Diverse Preference Learning for Capabilities and Alignment
作者: Stewart Slocum, Asher Parker-Sartori, Dylan Hadfield-Menell
分类: cs.CL
发布日期: 2025-10-29
期刊: 13th International Conference on Learning Representations (ICLR 2025)
💡 一句话要点
提出软偏好学习(Soft Preference Learning)以提升LLM能力、对齐性和输出多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 偏好学习 对齐 多样性 KL散度 熵 交叉熵
📋 核心要点
- 现有对齐算法如RLHF和DPO降低了LLM输出的多样性,导致模型过度依赖多数意见。
- 论文提出软偏好学习,解耦KL散度中的熵和交叉熵项,实现对LLM生成多样性的精细控制。
- 实验表明,软偏好学习提升了LLM在重复采样任务中的准确性,并增强了输出的语义和词汇多样性。
📝 摘要(中文)
大型语言模型(LLM)代表不同视角的的能力至关重要,因为它们对社会的影响日益增加。然而,最近的研究表明,诸如RLHF和DPO等对齐算法显著降低了LLM输出的多样性。对齐后的LLM不仅生成具有重复结构和词汇选择的文本,而且以更统一的方式处理问题,并且其响应反映了更窄范围的社会视角。我们将此问题归因于偏好学习算法中使用的KL散度正则化项。这导致模型系统性地过度加权多数意见,并牺牲其输出的多样性。为了解决这个问题,我们提出了软偏好学习,它解耦了KL惩罚中的熵和交叉熵项,从而可以对LLM生成多样性进行细粒度控制。从能力的角度来看,使用软偏好学习训练的LLM在困难的重复采样任务中获得了更高的准确性,并产生了具有更大语义和词汇多样性的输出。从对齐的角度来看,它们能够代表更广泛的社会观点,并显示出改进的logit校准。值得注意的是,软偏好学习类似于标准温度缩放,但优于标准温度缩放。
🔬 方法详解
问题定义:现有基于偏好学习的对齐方法,如RLHF和DPO,过度依赖KL散度正则化,导致LLM输出多样性降低,模型倾向于生成重复性高、观点单一的文本。这限制了LLM在需要表达不同观点或解决复杂问题时的能力。现有方法无法有效平衡对齐目标和输出多样性,牺牲了模型表达不同社会视角的潜力。
核心思路:论文的核心思路是通过解耦KL散度中的熵和交叉熵项,实现对LLM生成多样性的细粒度控制。具体来说,通过分别调整熵和交叉熵的权重,可以控制模型在学习偏好的同时,保持输出的多样性,避免过度拟合多数意见。这种方法允许模型在对齐目标和多样性之间取得更好的平衡。
技术框架:软偏好学习(Soft Preference Learning)的整体框架与标准的偏好学习方法类似,但关键在于修改了损失函数。标准的偏好学习通常使用KL散度作为正则化项,限制模型偏离原始模型过远。而软偏好学习将KL散度分解为交叉熵和熵两部分,并分别赋予不同的权重。这样,模型可以更加灵活地调整生成策略,在学习偏好的同时,保持输出的多样性。
关键创新:最重要的技术创新点在于解耦KL散度,并分别控制熵和交叉熵项。与现有方法相比,软偏好学习能够更精细地控制LLM的生成多样性,避免过度拟合多数意见,从而提升模型在能力和对齐性方面的表现。这种方法本质上是对KL散度正则化的一种改进,使其更加灵活和可控。
关键设计:软偏好学习的关键设计在于损失函数的修改。具体来说,损失函数可以表示为:Loss = -E[reward] + α * CrossEntropy + β * Entropy,其中α和β是可调节的超参数,分别控制交叉熵和熵的权重。通过调整α和β的值,可以控制模型在学习偏好的同时,保持输出的多样性。此外,论文可能还涉及到一些其他的技术细节,例如如何选择合适的奖励函数、如何进行模型训练等,但这些细节在摘要中没有明确提及。
