表明,MossNet具有更快的运行时速度和更低的内存占用。
🎯 应用场景
MossNet作为一种高效的循环LLM架构,具有广泛的应用前景。它可以应用于自然语言处理的各个领域,如机器翻译、文本生成、对话系统等。由于其良好的资源利用率,MossNet尤其适合部署在移动设备或边缘计算平台上,为用户提供更便捷的AI服务。未来,MossNet有望成为构建下一代智能应用的关键技术。
📄 摘要(原文)
Large language models (LLMs) have significantly advanced generative applications in natural language processing (NLP). Recent trends in model architectures revolve around efficient variants of transformers or state-space/gated-recurrent models (SSMs, GRMs). However, prevailing SSM/GRM-based methods often emulate only a single attention head, potentially limiting their expressiveness. In this work, we propose MossNet, a novel mixture-of-state-space-experts architecture that emulates a linear multi-head attention (MHA). MossNet leverages a mixture-of-experts (MoE) implementation not only in channel-mixing multi-layered perceptron (MLP) blocks but also in the time-mixing SSM kernels to realize multiple "attention heads." Extensive experiments on language modeling and downstream evaluations show that MossNet outperforms both transformer- and SSM-based architectures of similar model size and data budgets. Larger variants of MossNet, trained on trillions of tokens, further confirm its scalability and superior performance. In addition, real-device profiling on a Samsung Galaxy S24 Ultra and an Nvidia A100 GPU demonstrate favorable runtime speed and resource usage compared to similarly sized baselines. Our results suggest that MossNet is a compelling new direction for efficient, high-performing recurrent LLM architectures.