Reasoning Path Divergence: A New Metric and Curation Strategy to Unlock LLM Diverse Thinking
作者: Feng Ju, Zeyu Qin, Rui Min, Zhitao He, Lingpeng Kong, Yi R. Fung
分类: cs.CL
发布日期: 2025-10-30 (更新: 2026-01-04)
🔗 代码/项目: GITHUB
💡 一句话要点
提出推理路径差异度量与数据筛选策略,提升LLM推理多样性与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 多样性 推理路径差异 一题多解 数据筛选 微调
📋 核心要点
- 现有LLM训练通常采用“一题一解”模式,导致模型推理路径单一,限制了模型输出的多样性,阻碍了采样效率和后续强化学习的探索空间。
- 论文提出“一题多解”训练范式,通过让模型接触多样化的推理轨迹来提升推理多样性,并设计了推理路径差异(RPD)度量指标来衡量推理链之间的语义差异。
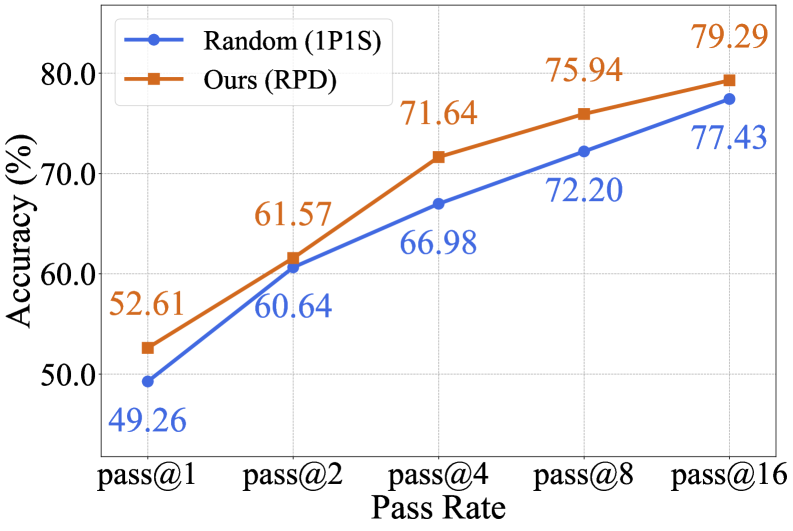
- 实验表明,使用RPD筛选的数据进行训练,能够显著提升模型输出的多样性,并在pass@k指标上取得显著提升,验证了所提方法的有效性。
📝 摘要(中文)
本文针对大规模语言模型(LLM)推理能力提升中模型输出多样性不足的问题,指出“一题一解”(1P1S)的训练方式限制了模型的推理路径探索。为此,提出了“一题多解”(1PNS)的训练范式,旨在让模型接触到更多样化的有效推理轨迹,从而增加推理多样性。论文核心在于引入了推理路径差异(RPD)这一步级度量指标,用于对长链式推理过程进行对齐和评分,以捕捉中间推理步骤的差异。利用RPD,可以为每个问题筛选出最大程度不同的解集,并对Qwen3-4B-Base进行微调。实验结果表明,使用RPD选择的训练数据能够产生更多样化的输出,并提高pass@k指标,相较于强大的1P1S基线,pass@16平均提升了2.80%,在AIME24上提升了4.99%,证明了1PNS进一步增强了TTS的有效性。
🔬 方法详解
问题定义:现有的大语言模型在解决推理问题时,往往被训练成“一题一解”的模式,即对于一个问题,模型倾向于生成唯一的、标准的答案。这种训练方式虽然能够保证模型在某些特定问题上的准确率,但同时也限制了模型探索更多样化、更具创造性的解题思路。这种推理路径的单一性,不仅降低了模型输出的多样性,也限制了模型在面对复杂问题时的泛化能力,尤其是在需要进行多次迭代和探索的强化学习场景中,模型的探索空间受到了极大的限制。
核心思路:论文的核心思路是打破“一题一解”的训练模式,转而采用“一题多解”的训练范式。具体来说,就是让模型在训练过程中接触到同一个问题的多种不同的解题思路和推理路径。通过这种方式,模型可以学习到更加丰富的知识和推理模式,从而在推理过程中能够生成更多样化的输出。这种思路的设计基于一个假设:即问题的解法往往不是唯一的,通过探索不同的解法,模型可以更好地理解问题的本质,并提高解决问题的能力。
技术框架:整体框架主要包含两个阶段:首先,利用提出的推理路径差异(RPD)指标,从已有的数据集中筛选出对于每个问题具有最大差异性的多个解法。其次,使用筛选出的数据对预训练模型进行微调,使其能够学习到更多样化的推理路径。RPD指标用于衡量不同推理路径之间的语义差异,其核心思想是对推理链中的每一步进行对齐和比较,从而捕捉到中间推理步骤的差异。微调阶段则采用标准的监督学习方法,通过最小化模型预测结果与真实答案之间的差异来优化模型参数。
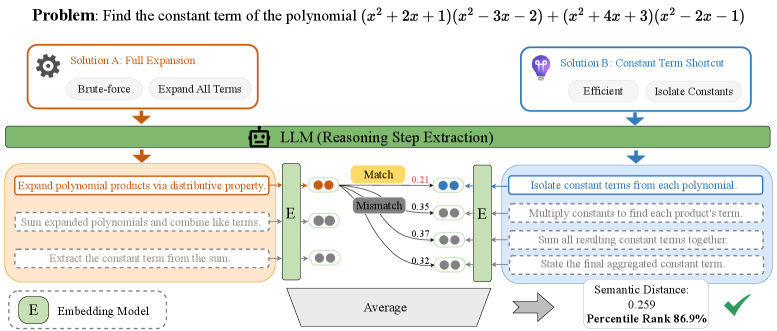
关键创新:论文最重要的技术创新点在于提出了推理路径差异(RPD)这一度量指标。RPD不同于传统的基于答案相似度的度量方法,它能够更加细粒度地衡量不同推理路径之间的语义差异。具体来说,RPD通过对推理链中的每一步进行对齐和比较,从而捕捉到中间推理步骤的差异。这种细粒度的度量方式使得RPD能够更加准确地评估不同推理路径的多样性,从而为“一题多解”的训练范式提供了有效的支持。与现有方法相比,RPD的本质区别在于它关注的是推理过程的差异,而不是仅仅关注最终答案的相似度。