🖼️ 关键图片

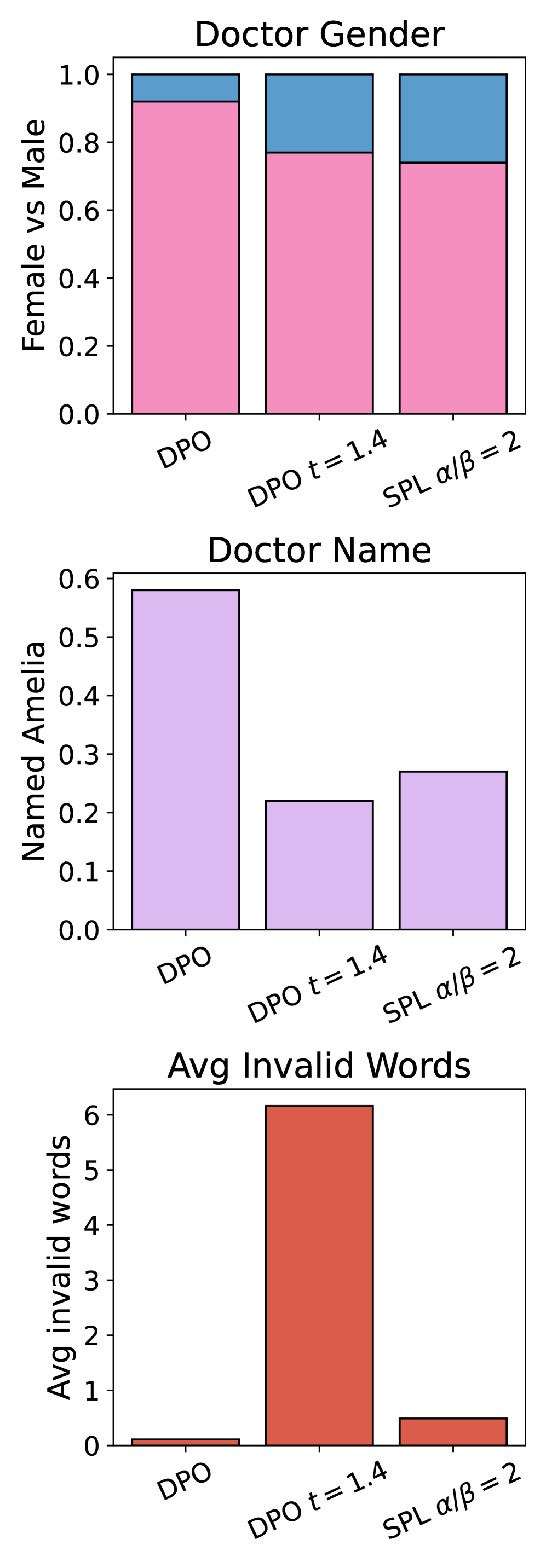
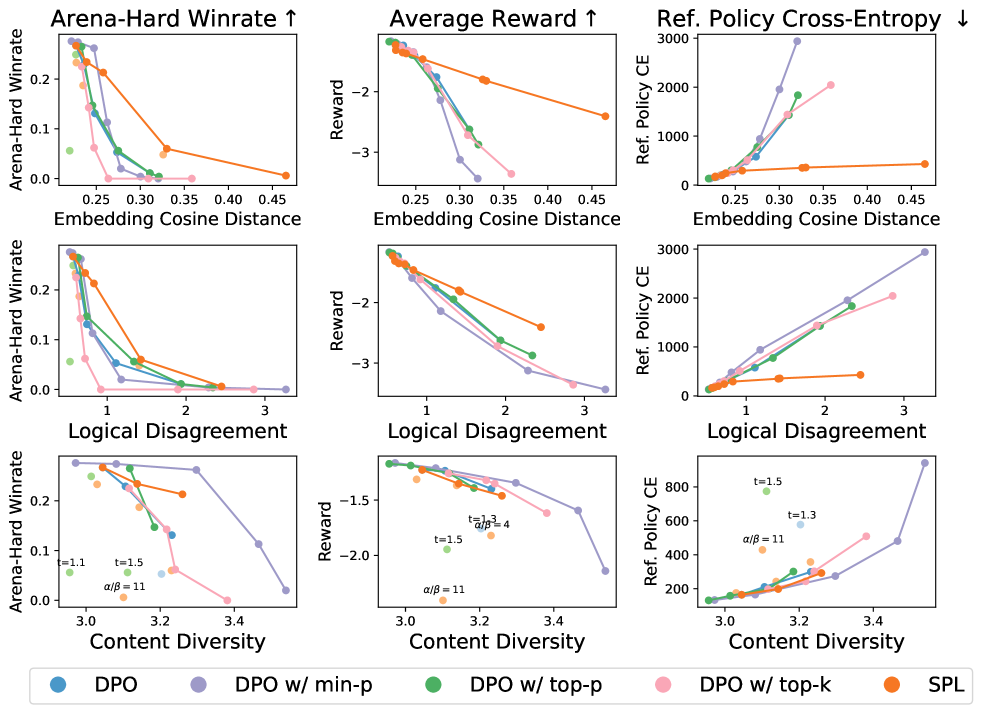
📊 实验亮点
实验结果表明,使用软偏好学习训练的LLM在困难的重复采样任务中获得了更高的准确性,并产生了具有更大语义和词汇多样性的输出。此外,该模型能够代表更广泛的社会观点,并显示出改进的logit校准。软偏好学习在能力和对齐性方面均优于标准温度缩放。
🎯 应用场景
软偏好学习可应用于各种需要LLM生成多样化输出的场景,例如:生成不同风格的文本、模拟不同社会群体的观点、进行头脑风暴等。该方法有助于提升LLM的公平性和包容性,使其能够更好地服务于不同背景的用户。未来,该技术有望被应用于对话系统、内容生成、教育等领域,促进人与AI的和谐共处。
📄 摘要(原文)
The ability of LLMs to represent diverse perspectives is critical as they increasingly impact society. However, recent studies reveal that alignment algorithms such as RLHF and DPO significantly reduce the diversity of LLM outputs. Not only do aligned LLMs generate text with repetitive structure and word choice, they also approach problems in more uniform ways, and their responses reflect a narrower range of societal perspectives. We attribute this problem to the KL divergence regularizer employed in preference learning algorithms. This causes the model to systematically overweight majority opinions and sacrifice diversity in its outputs. To address this, we propose Soft Preference Learning, which decouples the entropy and cross-entropy terms in the KL penalty - allowing for fine-grained control over LLM generation diversity. From a capabilities perspective, LLMs trained using Soft Preference Learning attain higher accuracy on difficult repeated sampling tasks and produce outputs with greater semantic and lexical diversity. From an alignment perspective, they are capable of representing a wider range of societal viewpoints and display improved logit calibration. Notably, Soft Preference Learning resembles, but is a Pareto improvement over, standard temperature scaling.