关键设计:RPD的关键设计在于其步级对齐和差异评分机制。具体来说,对于两条推理路径,首先需要将它们进行对齐,即找到两条路径中语义最相似的步骤。然后,对于每一对对齐的步骤,计算它们之间的语义差异得分。最终,将所有对齐步骤的差异得分进行加权平均,得到两条推理路径之间的RPD值。RPD值的计算可以使用各种语义相似度度量方法,例如余弦相似度、编辑距离等。此外,RPD还可以根据不同的任务和数据集进行调整,例如可以对不同的步骤赋予不同的权重,或者使用不同的语义相似度度量方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用RPD筛选的数据进行训练,能够显著提升模型输出的多样性,并在pass@k指标上取得显著提升。具体来说,相较于强大的1P1S基线,pass@16平均提升了2.80%,在AIME24数据集上提升了4.99%。这些结果充分验证了所提出的“一题多解”训练范式和RPD度量指标的有效性。
🎯 应用场景
该研究成果可应用于提升大语言模型在各种推理任务中的表现,例如数学问题求解、逻辑推理、常识推理等。通过提高模型输出的多样性,可以增强模型在复杂场景下的泛化能力和鲁棒性。此外,该方法还可以用于生成更具创造性的文本内容,例如故事创作、诗歌生成等。未来,该研究有望推动大语言模型在更多领域的应用,例如智能客服、教育辅导、科研助手等。
📄 摘要(原文)
While Test-Time Scaling (TTS) has proven effective in improving the reasoning ability of large language models (LLMs), low diversity in model outputs often becomes a bottleneck; this is partly caused by the common "one problem, one solution" (1P1S) training practice, which provides a single canonical answer and can push models toward a narrow set of reasoning paths. This homogenization not only limits sampling effectiveness but also restricts the exploration space for subsequent Reinforcement Learning (RL) stages. To address this, we propose a "one problem, multiple solutions" (1PNS) training paradigm that exposes the model to a variety of valid reasoning trajectories and thus increases inference diversity. A core challenge for 1PNS is reliably measuring semantic differences between multi-step chains of thought, so we introduce Reasoning Path Divergence (RPD), a step-level metric that aligns and scores Long Chain-of-Thought solutions to capture differences in intermediate reasoning. Using RPD, we curate maximally diverse solution sets per problem and fine-tune Qwen3-4B-Base. Experiments show that RPD-selected training yields more varied outputs and higher pass@k, with an average +2.80% gain in pass@16 over a strong 1P1S baseline and a +4.99% gain on AIME24, demonstrating that 1PNS further amplifies the effectiveness of TTS. Our code is available at https://github.com/fengjujf/Reasoning-Path-Divergence .